Abstract
Fill in the Blank: Context-aware Automated Text Input Generation for Mobile GUI Testing - ICSE2023
本文介绍了一个生成UI页面需填写内容的工具。
自动化 GUI 测试被广泛用于帮助确保APP质量。但是许多 GUI 需要适当的文本输入才能进入下一页,这仍然是测试覆盖率的一个重要障碍。考虑到有效输入(例如,航班起飞、电影名称)的多样性和语义要求,自动化文本输入生成具有挑战性。受大型语言模型(LLM)在文本生成方面取得显着进步的启发,本文提出了一种基于 LLM 的名为 QTypist 的方法,用于根据 GUI 上下文智能地生成语义输入文本。为了提高 LLM 在GUI测试场景中的性能,本文开发了一种基于Prompt的数据构建和调优方法,该方法可以自动提取Prompt和answers以进行模型调优。本文在 Google Play 的 106 个应用程序上评估 QTypist,结果显示 QTypist 的通过率为 87%,比baseline高93%。我们还将 QTypist 与自动化 GUI 测试工具集成在一起,与原始工具相比,它可以覆盖的app activities(不太明确此activities概念)提升了42%,覆盖的页面增加了52%。
Intro && Motivation
引出了当前移动APP GUI测试的工作,including model based [5], [6], [7], probability based [8], [9], [10] and deep learning based [11], [12] ones to dynamically
explore mobile apps by executing different actions such as scrolling, clicking based on the analysis of code structure of the current page to verify UI functionality,这些工作主要是针对于滑动 / 点击的操作,而没有关注 text input generation。而当前很多测试场景需要填写后进入到下一个页面进行测试覆盖,举了下图例子,需要输入后才能进入其他比如选座 / 查询新闻等页面进行测试:
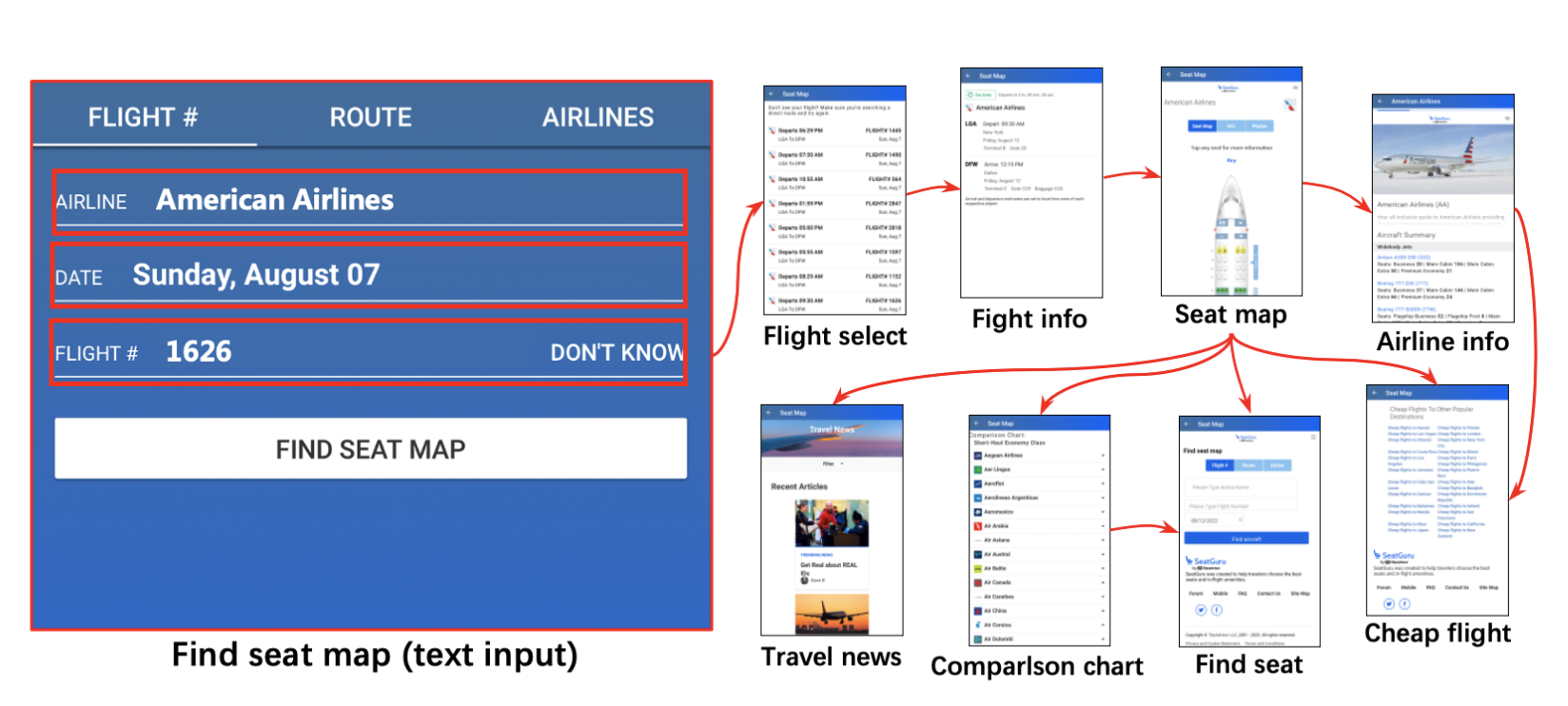
在Intro后半部分首先说明了填空这个任务是比较困难的(even for human),因为不同的input box需要很多专业 / 前验知识,比如健康APP的血压值,编程APP的代码输入等,其次一副页面中前后的输入也是有关联的。当前一些工作主要是进行随机 / 依据规则 / RNN的输入信息生成,这些基本不太可用且有些方法需要大量标注数据,所以本文利用当前Large Language Model(LLM)来帮助实现填空的需求。
本文主要贡献:
- 首个将input generation抽象为nlp完形填空的工作,帮助当前测试工具达到更高的覆盖率
- 提出基于LLM的“pre-train, prompt and predict”范式的 QTypist 新方法,通过了解本地和全局上下文来自动推断语义文本输入
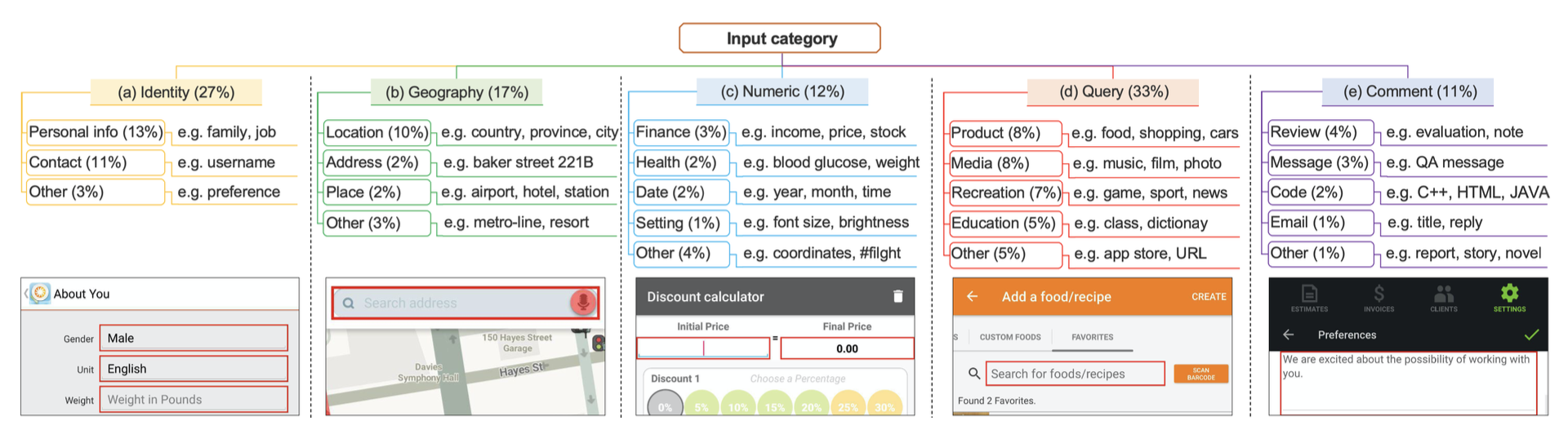
Motivation主要探讨及分析了当前APP 对于信息输入的实际情况,以及简单介绍了LLM,统计了一个图,主要人为统计定义了一些输入框所关联的categories,来阐述输入框的复杂性:
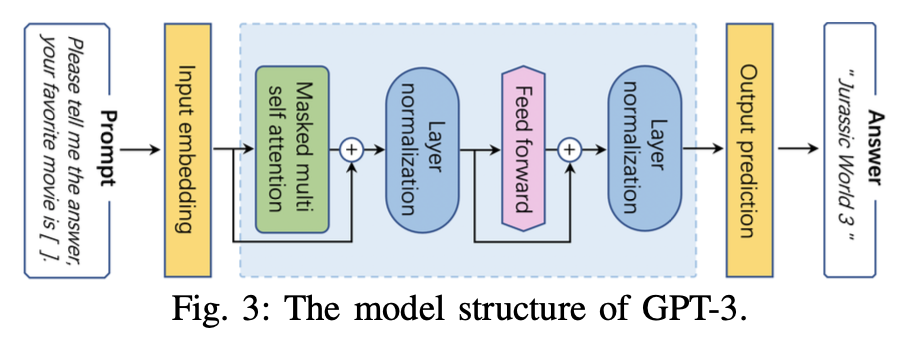
 GPT-3的简单结构图:
GPT-3的简单结构图:
Method
结构图:
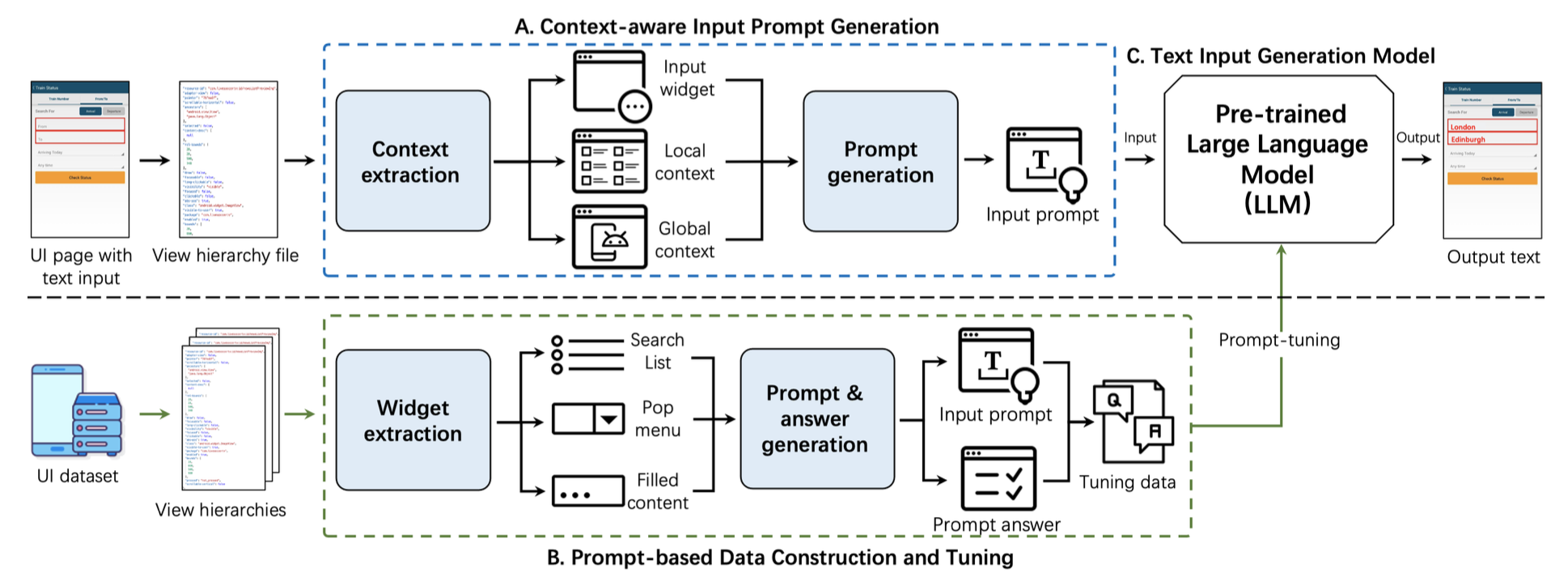
对于图中A部分(Context-aware Input Prompt Generation),整体上,对于一个输入的页面,会先抽取出信息输入的上下文信息,然后根据所设计的模式生成prompts输入LLM。
信息抽取部分(Context extraction):主要使用了元素树(view hierarchy file),整体分三个部分:
- Input widget information:主要是抽取input box的"hint text",“resource-id”,“text"这几个字段
- Local context information:主要是input box周围的元素信息,范围有子节点、父节点、相同纵坐标的节点,信息同样是"hint text”,“resource-id”,“text"这些字段
- Global context information:全局信息,包括页面名称、APP名称、输入框数量
Prompt生成部分(Prompt Generation):主要是根据以上抽取出的信息按照一定的模式生成Prompt
- Preprocessing:通过预处理,将得到的信息进行关键信息抽取,可以理解为关键词提取,包括将信息分为动词(v.)、名词(n.)、介词(prep.)、app name、activity name
- Linguistic patterns of prompt:作者们经过测试和探讨,设计了下图中的prompt生成模式:分为3种数据源,对应上述信息抽取部分的三种信息(input widget / local context / global context),图中使用不同颜色注明。整体作者设计了14种patterns,图中贴了其中7种,主要就是取对应信息源的对应关键信息(n. v. prep.等),来生成prompt语句。
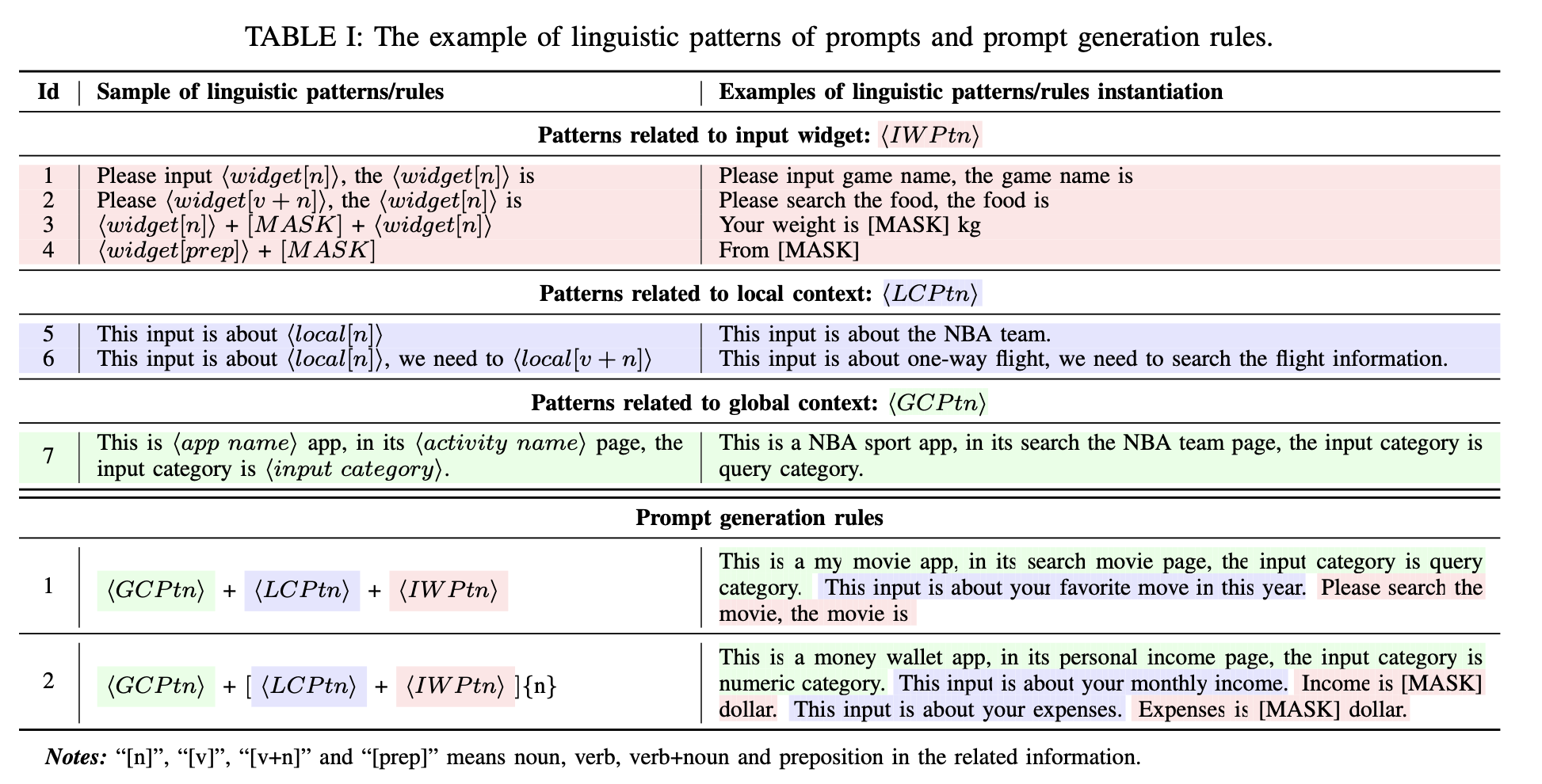
Prompt生成规则部分(Prompt generation rules):最终的prompt会按照上图中下方部分,将三种数据源生成的prompt组合成一个大的prompt,作为LLM的input
结构图中B部分(Prompt-based Data Construction and Tuning):一般的预训练模型很难在特定领域任务上表现优秀,所以常见的做法是进行对应的prompt调优使模型理解当前的prompt语法。但是目前还没有信息输入领域的开放数据集,而且收集数据费时费力,同时,作者注意到一些widgets与input widgets相似,并具有候选或预输入内容(如答案),因此,作者开发了一种方法,利用元素树信息(view hierarchy file)自动构造一个prompt-base的数据集,以调优预训练模型。
那么现成的用来调优的MASK答案是怎么来的呢?作者举了以下三种方式:1.搜索框的下面会有输入的提示,2.下拉框也会有可以填入的信息,3.Rico数据集(当前最大的APP UI测试数据集)有些input box会有对应的填入信息
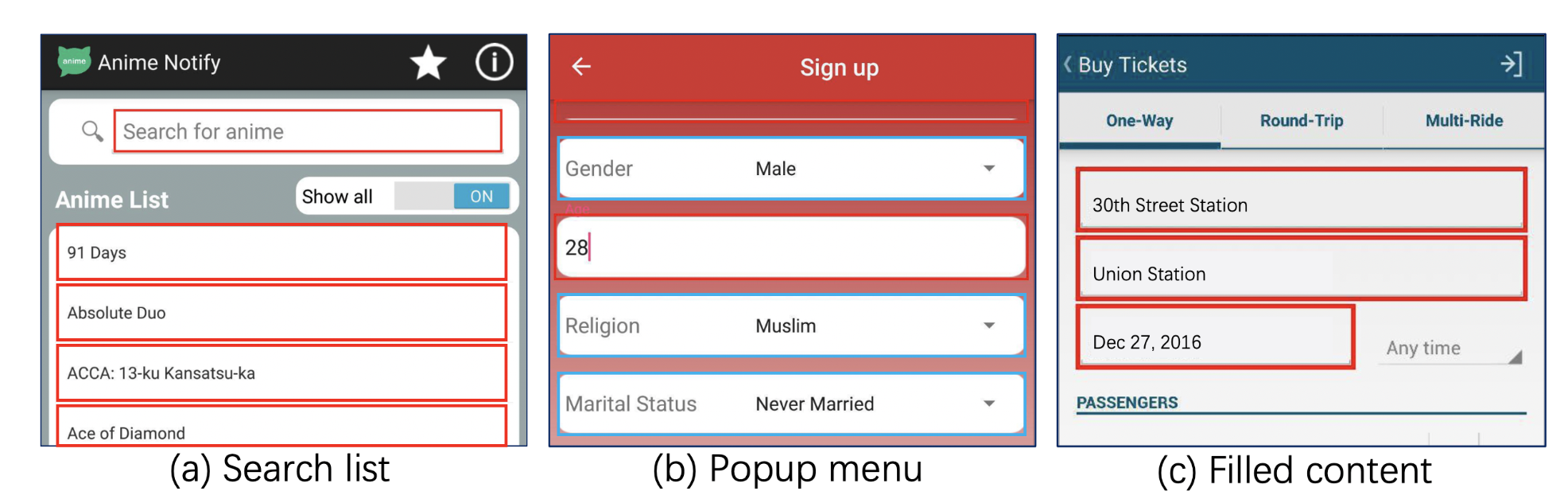 作者简单介绍了这三种信息是怎么去获得的,这里不展开了,在最后的tuning调优阶段,作者使用Table 1中同样的Prompt生成模式,来生成Prompt以及label,从而进行模型的调优。
作者简单介绍了这三种信息是怎么去获得的,这里不展开了,在最后的tuning调优阶段,作者使用Table 1中同样的Prompt生成模式,来生成Prompt以及label,从而进行模型的调优。
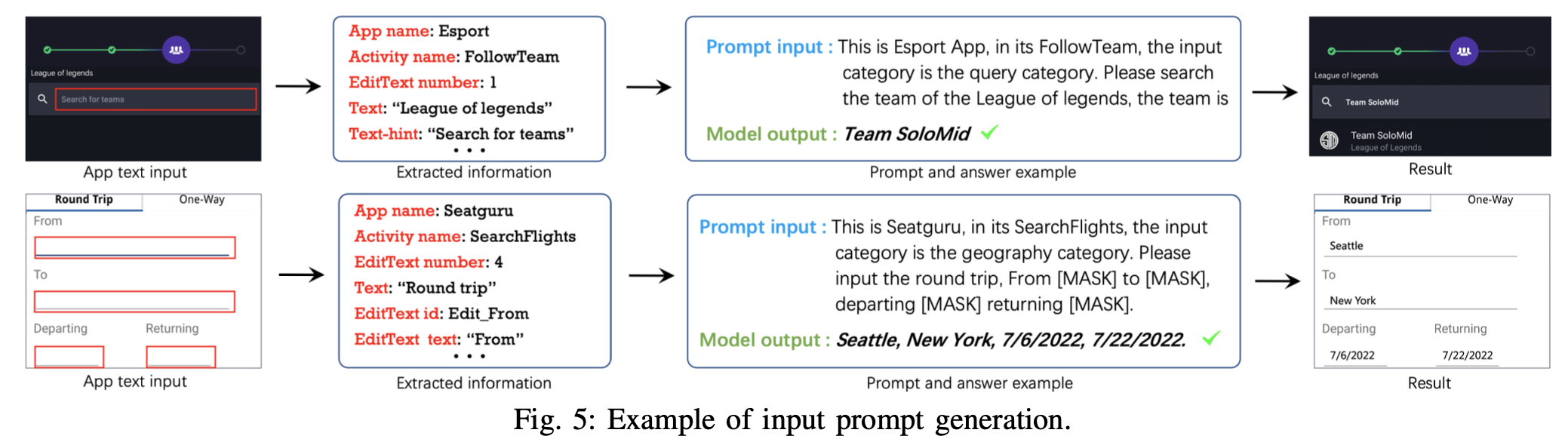
以上就是整体的方法介绍,这里作者也给了整体流程的示意图:
Effectiveness Evaluation
RQ1:当前方法在页面填写及跳转成功的有效性验证 作者找了106个APP的168个填写页面,与其他的自动化工具比较页面通过率(passing rate (passing UI pages requiring text inputs), which is a widely used metric for evaluating GUI testing),如DroidBot / FastBot等。整体结果如下:
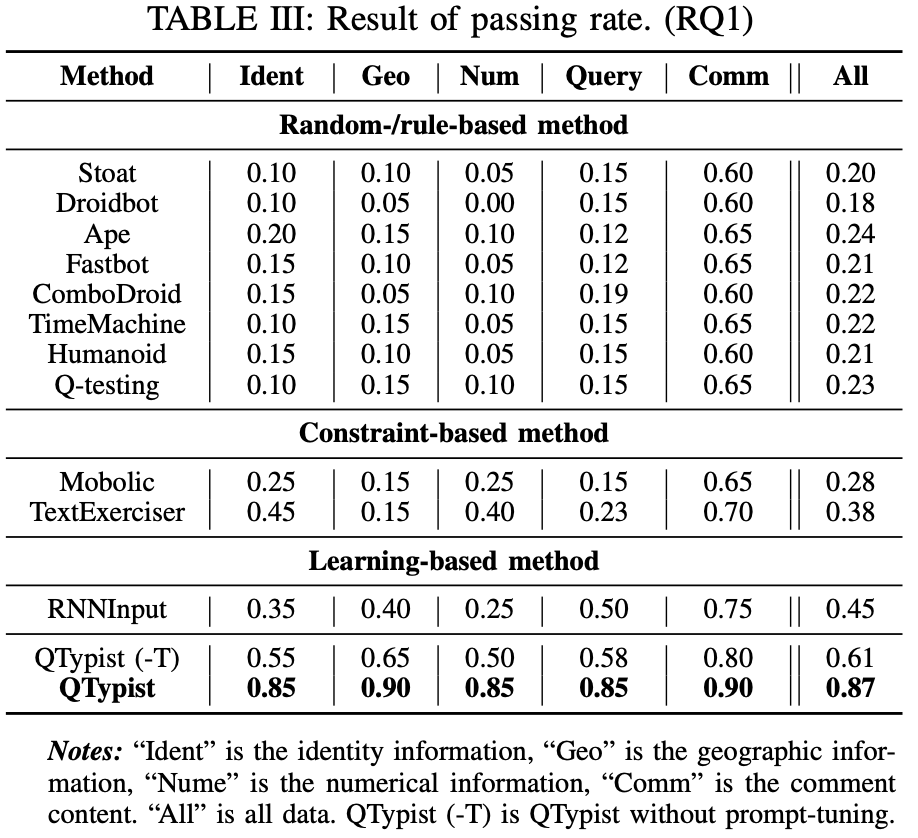
RQ2:当前方法生成输入的质量如何 作者询问了20位testers去人工评估输入的有效性,评估结果如下:
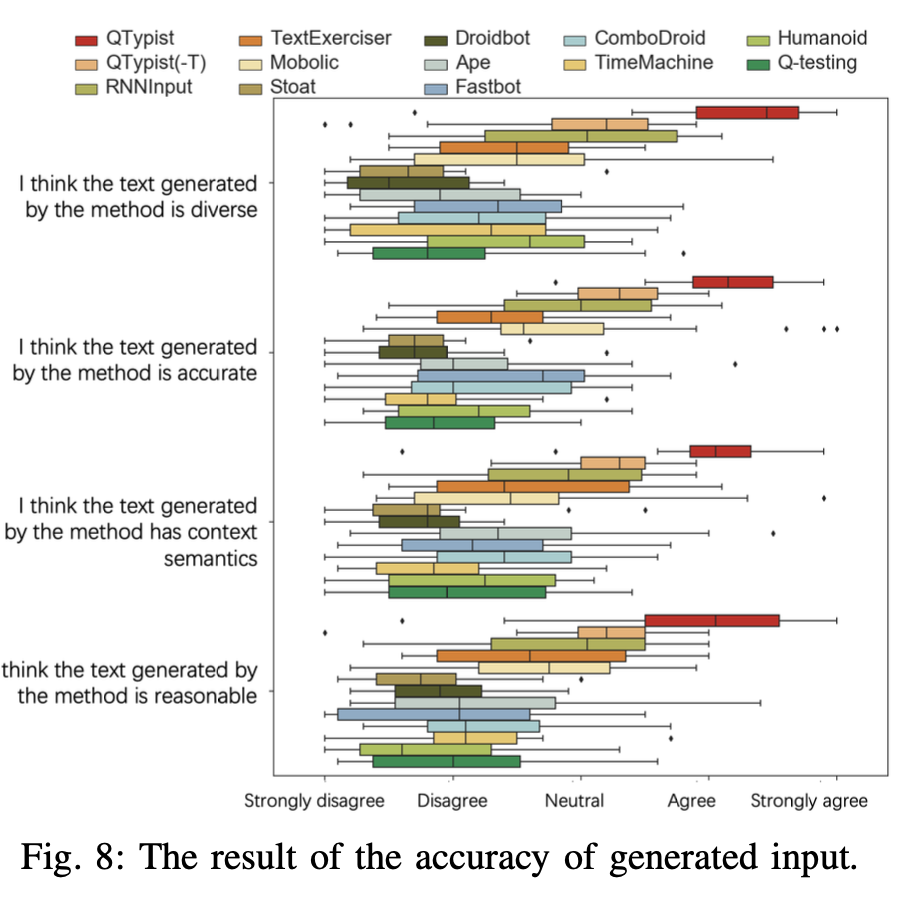
Usefulness Evaluation
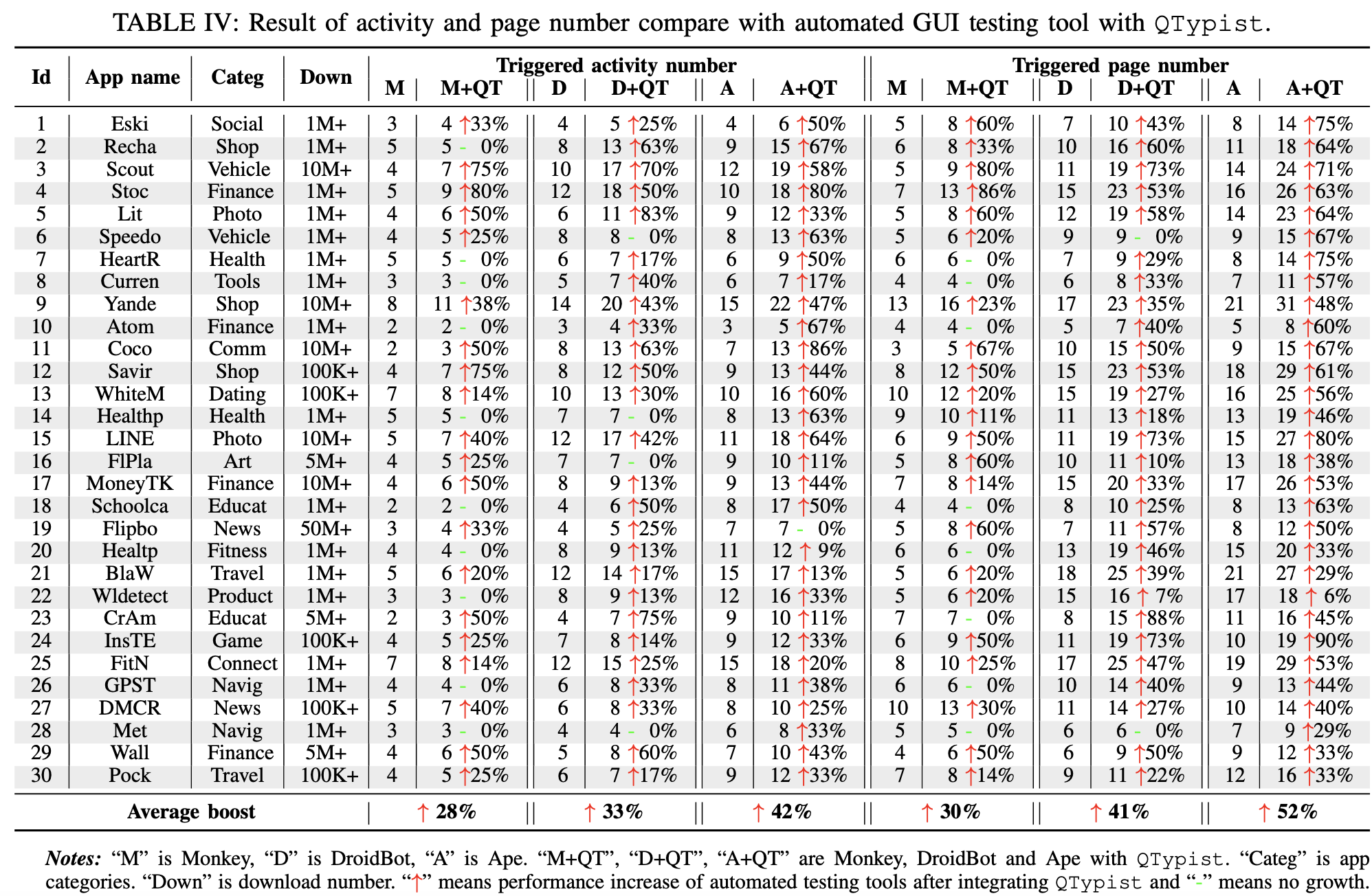
主要实验此工具是否能帮助自动化工具覆盖更多页面以及找到更多bugs。使用了三个遍历工具:Monkey / DroidBot / Ape,找了30个APP,去测试触达的activity和page是否有提升。测试结果如下: