把动作校验做进像素里:VisCritic 用截图对比给 GUI Agent 当过程裁判
解析 VisCritic(ECCV 2026 投稿):它不改 agent,而是拿一个 Siamese ViT 直接对比动作前后两张截图,判断这一步成没成、错在哪、进度到哪。对 APP 自动化测试来说,这正好切中一个老问题——每一步操作的 oracle 到底该怎么设,以及为什么纯文本断言看不懂界面的视觉变化。
论文:VisCritic: Visual State Comparison as Process Reward for GUI Agents arXiv:
2606.24525v1,2026-06-23(ECCV 2026 投稿,17 页,4 figures) 作者:Jiachen Qian 等 一句话结论:VisCritic 把 GUI Agent 的“这一步动作成没成”从文本推理挪回到视觉本身——用一个共享权重的 ViT 直接比较动作前后两张截图,输出成功概率、进度分和错误类型。它真正推进的不是又一个榜单成绩,而是把“步级校验”做成了一个和界面变化同模态、可即插即用、不用重训 agent 的独立模块。对做 APP 自动化测试的人,这篇最值钱的一点是:它把“每一步的 oracle 该看什么”这个一直靠人拍脑袋的问题,落成了一个可训练、可评估的视觉判别任务。
大多数 GUI Agent 论文在比“谁能把任务做完”。VisCritic 关心的是另一件更靠工程的事:agent 点完一下之后,有没有一个机制去确认这一步真的产生了预期的界面变化。现在多数屏幕型 agent 是单次预测动作、点完就往下走,根本没有步级校验。一步点歪了,它并不知道,只会带着一个错误的前提继续往下,最后整条任务崩掉。
这个缺口对自动化测试的人其实很熟。一条 UI 自动化用例挂掉时,我们最想先分清的是:它是没点中目标、点了但界面没反应、还是点到别的元素弹出了意料之外的东西。传统断言只会在流程末尾告诉你“没到目标页”,中间每一步是对是错、错在哪一类,基本是黑盒。VisCritic 给的三元输出——成功概率、进度分、错误类型——恰好就是测试里一直缺的“步级 oracle”。
这篇论文在 GUIAgent 谱系里的位置
放到 OSWorld / AndroidWorld / VisualWebArena / Mind2Web 这条评测线里,VisCritic 不是再造一个环境,也不是又训一个更强的执行 agent。它站在这些环境之上,做的是过程奖励(process reward)这一层的活。
和它最近的一批工作是文本型 PRM:GUI-PRA、Web-Shepherd、GUI-Shepherd、ADMIRE 这些。作者的判断很直接——这些方法的校验信号本质上都是文本中介的:靠文字描述预期状态、靠工具调用、靠结构化的 checklist。但 GUI 交互的结果是像素级的:一个按钮变色、一个弹窗出现、一个页面滚动露出新内容。用文本去描述这类变化,天然隔了一层。
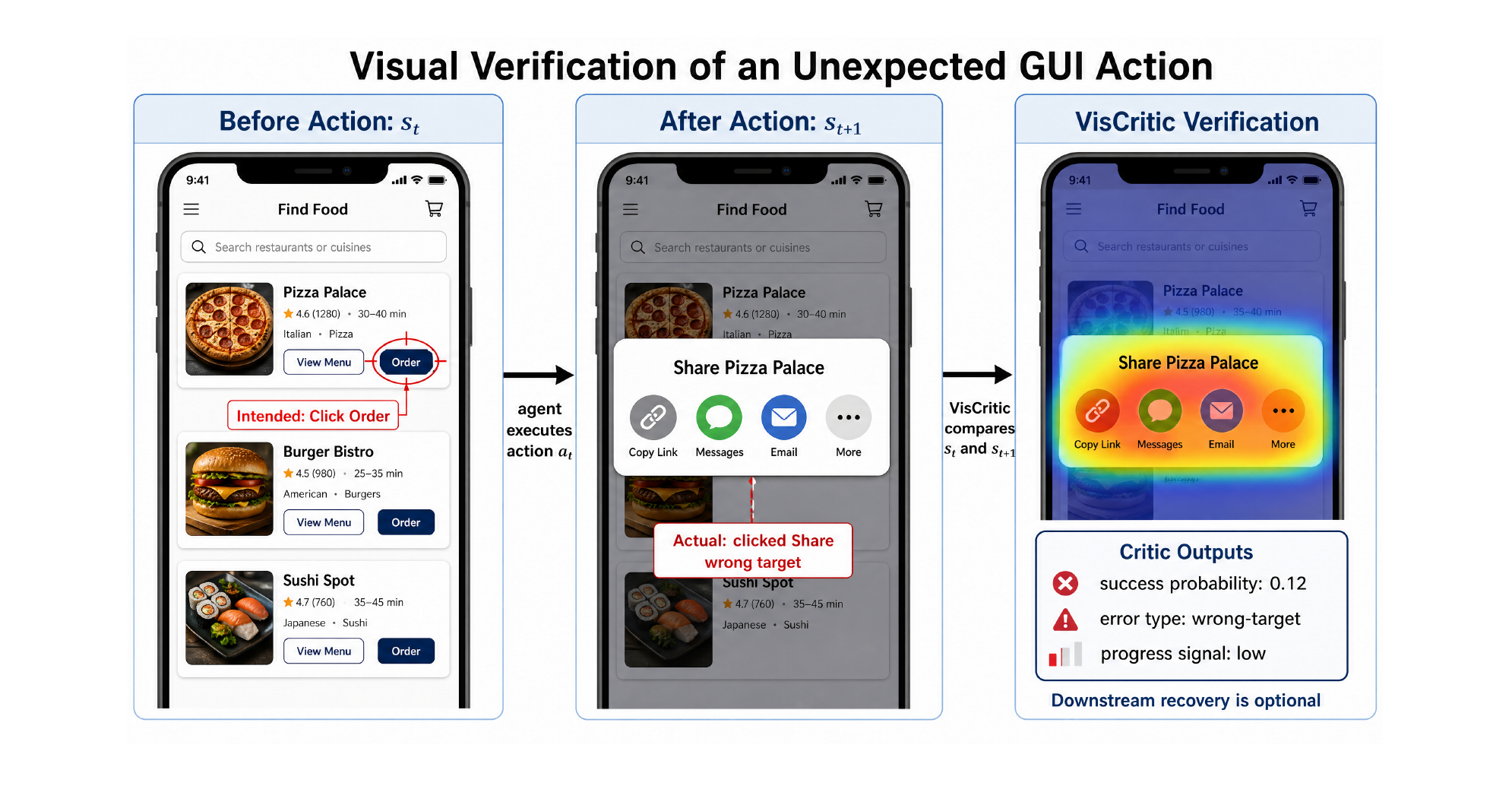
图 1 是论文的立论场景,也几乎是每个写过 App 自动化用例的人都踩过的坑:脚本以为点中了下单按钮,实际点到了旁边的分享,弹出一个分享面板。没有校验,agent(或者你的用例)就带着“已下单”的假设继续跑,后面全错。VisCritic 的做法是把动作前后两帧拿来比,注意力自动落到那个不该出现的弹窗上,然后判定这一步失败、类型是“点错目标”。
核心思路:用视觉差异当奖励信号
VisCritic 的定义很干净。它是一个函数 C : (s_t, a_t, s_{t+1}, l) → (ŷ_suc, ŷ_prog, ŷ_err):吃进动作前截图 s_t、动作后截图 s_{t+1}、执行的动作 a_t 和任务指令 l,吐出三样东西:
ŷ_suc ∈ [0,1]:动作成功概率;ŷ_prog ∈ [-1,1]:任务进度分;ŷ_err ∈ {success, no-op, wrong-target, page-error, timeout}:错误类型。
当 ŷ_suc 低于阈值 γ(默认 0.5)时,可以把结果交给下游的恢复策略——重试、回退、或者请求一段文字纠错建议。注意作者在这里很克制:恢复策略本身没有单独评估,所有对比设置共用同一个固定的 retry/recovery 钩子,所以后面看到的任务成功率提升,应该理解成“在这个固定接入协议下、校验信号带来的收益”,而不是恢复策略设计的功劳。这种把变量框住的写法,比很多论文诚实。
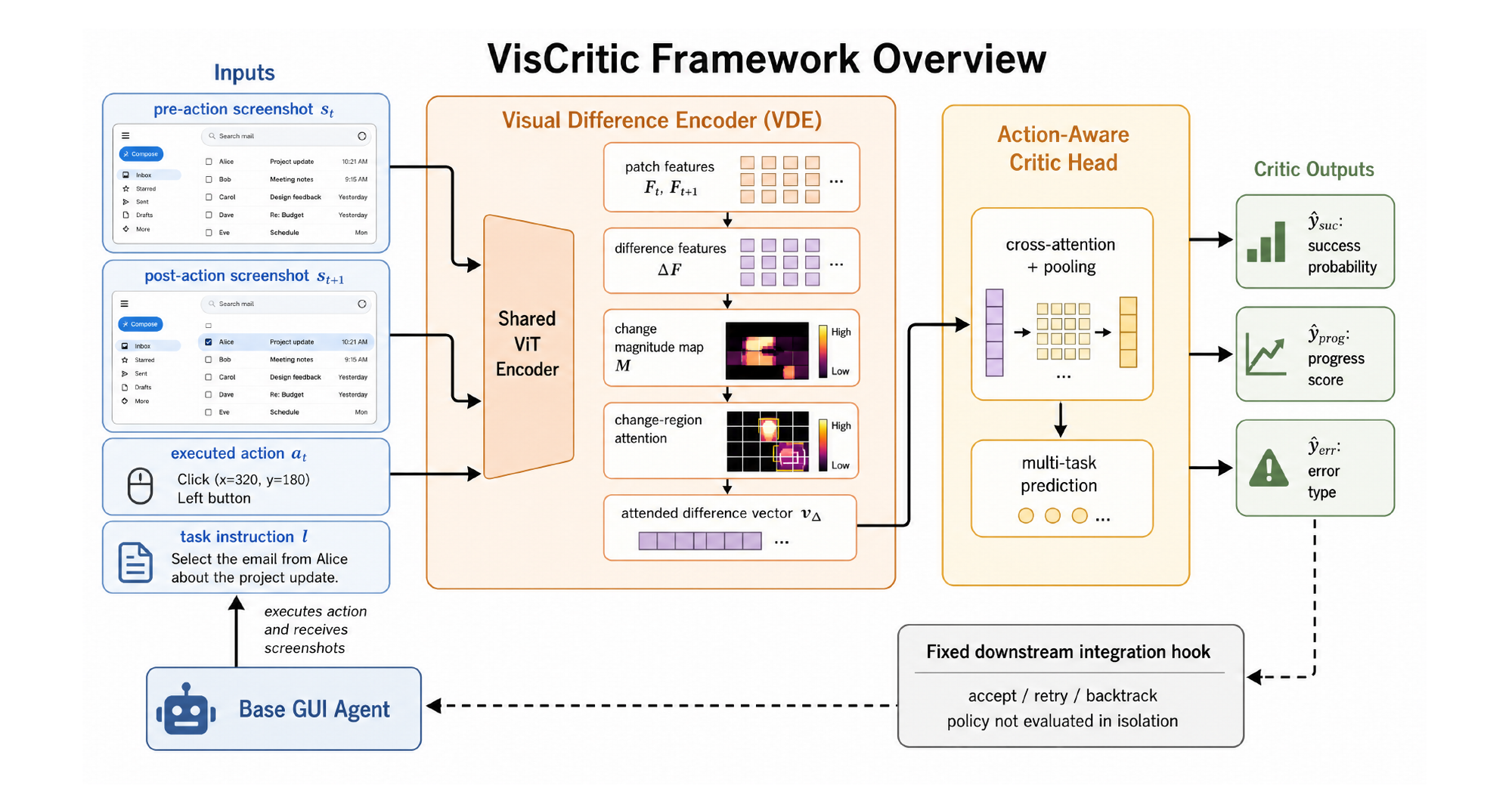
方法拆解:Siamese 差异编码 + 多任务裁判头
整套系统就两块,图 2 已经画得很清楚。
Visual Difference Encoder(VDE) 是核心。它不做像素级相减——那玩意儿对渲染噪声、动画、轻微布局抖动太敏感了。它在学出来的语义特征空间里做差:
- 一个共享权重的 ViT 分别编码
s_t和s_{t+1},得到 patch 级特征F_t、F_{t+1}(Siamese 结构保证两帧落在同一特征空间,才可比); - 算 patch 级差异
ΔF = F_{t+1} − F_t,再算每个 patch 的变化幅度M_i = ‖ΔF_i‖; - 用一个带可学温度 β 的 softmax 把注意力压到变化大的区域上,加权得到差异向量
v_Δ。
Action-Aware Critic Head 把 v_Δ 和动作、指令的文本编码融合,多任务预测那三个输出。多任务这里有个细节值得注意:后面消融会看到,成功预测这个目标其实是主导的,进度和错误类型更像是有益的辅助任务,而不是各自都很强。
这套设计对测试工程的启发很直接:判断一步操作有没有生效,别去做整屏像素 diff。整屏 diff 在真实 App 上几乎没法用——广告轮播、骨架屏、异步加载、动画过渡,随便一个都能让像素差爆表却毫无意义。VisCritic 用语义特征空间 + 变化区域注意力去过滤这些噪声,思路和视觉测试里“忽略动态区域、只比关心区域”是一脉相承的,只是它把“关心哪块”从人工圈定改成了学出来。
训练数据:不用额外人工标注,从已有轨迹里造样本
这是我认为工程上最可复用的一块。VisCritic 的裁判训练数据是从已有 GUI 轨迹数据集里自动构造的,不需要为裁判额外雇人打标。图 3 把五类样本讲得很清楚。
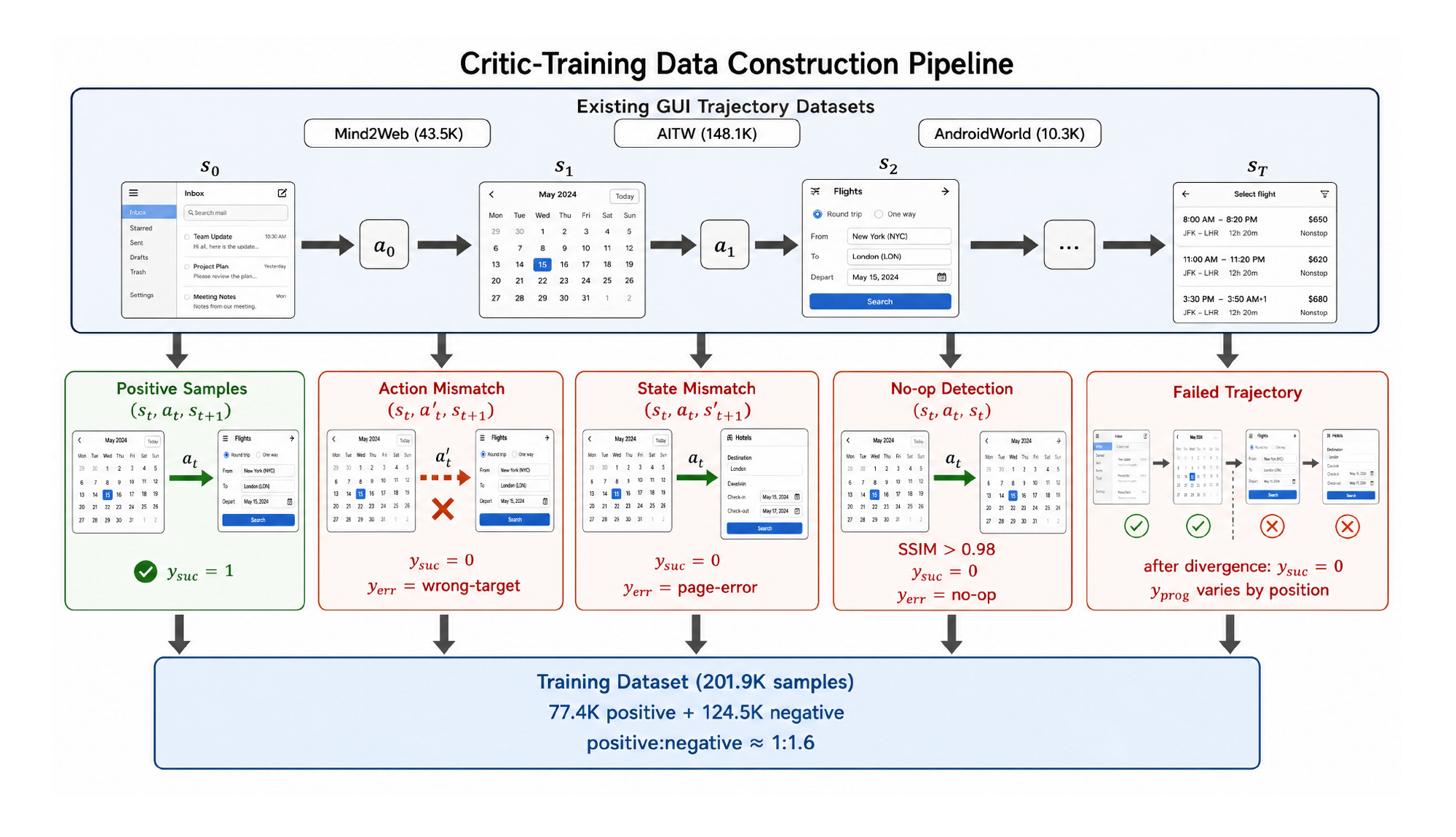
- 正样本:成功轨迹里连续的
(s_t, a_t, s_{t+1}),弱标y_suc = 1; - 负样本靠四种扰动造:
- 动作错配:保留前后帧,把
a_t换成同轨迹里的另一个动作——制造“视觉变化对不上动作描述”的例子; - 状态错配:把
s_{t+1}换成别的轨迹的截图——制造“结果出乎意料”的例子; - no-op 检测:让
s_{t+1} ≈ s_t(SSIM > 0.98)——训练识别“点了没反应”; - 失败轨迹采样:从失败轨迹里取样,分歧点之后的步弱标为
y_suc = 0,分歧点靠和最接近的成功轨迹对齐来估。
- 动作错配:保留前后帧,把
错误类型标签直接由扰动策略确定(和 500 个人工标注案例的一致率 81.4%),进度分是轨迹派生的启发式(成功步 y_prog = (t+1)/T,失败分歧点后给负值)。
这套“从现有轨迹里合成正负样本”的思路,测试团队可以直接借鉴。我们手里通常已经有大量历史执行轨迹——通过的、失败的、卡住的。用类似的扰动策略(动作替换、结果替换、SSIM 判 no-op、失败轨迹分歧点估计),完全可以自造一个“步级判别”的训练/评测集,而不必先去堆一批人工逐步标注。当然要留个心眼:作者自己也承认这套弱标有噪声,尤其分歧点估计依赖轨迹对齐,可能引入错标——工程里用之前最好先抽样核一下标签质量。
实验结果:即插即用,且视觉校验普遍强过文本校验
VisCritic 用 InternViT-6B(LoRA)+ Qwen2.5-7B 文本骨干,约 202K 训练样本来自 Mind2Web、AITW、AndroidWorld。OSWorld 和 WebArena 不在训练集里,是零样本跨基准(对 OSWorld 还是跨平台到桌面)。
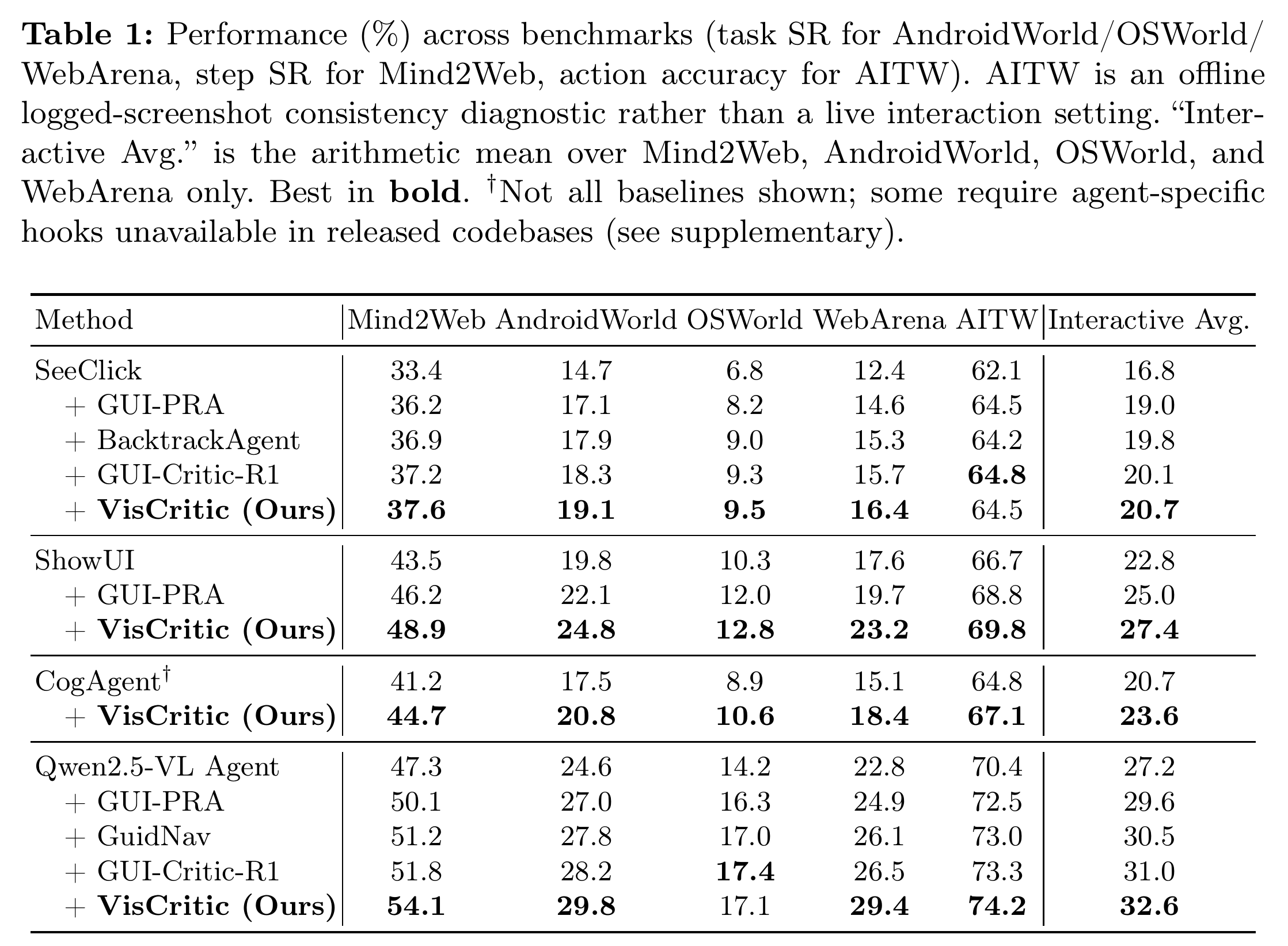
表 1 有几点值得看:
- 即插即用是真的:同一个 VisCritic 训一次,直接接到四个架构不同的 agent 上,多数交互设置都涨。Qwen2.5-VL 交互均值 +5.4 分,ShowUI +4.6 分,CogAgent 因为双编码器架构接入受限只 +2.9 分——提升和基座能力大致正相关,但不严格单调。
- 提升在 web 基准上最明显(WebArena、Mind2Web),作者的解释是这些场景里错误累积最严重,步级视觉校验的价值最大。这个解释合理,但也提醒我们:在错误不那么累积、单步就能验完的短流程上,这套东西的边际收益会小。
- 有一个反例很诚实地写了出来:Qwen2.5-VL 在 OSWorld 上,文本裁判略微反超——文本密集的桌面环境里,文本校验本来就有天然优势。
再看裁判本身的判别质量,这才是对测试更直接的指标。
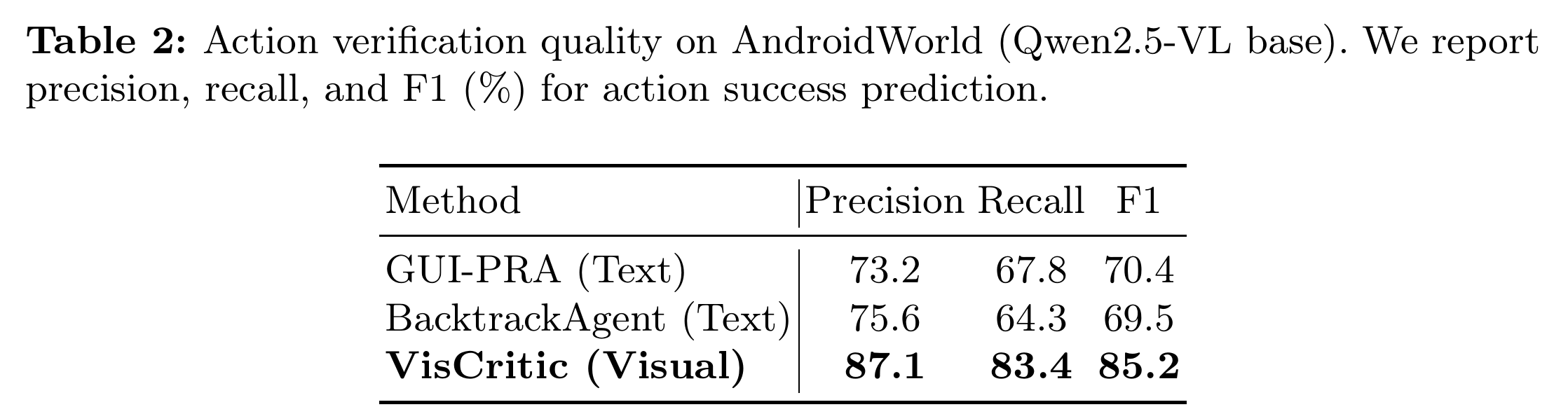
VisCritic 判“这步成没成”的 F1 是 85.2%,比两个文本基线高出近 15 个点。要把它当成测试里的自动断言,这个准确率还够不上无人值守的程度,但作为“先自动筛一轮、把可疑步顶到人工复核”的过滤器,已经很有用了。
真正说明问题的是下面这张按动作类别拆开的对比。
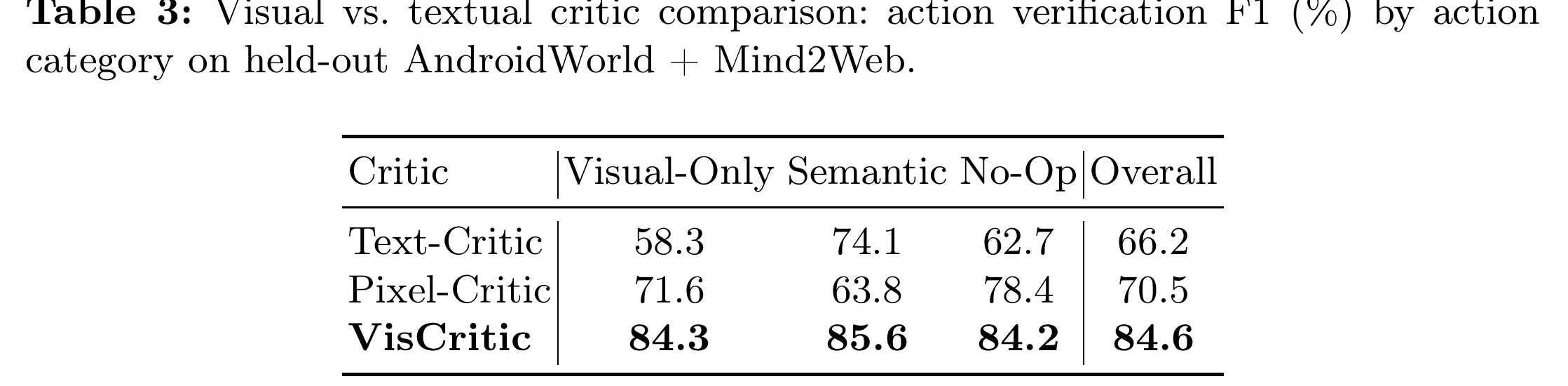
表 3 把“为什么要用视觉”讲透了:
- 纯视觉变化(按钮高亮、图标状态切换、颜色过渡)这类难以用文字描述的变化,文本裁判只有 58.3% F1,VisCritic 84.3%;
- 语义变化(页面跳转、内容加载)这类像素差很大但没啥信息量的,像素裁判只有 63.8%,VisCritic 85.6%;
- no-op 检测(点了没反应),VisCritic 84.2%,文本裁判 62.7%——no-op 在特征空间里是一个很干净的“几乎无变化”模式,视觉一眼就能看出来,用文字反而很别扭。
这三行基本可以当成一份“断言选型指南”:判 UI 微观状态变化(选中态、开关、加载态),别用文本断言,视觉更靠谱;判页面级跳转,别用整屏像素 diff,语义特征更靠谱。
消融也印证了每块的价值:

表 4 里我最在意两条:一是用像素 diff 替换 VDE 掉 3.6 分,直接证明“学出来的语义差异”确实比原始像素差有用,原始像素对渲染噪声太敏感;二是多任务头只贡献 0.7 分——意味着进度分和错误类型这两个辅助输出,对最终任务成功率的直接帮助有限,它们的价值更多在“可解释/可诊断”,而不是把 agent 拉高。这点如果落到工程里要拎清楚:错误类型是给人看的归因线索,不要指望它自己去把成功率抬多少。
可解释性:注意力图能当失败归因的线索
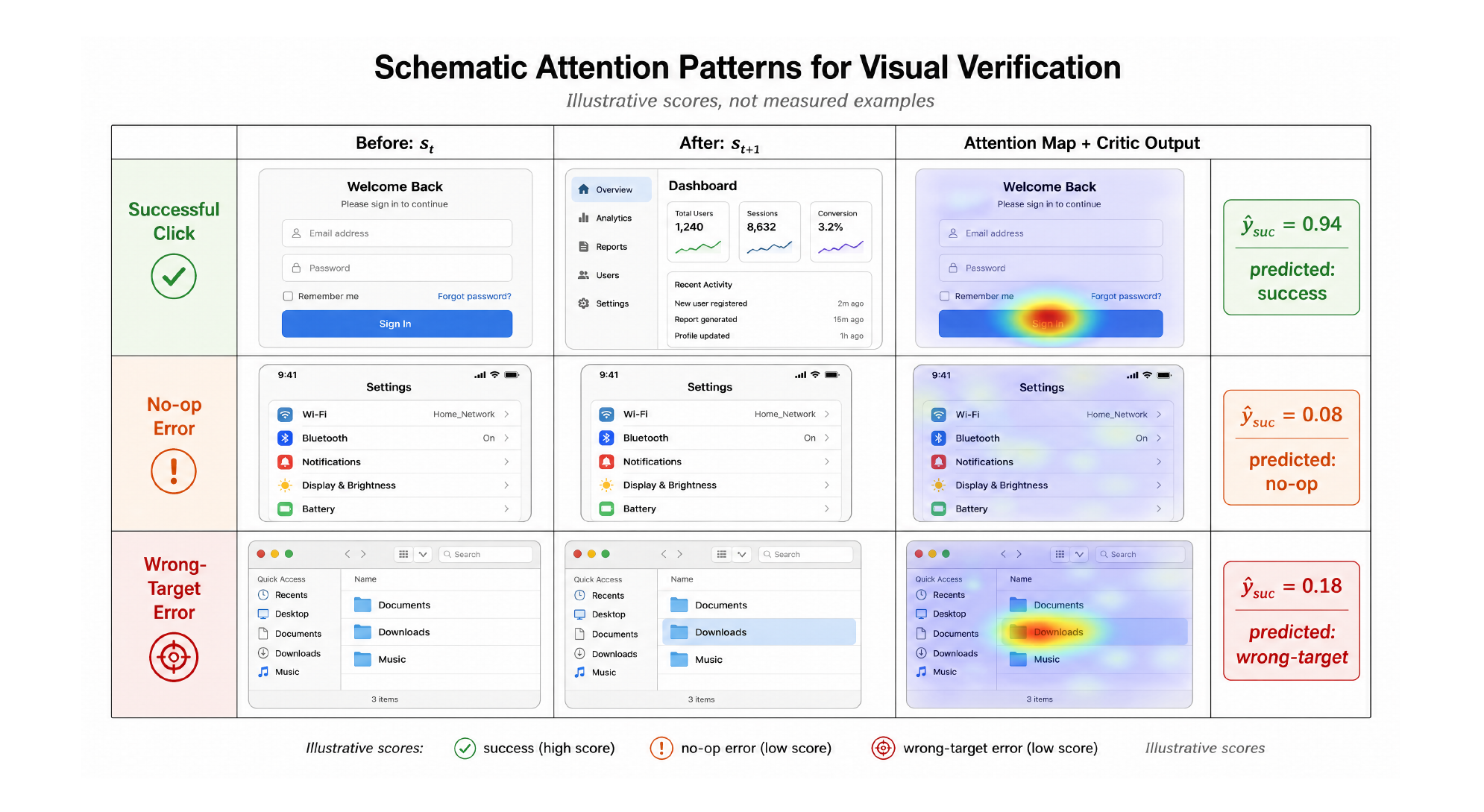
图 4 展示了三种可判读的注意力模式:成功点击注意力聚焦在被点元素、no-op 时弥散、点错目标时落在意外变化区。要说明的是作者明确标了这是示意图不是实测样本,所以别把具体数值当结论。但这个方向对测试很有价值——失败时不光给一个“失败”的布尔值,还给一张“模型觉得哪里变了”的热力图,等于把失败归因从“猜”变成“有视觉证据可看”。开销上,后执行校验每步只加 66ms(A100 上约 15.7% 开销),相比 1–3s 的环境交互延迟基本可忽略;资源紧张时换 SigLIP-400M 骨干能降到 35ms 还保住 80.3% 的 F1。
对 APP 自动化测试的工程启发
这篇论文的接口设计其实很像我们想要的“步级断言中间件”,几点可以直接搬:
- 把 oracle 从“最终态”前移到“每步态”。 传统 E2E 用例大多只在末尾断言,中间步靠隐式等待硬扛。VisCritic 的
(前帧, 动作, 后帧) → 成功/进度/错误类型是个可以插在每步之后的通用校验点,特别适合长流程、跨页面、跨系统组件的场景。 - 断言选型按变化类型分。 表 3 给的经验很实用:UI 微观状态(选中、开关、高亮、加载)用视觉判别,页面级跳转别用整屏像素 diff,纯文本类断言留给文本密集界面。混着用比单押一种强。
- no-op 检测值得单独做。 “点了没反应”在 App 自动化里极常见——控件还没渲染、被遮挡、需要先展开父菜单。用 SSIM+语义特征判 no-op,比盲目重试或直接判失败都更聪明,可以驱动“先等待/先滚动/先展开再重试”的恢复逻辑。
- 失败归因当成一等公民。 把每步的错误类型(no-op / wrong-target / page-error / timeout)记进轨迹,回归失败时能直接分桶,不用再人工逐条看录屏。这对分清“是脚本问题还是被测应用问题”特别省事。
- 训练数据可以自造。 用现有历史轨迹 + 动作错配/状态错配/no-op/失败分歧点这套扰动,能自建一个步级判别数据集,不必先堆人工标注。
放到 Android / iOS / H5 / Hybrid 的现实里,这套视觉校验对付 WebView 切换、权限弹窗、Push、支付 SDK 回跳、前后台切换这类“界面确实变了但难用文本描述”的场景,天然比文本断言合适。和 Appium / UIAutomator / XCUITest / Maestro 的关系是互补而非替代:控件树能查到的用控件断言(更稳更快),控件树查不到、只体现在像素上的视觉变化,交给这类视觉裁判兜底。
局限与点评
真正贡献有三点:一是把“步级校验”这件事和界面变化对齐到同一个(视觉)模态,指出了文本 PRM 的模态错配;二是给出一个即插即用、不用重训 agent 的独立裁判模块,且跨四个 agent 验证了可迁移性;三是那套“从已有轨迹自动造正负样本”的弱监督数据流水线,工程可复用度高。
可能被高估的部分要拎清楚:
- AndroidWorld 上没到统计显著(p≈0.08,留出集只有 34 个任务),作者自己写了,别把移动端的提升当成板上钉钉;主要显著性来自 Mind2Web / WebArena / AITW。
- AITW 是离线诊断,用的是记录好的前后截图,不是在线对任意候选动作的推理增益,不能当作实时收益读。
- backbone 的视觉短板会继承:细粒度文字变化(计数从 “3” 变 “4”)、极端视口/分辨率变化仍然吃力。这在移动端很关键——数字角标、红点、Toast 这类小变化,恰恰是很多断言要盯的。
- 弱标有噪声,分歧点估计靠轨迹对齐,可能错标;恢复策略也没单独评估过。
- 13B 级别的额外参数(InternViT-6B + 文本骨干)对很多测试流水线是不小的部署负担,虽然可以放独立 GPU、也有 SigLIP-400M 的轻量版,但要真接进 CI 还得算这笔账。
可复现/可落地建议:如果要在测试里验证这套思路,别一上来就上 6B 骨干。先用轻量视觉编码器 + 自造的历史轨迹判别集,在自己 App 的高频失败场景(WebView 切换、弹窗、加载态)上测 no-op 检测和 wrong-target 检测的 F1,看能不能达到“可当过滤器”的水平;把它定位成“先自动筛可疑步、再顶给人工复核”,而不是一步到位的无人断言。它的价值边界也很明显:错误累积严重的长流程收益大,短流程和纯文本界面收益小;控件树能覆盖的场景,优先用控件断言。