Mobile-Agent解析
Mobile-Agent解析
近期又出现了一个关于LLM-Agent + RPA的工作,来自北交+阿里,名为MobileAgent。
- 项目地址:MobileAgent Github
- 论文地址:MobileAgent Arxiv

一、简介
此工作所针对的任务目标与上一篇AppAgent介绍的相同,利用多模态大模型能力,完成终端的操作驱动。工作的主要创新:
- 纯视觉的解决方案,不需要XML元素树,以及系统元信息。
- 操作范围不受限制,可进行多应用操作。
- 利用多种CV工具,用于UI操作定位。
- 不需要额外的探索历史和训练,即插即用。
简单介绍图:
二、核心算法
整个架构包含三部分:
- 1.多模态大模型(MLLM GPT-4V)
- 2.OCR模型(for text localization)
- 3.Object Detection+CLIP模型(for icon localization)
多项工作都证明了GPT-4V无法直接有效地输出所预测交互的location,所以目前已有工作都在探索如何使用辅助工具帮助GPT-4V进行交互位置的决策,比如AppAgent利用set-of-mark的方式,将元素ID或区块ID送予GPT-4V让其进行选择,从而完成操作location的映射。
2.1 Text Localization
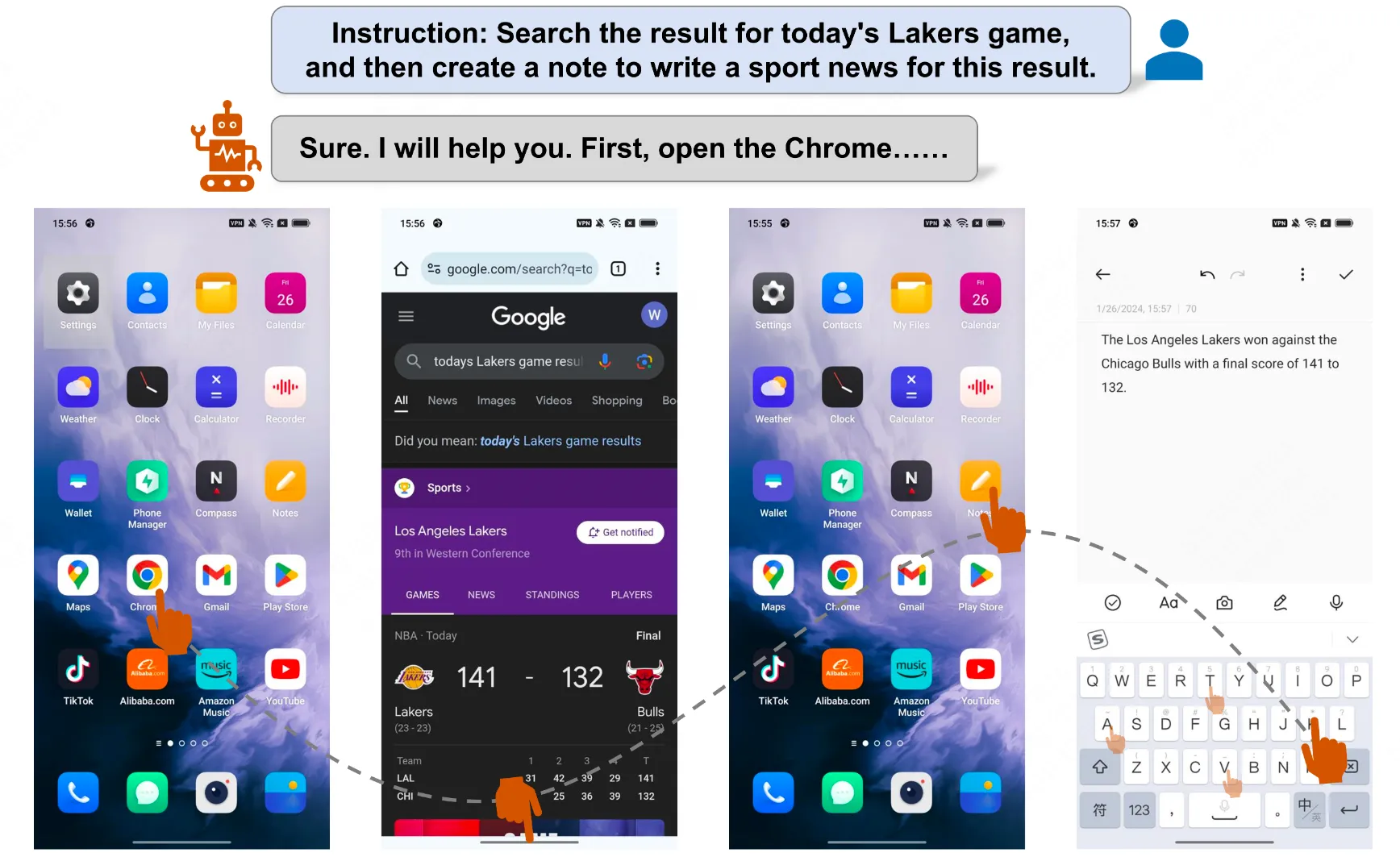
如果Agent需要与某个具体的文字区块进行交互,作者使用OCR进行文字识别,从而得到文字的位置。这里作者列举了三个场景:
- 1.当OCR检测结果不包括指定的文本时,将指示Agent重新选择要点击的文本或直接选择替代的文字。这种情况经常发生在复杂的情况下,GPT-4V可能有少量的幻觉。
- 2.当OCR检测结果只有一个指定文本的实例时,我们直接生成一个操作来单击该文本框的中心坐标。
- 3.当OCR检测结果包括指定文本的多个实例时,我们评估结果的数量。如果有多个实例,则表示当前屏幕上有太多相似的内容,使工程师难以做出选择。在这种情况下,会要求Agent重新选择要点击的文本。如果实例很少,我们会裁剪这些区域并在其上绘制检测框。然后,我们使用这些区域让代理选择要点击的区域。裁剪时,我们将文本检测框向外延伸一定范围,然后在这些裁剪的图像上绘制检测框。这样做是为了保存更多信息并加强Agent的决策过程。
关于第三点,例子如下:
2.2 Icon Localization
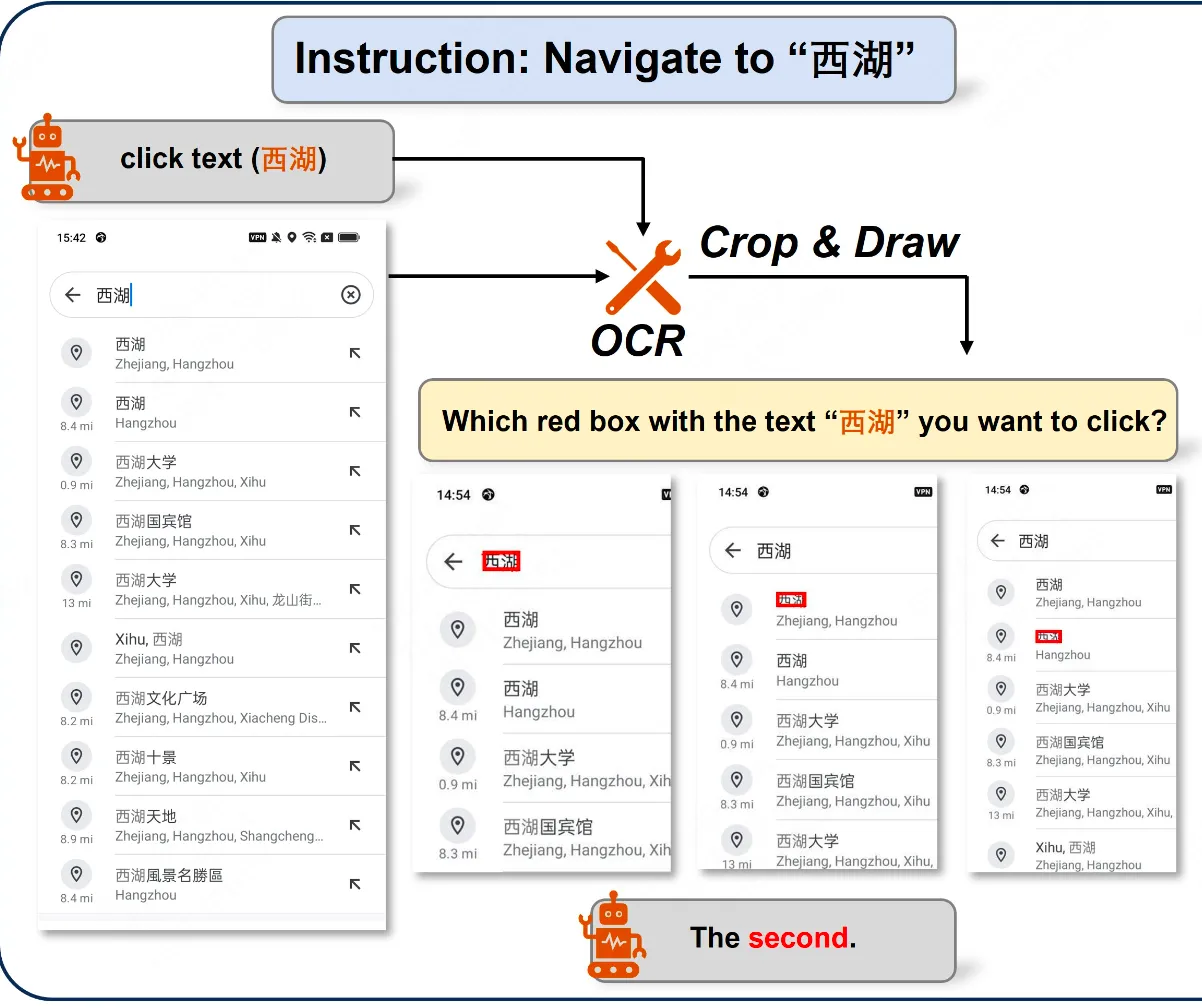
当Agent需要点击一个icon时,作者会利用一个目标检测模型,以及CLIP模型,两者结合完成icon的定位。具体来说,我们会先让Agent提供我们需要点击icon的特征,包括icon的颜色和形状。然后我们使用Grounding DINO抽取出类别为”icon”的objects。最后我们将这些objects以及icon的特征送入CLIP模型,进行图像与文本的匹配,将最相似的icon作为交互的目标。流程如下图:
这里介绍下Grounding DINO
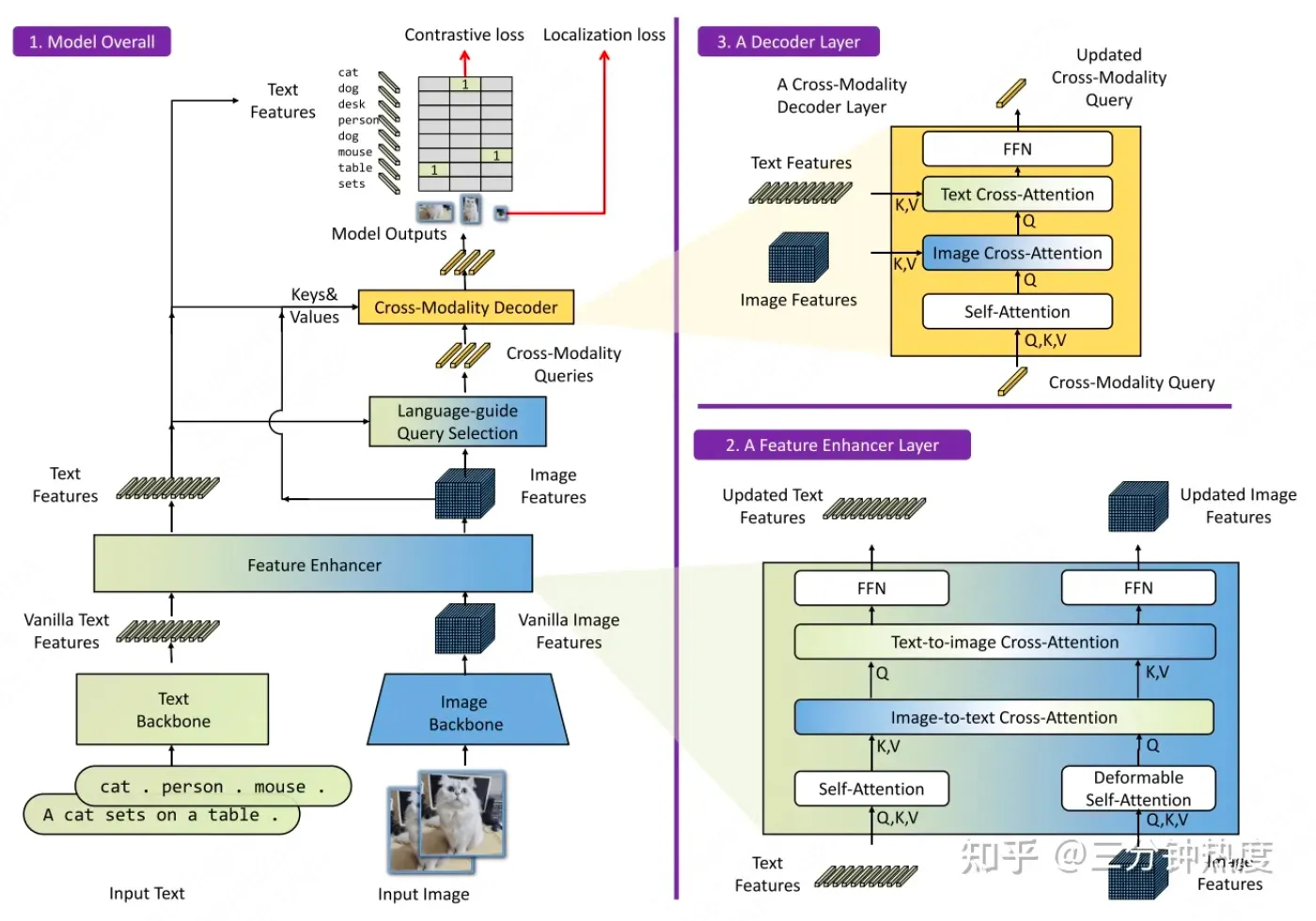
简单来说,Grounding DINO可以根据文字描述检测指定目标,比如我的Prompt为 “icon”,那么它就可以把图像中的所有icon给框定出来,为“开集目标检测”。整体上Grounding DINO为双encoder,单decoder结构,双encoder一个处理文本,一个处理图像,中间一个Feature Enhancer将两种模态数据进行融合,language-guide query selection模块用于query初始化、一个cross-modality decoder用于bbox预测。整体如下图所示:
三、整体流程Prompt
opreation_prompt = '''This is the current screenshot. Please give me the response as requested below.
First, you need to generate the Observation and Thought.
Observation: You need to briefly describe the current screenshot. If there are previous operations, you need to briefly describe the previous operations and the screenshot changes.
Thought: Based on Observation, You need to think about what you need to do next in order to complete the instruction.
Then, you need to generate the action based on the Thought. You can perform the following 8 actions:
1. open App (parameter). Click on the name of an App on your desktop home page. The parameter is the name of App. You can only use this action on the desktop.
2. click text (parameter). The parameter is the text you need to click. If there is text at the click position, use this action in preference.
3. click icon (parameter1, parameter2). The parameter1 is the description of the icon you want to click, please use this template: [color][shape], such as red circle. The parameter2 selected 1 out of 5 from the top, bottom, left, right and center, represents the general location of the icon on the screenshot.
4. page down, page up. These two commands don't need parameter, used for page turning.
5. type (parameter). The parameter is what you want to type. Make sure you have clicked on the input box before typing.
6. back. Back to the previous page.
7. exit. Exit the app and go back to the desktop.
8. stop. If you think you have completed the instruction, then you can stop the whole process.
Note: If you try an action several times and the screen does not change, try using another action.
Finally, your output must follow the following format:
Observation: Generate as required by Observation
Thought: Generate as required by Thought
Action: If the action requires parameters, use (parameter).'''3.1 Operation
作者定义了8种操作让Agent决策:
- Open App (App): Open a specific App on the desktop page.
- Click the text (Text): Click the area of the screen where the text “Text” is located.
- Click the icon (Icon, Position): Click the area described by “Icon” in the “Position”. “Icon” provides a description, including attributes such as color, icon shape, etc., of the tapping location. “Position” needs to be selected from top, bottom, left, right, or center, with one or two options, to minimize the possibility of errors.
- Type (Text): Type the “Text” into the current input box.
- Page up & down: Used for scrolling up and down the current page.
- Back: Return to the last page.
- Exit: Return directly to the desktop from the current page.
- Stop: When the instruction is completed, end the entire process.
3.2 Self-Planning
MobileAgent迭代地完成操作的每一步。在迭代开始之前,用户需要输入一条指令。我们根据指令生成整个流程的系统提示。在每次迭代开始时,我们捕获当前移动屏幕的屏幕快照并将其提供给代理。Agent通过观察系统提示、操作历史记录和当前屏幕截图,输出操作的下一步。如果Agent的输出是结束进程,则迭代将停止;否则,新的迭代将继续。移动代理利用操作历史,感知当前任务的进度,并根据系统提示对当前截图进行操作,从而实现迭代的自我规划过程。
3.2 Self-Reflection
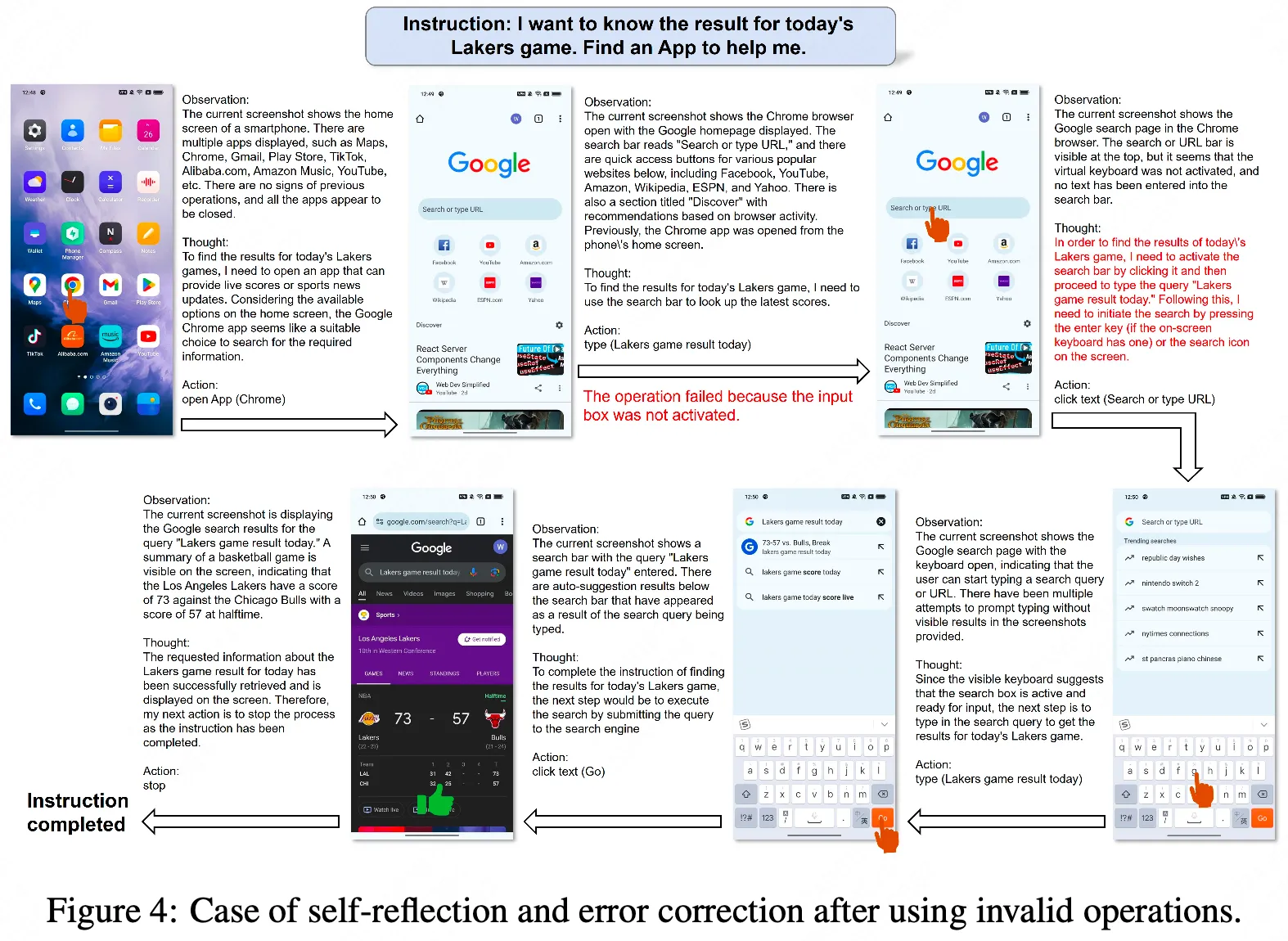
在迭代过程中,Agent可能会遇到错误,导致无法完成指令。为了提高Instruction的成功率,我们引入了反思法。此方法将在两种情况下生效。第一种情况是Agent生成不正确或无效的操作,导致进程停滞。当工程师注意到某个特定操作后截图没有改变,或者截图显示错误的页面时,我们会指示工程师尝试替代操作或修改当前操作的参数。第二种情况是Agent可能忽略复杂指令的某些要求。在Agent通过自我规划完成所有操作后,我们将指示Agent分析操作、历史、当前截图和用户指令,以确定指令是否已完成。如果没有,则Agent需要通过自我规划来继续生成操作。
整体上如下:

四、Experiments
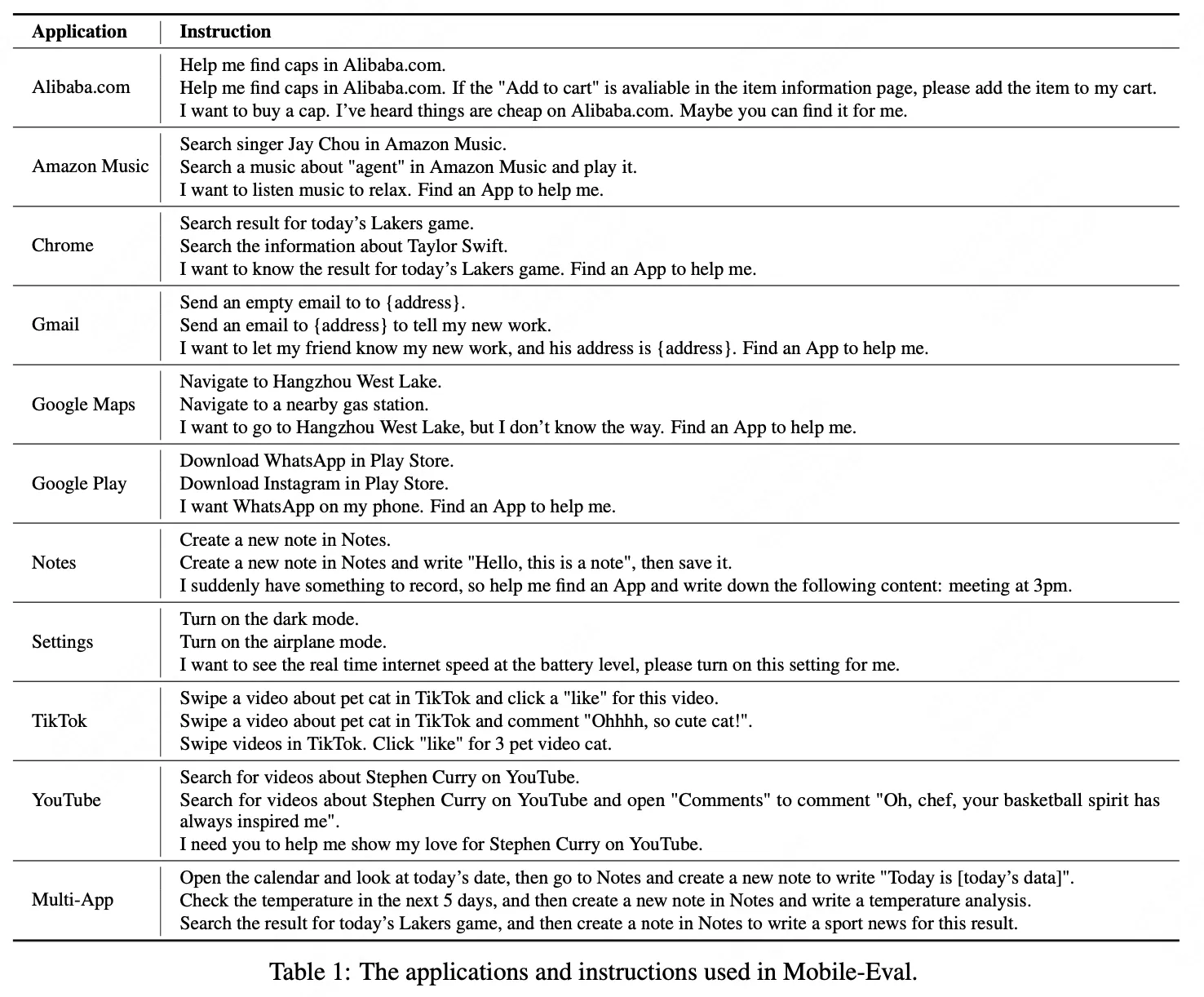
本文提出了一个Benchmark:Mobile-Eval,用于评估当前RPA-Agent的能力。Mobile-Eval由移动设备上的10个常用应用程序组成。为了评估Agent的多应用使用能力,我们还引入了要求同时使用两个APP的Instruction。我们为每个应用程序设计了三个Instruction。第一个指令比较简单,只需要完成App的基本操作。第二个指令在第一个指令的基础上增加了一些额外的要求,使其更具挑战性。第三个指令涉及抽象的用户指令,其中用户没有明确指定使用哪个App或执行什么操作,让Agent做出自己的判断。
作者试了下Mobile-Agent在Mobile-Eval上的效果: