视觉记忆不是加得越多越好:一篇 GUI Agent 失败模式研究给自动化测试的启示
解析 Naive Visual Memory is Not Enough:这篇论文没有堆新 benchmark,而是把 GUI Agent 的失败拆成认知、视觉状态、隐藏操作、grounding 四类,并证明简单堆整屏视觉记忆会降低状态级错误、却推高动作级错误。对 APP 自动化测试来说,它把‘失败归因’和‘记忆该存什么像素’变成了可操作的问题。
论文:Naive Visual Memory is Not Enough: A Failure-Mode Study of GUI Agents arXiv:
2606.14106v1,2026-06-12(ICML 2026 Workshop on Failure Modes in Agentic AI) 作者:Seoyoung Choi, Minseok Ko, Hyunseok Lee, Kunwoong Kim, Woomin Song, Chanseok Jeon, Jinwoo Shin(Seoul National University / POSTECH / KAIST / Pion) 一句话结论:这篇论文真正有价值的地方不是又提了一个记忆框架(AGMem),而是它先把 GUI Agent 的失败拆成四类可判定的模式,再用实验证明‘naive 地把整屏截图塞进记忆’会同时降低一类错误、抬高另一类错误。对做 APP 自动化测试的人来说,它把两个一直含糊的问题落到了地上:失败到底该怎么归因,以及记忆该存哪些像素。
大多数 GUI Agent 论文的叙事是“我做了一个新方法/新 benchmark,指标涨了多少”。这篇不是。它先退回来问一个更基础的问题:现在的屏幕型 GUI Agent 到底是怎么错的?错误能不能被归到几个稳定的类别?以及,当下很流行的一招——把历史截图当作视觉记忆喂回给模型——到底修好了哪类错,又搞砸了哪类错。
这个切入点对工程更有用。在真实的 APP 自动化测试里,我们最缺的从来不是“又一个跑分”,而是当一条自动化用例挂掉时,能不能快速判断它是没看懂界面、规划错了下一步、不知道要先展开某个菜单、还是点歪了几个像素。这四种失败的修复成本和责任方完全不同,但传统断言只会告诉你“最终没到目标页”。这篇论文给的失败分类,恰好和测试里“归因”的诉求重合。
这篇论文在 GUIAgent 谱系里的位置
放到 OSWorld / AndroidWorld / WebForge / AgentNetBench 这条评测线里,它不是再造一个环境,而是站在这些环境之上做诊断。它做了两件事:
- 定义一套四类失败模式的 taxonomy,并配一个 LLM-as-Judge 的打标协议,可以在 online(OSWorld、WebForge)和 offline(AgentNetBench)轨迹上打标。
- 用这套诊断工具去测“视觉记忆”这个当前热门做法的真实效果——它明确地把整屏截图记忆(full-image memory)当成一个被测对象,而不是默认它有用。
也就是说,它更像一篇“测量仪器 + 受控实验”的论文,而不是“又一个 SOTA”。后半段提出的 AGMem(Action-Grounded Visual Memory)是顺着诊断结论做的改进,但全文的分量在前半段的分析上。
四类失败模式:把“挂了”拆成可判定的类别
论文的核心资产是这张失败模式图。它用四个真实任务示例,把 GUI Agent 的失败对应到 perception–reasoning–action 流水线的不同阶段。

四类的定义(对应论文 Table 1):
- 认知失败(Cognitive Failure):模型没搞懂任务目标、当前子任务、下一步、成功条件或恢复策略。典型表现是跟错了计划步骤、把失败的动作当成功了、或者过早结束任务。这是 planning 阶段的错。
- 视觉状态误读(Visual State Misunderstanding):模型读错了当前可见的屏幕状态,比如以为某个弹窗/下拉已经打开、认错了被选中的对象、误判了排序或筛选状态。这是 perception 阶段的错。
- 隐藏操作盲区(Hidden Operation Blindness):正确动作依赖一个当前屏幕上看不见、需要先做另一个操作才会出现的能力,比如先打开菜单/右键菜单/溢出菜单、用某个快捷键、做一次不明显的选择。这是 action-space 推理阶段的错。
- grounding 错误(Grounding Error):模型意图正确、动作类型也对,但执行的坐标/低层动作没落到目标上。这是 execution 阶段的错。论文强调:只有当推理表明它想点的目标和 ground truth 一致时,才算 grounding 错误;如果想点的目标本身就错了,那算认知失败或视觉误读。
这个边界划分很关键。它避免了工程上常见的混淆——把“点歪了”和“压根没看懂”混为一谈。注意这套 taxonomy 是多标签的,一条轨迹可以同时命中多类,所以各类比率不会加起来等于 100%。
不同环境,主导失败模式完全不同
先看没有任何记忆的 vanilla agent 在三个 benchmark 上的失败分布。这里用的是 GPT-5.4-mini。
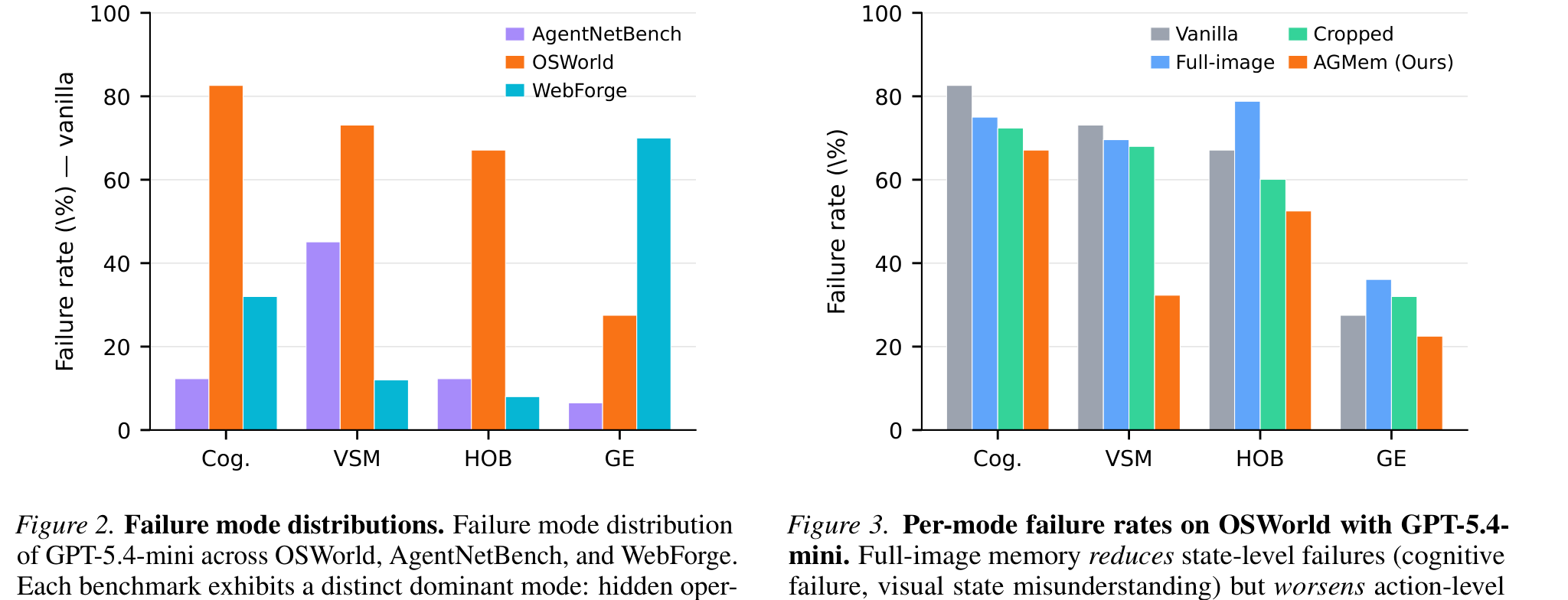
左图(Figure 2)的结论很干脆:每个环境的瓶颈不一样。
- OSWorld(桌面):认知失败 82.6%、隐藏操作盲区 67.1% 双高。因为桌面软件是长程、菜单密集的,关键命令经常埋在菜单、右键菜单、ribbon、快捷键里。
- WebForge(网页):grounding 错误主导,70.0%。网页界面布局密、可点目标小,像素级定位比大号桌面 UI 更脆;反过来隐藏操作盲区很低(8.0%),因为网页控件通常直接暴露在页面上。
- AgentNetBench(离线、逐动作评测):视觉状态误读相对突出(45.1%),且整体绝对失败率更低。因为它是逐步评测,隔离了每一步的状态识别需求,绕开了长程规划。
这个“环境决定主导失败模式”的观察,对测试选型直接有用:在网页/H5 场景,优先加固 grounding 与视觉断言;在原生 App 的复杂功能流里,隐藏操作与规划才是主战场。 拿一套统一的重试/等待策略去覆盖所有平台,本身就是在用错药。
关键实验:整屏视觉记忆是“拆东墙补西墙”
论文最有说服力的一个发现,是右图(Figure 3)和下面这张表。它把“加整屏截图记忆”这一招放到显微镜下。
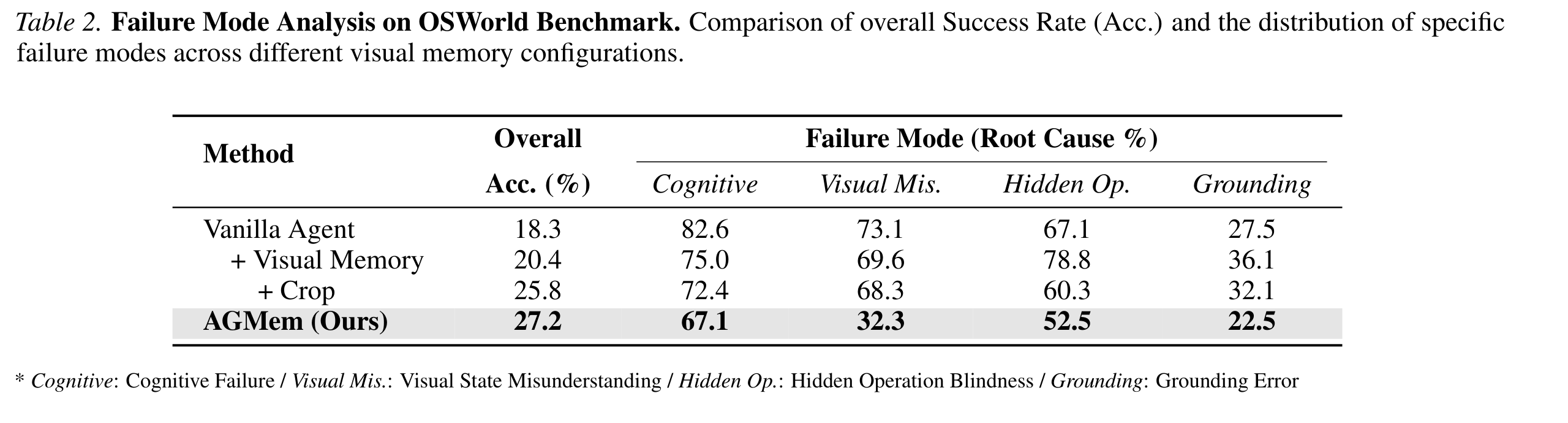
对着 Vanilla → +Visual Memory 这一行看,会发现一个很反直觉的分裂效应:
- 状态级错误下降了:认知失败 82.6%→75.0%(−7.6pp),视觉状态误读 73.1%→69.6%(−3.5pp)。整屏截图确实注入了有用的全局上下文,帮 Agent 重新定位任务和当前状态。
- 但动作级错误上升了:隐藏操作盲区 67.1%→78.8%(+11.7pp),grounding 错误 27.5%→36.1%(+8.6pp)。同样是这些整屏截图,把大量任务无关的元素塞进视觉上下文,反而干扰了对不显眼操作的判断,也稀释了坐标定位。
论文对这个现象的总结值得抄下来:视觉记忆本身有价值,但存哪些像素,和用不用记忆一样重要(which pixels are stored matters as much as whether memory is used at all)。整屏记忆本质是拿状态级错误去换动作级错误,而不是全面变好。
这一点对测试工程特别有共鸣。我们做失败复现、做“把历史截图/历史步骤喂给下一次判断”的辅助时,经常默认“信息越多越好”。这篇论文提醒:给自动化决策堆上下文,是有副作用的——无关像素会挤占注意力,让本来能识别的隐藏操作和精确点击反而退化。这和测试里“断言粒度过粗会掩盖真正问题”是同一类陷阱。
AGMem:既然问题出在像素,就只存动作相关的像素
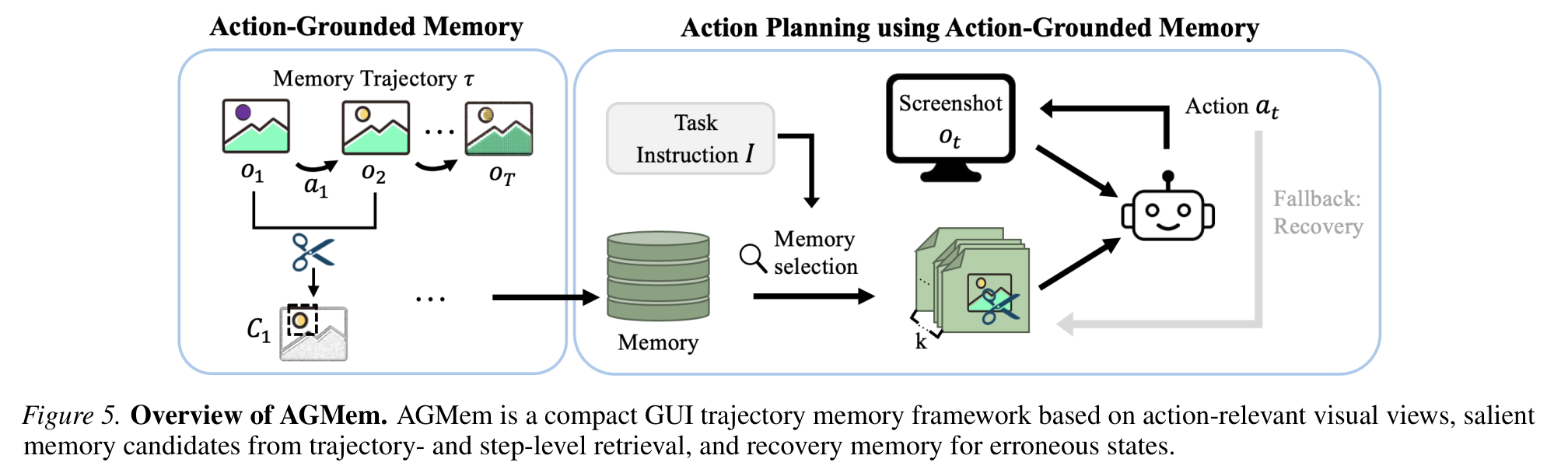
诊断结论指向一个明确的改进方向:视觉记忆应该更小(只留和动作相关的像素,而不是整屏)且更有选择性(只召回和当前子任务对齐的记忆步)。AGMem 就是把这两条落成设计。
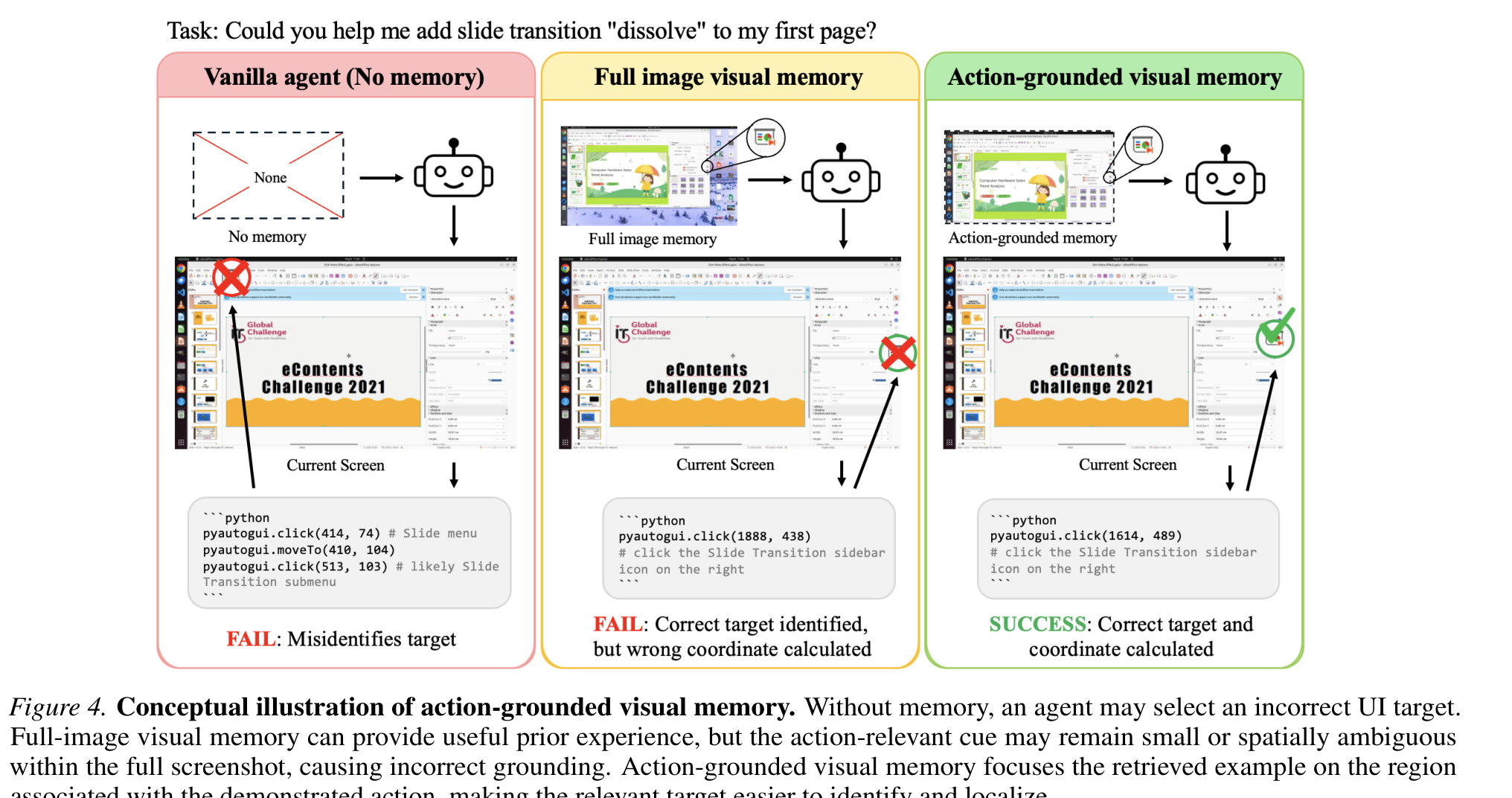
AGMem 的核心机制有三块:
- 动作相关视图(action-relevant view):不存整屏。对每一步,取动作前后的连续截图 (o_t, o_{t+1}),裁出动作实际生效的那块 GUI 区域,作为紧凑的记忆条目 C_t。记忆的原子单位是
(子任务标签, 动作, 动作相关裁图)。 - 两阶段召回(narrowed retrieval):先在轨迹级用 Sentence-Transformer 按子任务语义选出一个小候选池,再在步骤级用 CLIP 编码器对裁图和子任务标签做相似度匹配,返回 top-5 记忆步。这样避免每步都去搜整个记忆库带来的成本和噪声。
- 恢复感知记忆(recovery-aware memory):单独维护一份“如何从错误状态恢复”的记忆。当检测器判定当前轨迹进入了错误状态,就改从恢复记忆里召回纠错示范。这份记忆来自 AgentNet 里那些被主库排除(冗余或错误)、但后来在同一条轨迹内被纠正过来的子轨迹。
实验结果:不是“加记忆”,而是“加对的记忆”
回到 Table 2 看 AGMem 那一行:它是唯一一个四类失败模式同时下降的配置。视觉状态误读从 73.1% 一路压到 32.3%,隐藏操作盲区 67.1%→52.5%,grounding 错误 27.5%→22.5%,认知失败 82.6%→67.1%。整体成功率从 18.3% 提到 27.2%。
论文还专门做了消融,说明光裁图不够:只裁图但仍在整个记忆库上做召回(+Crop 那一行),确实部分修回了隐藏操作盲区(78.8%→60.3%)和 grounding(36.1%→32.1%),但在视觉状态误读上还是差得远(68.3% vs. AGMem 的 32.3%)。剩下的差距要靠子任务对齐的召回收窄来补——把召回限制在与当前子任务相关的记忆步上,防止跑偏的裁图重新注入无关线索。
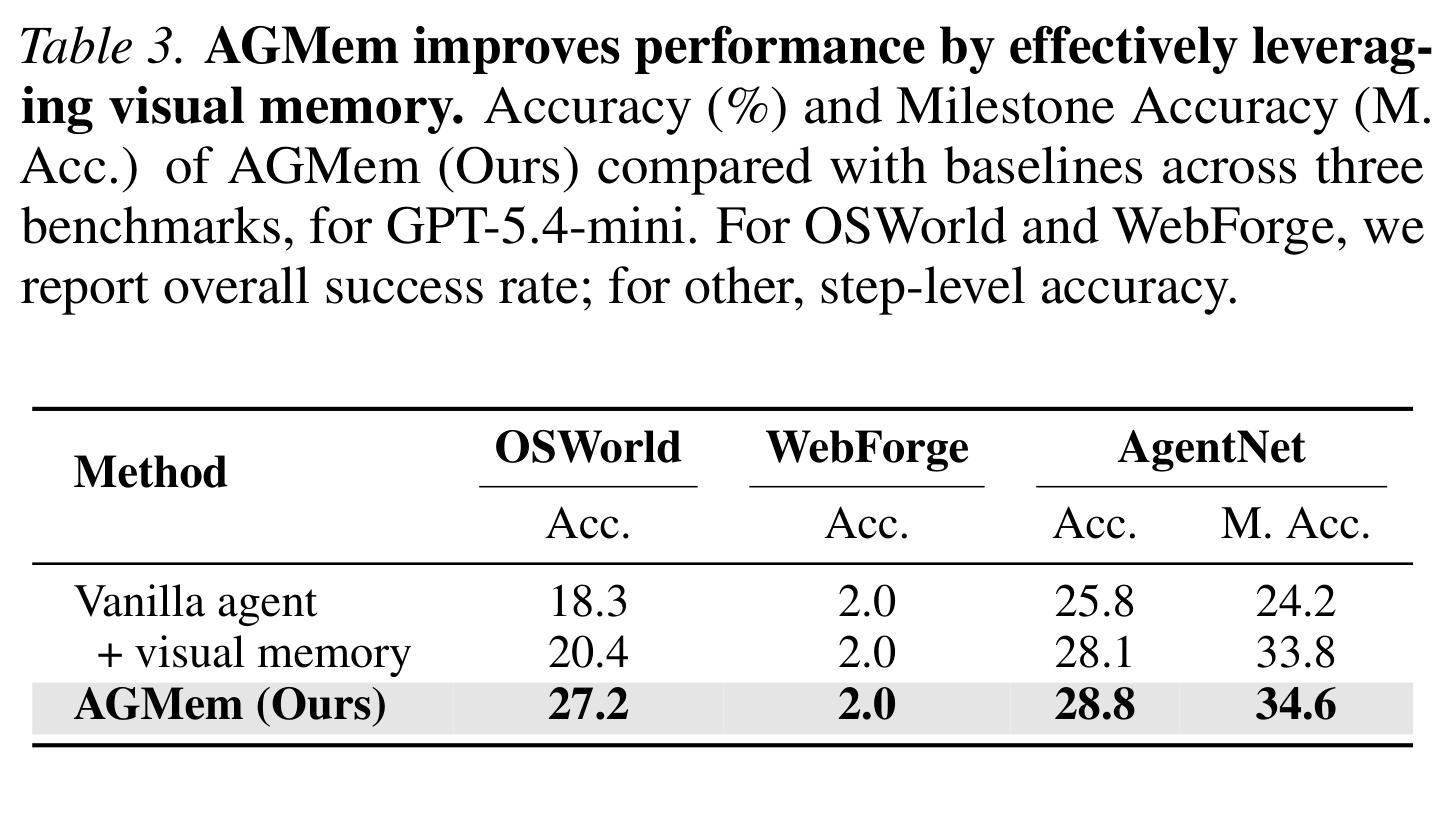
跨 benchmark 看(Table 3):OSWorld 上 AGMem 把成功率从 18.3% 提到 27.2%(+8.9pp),AgentNet 逐步准确率 25.8%→28.8%、里程碑准确率 24.2%→34.6%。这里要如实说明边界:WebForge 上三个配置都是 2.0%,AGMem 没有带来提升。论文对此的解释是 WebForge 的瓶颈是网页密集布局下的像素级 grounding,而 AGMem 主要改善的是记忆聚焦,对这类纯定位难题作用有限。这个负结果反而增加了论文的可信度——它没有把“到处都涨”当成卖点。
另外必须标注的取舍:这些数字都是在 GPT-5.4-mini 上、OSWorld 316 个任务、WebForge 抽样 50 个任务、每回合最多 50 步的设定下得到的,AgentNetBench 是在预先截好的截图序列上评的。样本规模不大,换更强或更弱的基座模型,失败分布可能整体平移。把这套具体数值当作定性趋势读,比当成普适结论读更稳妥。
对 APP 自动化测试 / 移动端 QA 的工程启发
这篇论文虽然实验主要在桌面和网页上,但它的两个核心结论几乎可以直接搬到 App 端自动化测试的语境里。
第一,把失败归因做成可判定的多标签,而不是只看最终态。 现在大多数 UI 自动化用例只有一个二元结果:到没到目标页。这篇论文的四类划分给了一个更好的骨架:
- 认知失败 → 对应测试里“步骤规划/意图理解错”:比如生成式测试 Agent 选错了业务分支、把一个失败的提交当成成功继续往下走。这类要靠业务状态断言兜底(后端数据、日志、network trace),光看 UI 截图看不出来。
- 视觉状态误读 → 对应“UI 状态识别错”:以为弹窗关了其实还开着、认错了选中项、把 loading 当成加载完成。这类要靠显式状态等待与结构化断言(元素可见性、可点击性、无障碍树属性),而不是靠固定 sleep。
- 隐藏操作盲区 → 对应移动端最典型的坑:功能藏在溢出菜单、长按菜单、二级页、需要先展开的抽屉里,或者要用手势/快捷方式触发。这类失败提示我们,探索式测试和测试生成不能只在当前可见控件上做动作采样,要显式建模“先展开再操作”的前置动作。
- grounding 错误 → 对应“点歪了”:坐标点击落在目标外、动态布局下元素位移、高 DPI/不同机型下的偏移。这类在 App 端尤其严重,是坐标点击方案(相对 Appium/UIAutomator/XCUITest 的元素定位)的固有风险。
第二,给自动化决策喂上下文要节制,先想清楚存哪些像素。 如果你在搭一个“记忆型”测试 Agent——把历史轨迹、历史截图召回来辅助下一步判断——这篇论文是一个直接的警告:整屏截图记忆会在移动端更糟,因为手机屏幕里状态栏、通知、悬浮按钮、广告位这些任务无关元素占比更高。更可行的做法和 AGMem 一致:
- 只存动作相关区域的裁图,而不是整屏。对应测试里,可以只保留“上一步点击/输入实际生效的那块控件区域 + 它的前后状态”,作为下一次同类操作的参照。
- 按当前子任务/页面收窄召回,避免把别的业务流的历史步骤混进来干扰判断。
- 单独维护一份“失败恢复”记忆。移动端错误传播特别常见——一个弹窗没处理干净,后面所有步骤都在错误前提下进行。AGMem 的恢复感知记忆思路,对应到测试里就是沉淀“遇到 X 异常态该怎么退回正轨”的可复用恢复动作(关闭意外弹窗、回退到上一页、重新拉起 deeplink),并在检测到异常态时优先召回这些恢复策略,而不是硬着头皮往下走。
第三,把评测拆到失败模式级别,而不是只报通过率。 这篇论文最值得测试团队借鉴的方法论,是它没有停在“成功率 X%”,而是拆出每一类失败的占比变化。落到 CI 上,一个更有信息量的自动化测试报告,应该能告诉你这一轮回归里,失败到底是集中在“看不懂界面”“规划错”“隐藏操作”还是“点歪了”——因为这四类分别对应完全不同的修复动作(改断言 / 改用例逻辑 / 补前置操作 / 换定位策略)。
局限与点评
先说真正的贡献:
- 它把 GUI Agent 的失败从一团模糊的“成功率”里拆成了四个可判定、可归因的类别,并给出了 LLM-as-Judge 的打标协议。这比又一个 benchmark 更有复用价值。
- 它用受控实验证伪了“视觉记忆越多越好”的默认假设,量化出了整屏记忆的分裂效应(降状态级、升动作级)。
- AGMem 是顺着诊断做的、逻辑自洽的改进,而且诚实地报了 WebForge 上的负结果。
可能被高估或需要警惕的地方:
- 评测规模偏小、基座单一。核心结论主要建立在 GPT-5.4-mini + OSWorld 316 任务 + WebForge 抽样 50 任务上。失败分布对基座模型很敏感,换 Claude/Gemini 或更小的开源模型,四类的相对比例大概率会变。论文自己也是把它作为“分析—设计—再分析”的方法论范例,而不是给出一个普适的失败常数。
- LLM-as-Judge 打标本身有噪声。用一个模型去判定另一个模型属于哪类失败,判官的偏差会进到统计里。论文说只在证据直接可见时才打标来控制这一点,但多标签打标的一致性没有给出独立的人工核验规模。
- AGMem 依赖高质量轨迹库。它的记忆来自 AgentNet 数据集里筛过的正确/可恢复轨迹。在没有这种大规模标注轨迹的场景(比如某个具体 App 的私有业务流),冷启动怎么构建动作相关记忆库,论文没有展开。这恰好是测试团队想落地时最先撞上的问题。
- 裁图这一步本身可能引入错误。动作相关视图是靠动作前后帧的差异裁出来的,如果动作没有明显的视觉效果(后台状态变更、纯数据写入),裁图机制能否稳定捕捉到有意义的区域,是个开放问题。
可复现 / 可落地建议
如果只从这篇论文里带走三件事:
- 先复现它的失败分类,而不是它的方法。给你现有的自动化用例失败集,用一个 LLM-as-Judge 按“认知 / 视觉状态 / 隐藏操作 / grounding”四类打标,很可能立刻就能看出你的失败集中在哪一类——这比装 AGMem 便宜得多,收益也更直接。
- 审视你的“记忆/上下文”注入是不是在拆东墙补西墙。如果你给测试 Agent 喂了历史整屏截图,做一个对照:只喂动作相关裁图,看隐藏操作和点击精度是否回升。
- 把恢复策略沉淀成可召回的记忆,而不是散落在各个用例里的临时 try-catch。检测到异常态时优先召回恢复动作,是降低移动端错误传播的性价比之选。
参考链接
- 论文:Naive Visual Memory is Not Enough: A Failure-Mode Study of GUI Agents(arXiv:2606.14106)
- OSWorld:Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
- WebForge:Breaking the Realism-Reproducibility-Scalability Trilemma in Browser Agent Benchmark
- OpenCUA:Open Foundations for Computer-Use Agents