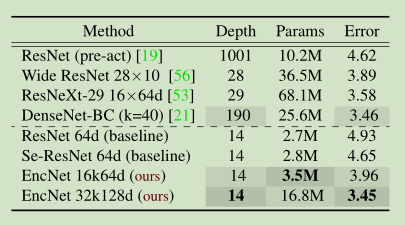
本文提出了上下文编码模块(Context Encoding Module)引入全局上下文信息(global contextual information),用于捕获场景的上下文语义并选择性的突出与类别相关的特征图。 实验证明上下文编码模块能够显著的提升语义分割性能,在Pascal-Context上达到了51.7%mIoU, 在 PASCAL VOC 2012上达到了85.9% mIoU,单模型在ADE20K测试集上达到了0.5567。 此外,论文进一步讨论上下文编码模块在相对浅层的网络中提升特征表示的能力,在CIFAR-10数据集上基于14层的网络达到了3.45%的错误率,和比这个多10倍的层的网络有相当的表现。
EncNet
introduction
扩张卷积存在的问题
先进的语义分割系统通常是基于FCN架构,采用的深度卷积神经网络受益于从不同图片中学习到的丰富的对象类别信息和场景语义。CNN通过堆叠带非线性激活和下采样的卷积层能够捕获带全局接受野的信息表示,为了克服下采样带来的空间分辨率损失,最近的工作使用扩张卷积策略从预训练模型上产生密集预测。然而,此策略依然会将像素从全局场景上下文相隔开,这会导致像素错误分类。
如下图,错误的将窗格分为门。

金字塔结构存在的问题
近期的工作使用基于金字塔多分辨率表示扩大接受野。例如,PSPNet采用的PSP模块将特征图池化为不同尺寸,再做联接上采样;DeepLab采用ASPP模块并行的使用大扩张率卷积扩大接受野。这些方法都有提升,但是这对上下文表示都不够明确,这出现了一个问题: 捕获上下文信息是否等同于增加接受野大小?
考虑到如下情况,在一个大型数据集上,如下图:

如果能够先捕获到图像上下文信息(例如这是卧室),然后,这可以提供许多相关小型目标的信息(例如卧室里面有床、椅子等)。这可以动态的减少搜索区域可能。说白了,这就是加入一个场景的先验知识进去,这样对图片中像素分类更有目的性。依照这个思路,可以设计一种方法,充分利用场景上下文和存在类别概率的之间的强相关性,这样语义分割会就容易很多。 能否利用经典方法的上下文编码结合深度学习? 最近有工作在CNN框架中推广传统编码器方法获得了极大的进步,在本文中,使用扩展编码层来捕获全局特征的统计信息用于理解上下文语义。
contribution
第一个贡献:
引入了上下文编码模块,该单元用于捕获全局场景上下文信息和选择性的突出与类别相关的特征图。 集成了语义编码损失(Semantic Encoding Loss,SE-loss)。 举例来讲,不考虑车辆出现在卧室的可能性,在现有标准的训练过程使用的是像素分割损失,这不强调场景的全局信息。引入语义编码损失(SE-loss)可进一步规范网络训练,让网络预测能够预测场景中对象类别的存在,强化网络学习上下文语义。 与逐像素的损失不同,SE-Loss对于大小不同的物体有相同的贡献,在实践中这能够改善识别小物体的表现。
第二个贡献:
设计了一个新的语义分割架构Context Encoding Network (EncNet)。如下图所示,EncNet通过上下文编码模块增强了预训练的ResNet:
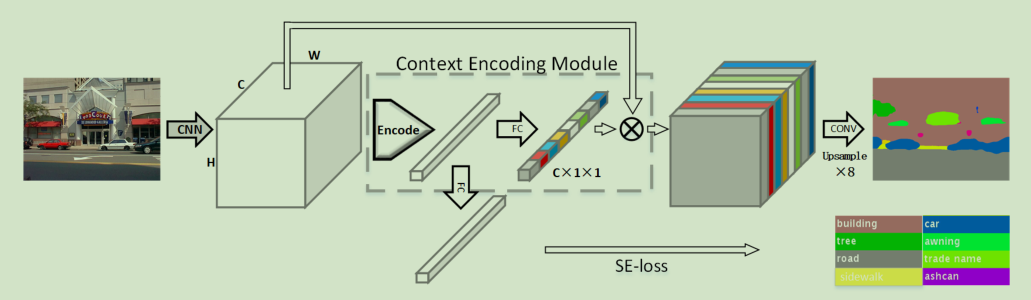
Context Encoding:
对于预训练网络,使用编码层捕获特征图的统计信息作为全局上下文语义,将编码层的输出作为编码语义(encoded semantics),为了使用上下文,预测了一组放缩因子(scaling factors)用于突出和类别相关的特征图。编码层学习带有上下文语义的固有字典,输出丰富上下文信息的残差编码。
Input feature: CXWXH —>x={x1,x2,…,xN},N=H×W
Inherent codebook: D={d1,d2,…,dk}
Scaling factors: S={s1,s2,…,sk}
最后会输出k个残差编码,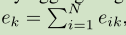
这样做的目的是什么呢?
通过将图像的HXW个C维特征,每一个都与语义词dk做差,然后和所有语义词做差的结果相加进行归一化,获得一个像素位置相对于某个语义词的信息eik,然后将这N个结果求和加在一块获得最终的ek,获得整张图像相对于第k个语义词的信息。
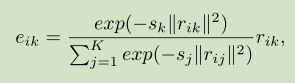
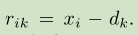
ek是C维的,最后将k个ek融合到一起,这里没有用concat,一方面concat包含了顺序信息,另一方面用加的方法节省了显存。这里加起来的含义是获得整张图像相对于K个语义词的全部信息 ,最后的e也是c维的。
Featuremap Attention: 为了使用编码层捕获的编码语义,预测一组特征图的放缩因子作为循环用于突出需要强调的类别。这样的方法受SE-Net等工作的启发,即考虑强调天空出现飞机,不强调出现车辆的可能性。
Semantic Encoding Loss: 使用Semantic Encoding Loss (SE-loss)在添加少量额外计算消耗的情况下强制网络理解全局语义信息。不同于逐像素损失,SE loss 对于大小不同的目标有相同的贡献,这能够提升小目标的检测性能。
实验结果
Results on PASCAL-Context:

Results on ADE20K:
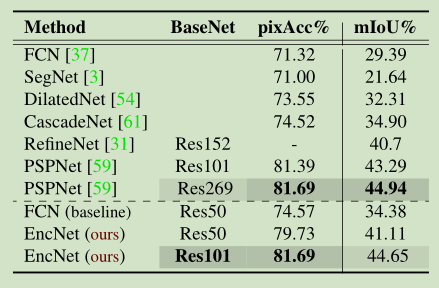
Image Classification Results on CIFAR10: