GUICrafter 论文解析:GUI Agent 的数据飞轮,未必只能靠人工轨迹
解析 2026-06-29 arXiv 论文 GUICrafter:它用海量未标注截图中的交互信号构造 meta-task,再用少量高质量数据做 RL 校准,尝试把 GUI Agent 训练从昂贵人工轨迹推向弱监督预训练。文章从移动端 QA 与 APP 自动化测试视角讨论其贡献、证据和工程边界。
论文:GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
arXiv:2606.29705v1,2026-06-29
作者:Sunqi Fan, Lingshan Chen, Runqi Yin, Qingle Liu, Yongming Rao, Meng-Hao Guo, Shi-Min Hu
代码/数据/模型:论文摘要给出项目地址 https://github.com/fansunqi/GUICrafter
一句话结论:GUICrafter 真正值得关注的地方,不是又把某个 GUI grounding 表格刷高了几点,而是把 GUI Agent 训练里的“数据从哪里来”换了一个问题:能不能先从未标注网页、桌面和移动端截图中学会哪些区域可交互,再用少量高质量轨迹校准到真实任务。对 APP 自动化测试来说,这比单纯堆人工用例更接近可扩展的数据飞轮,但它还没有解决在线执行、业务 oracle 和异常恢复。
GUI Agent 这两年进展很快,但训练数据一直是硬约束。Web 文本可以从互联网上大规模抓取,图像-文本对也有成熟清洗管线;GUI 轨迹就麻烦得多。一个可用样本往往要包含截图、任务描述、动作类型、坐标或元素框、输入文本、历史上下文,甚至还要知道这一步执行后页面状态是否正确。换到移动端 APP,成本更高:登录态、权限弹窗、厂商 ROM、WebView、弱网、推送、后端数据和业务状态都会污染轨迹。
GUICrafter 切入的是这个数据瓶颈。它不先问“怎样标更多人工轨迹”,而是问:未标注截图里本来就有大量交互线索,能不能把这些线索变成弱监督任务,让模型先学会 GUI 的可交互结构?
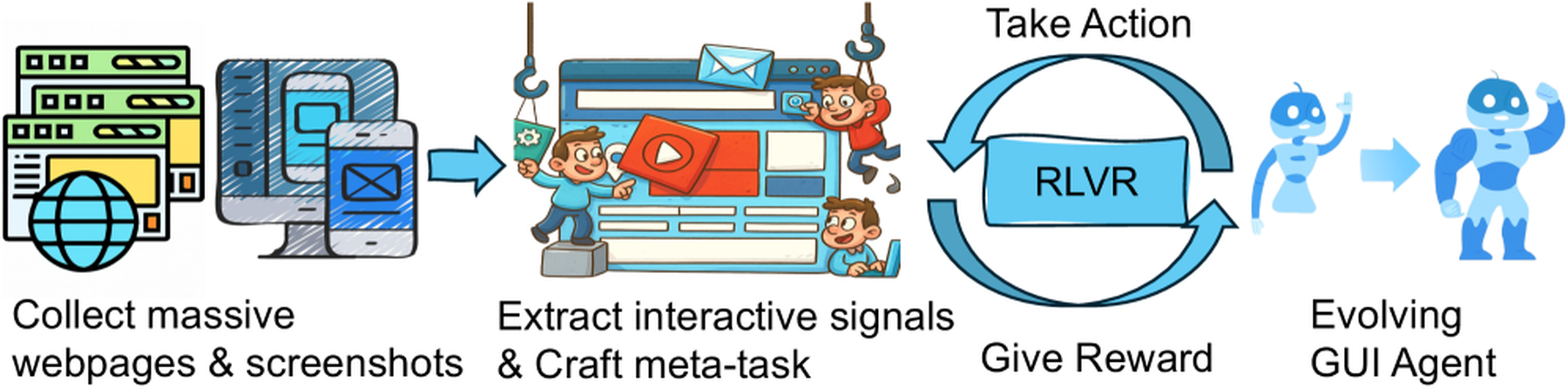
论文的核心主张可以概括成两步:
- Stage 1:Weakly-Supervised GUI Pretraining。 从真实网页、桌面和移动端截图中抽取交互信号,把 clickable、selectable、typeable 等区域转成 meta-task,用 RLVR / GRPO 训练模型在截图上定位可交互区域。
- Stage 2:High-Quality Reinforcement Fine-tuning。 再用少量清洗过的高质量 GUI 任务数据做校准,让模型从“知道哪里能点/能输”进一步变成“知道当前任务应该点哪里/输什么”。
这套路线对 GUIAgent 领域的意义在于,它把训练范式从“全靠高质量人工轨迹”往“弱监督 GUI 预训练 + 小规模任务校准”推了一步。对移动端 QA 来说,这个方向很现实:真实 APP 测试不可能把每个版本、每个页面、每个异常态都人工标成轨迹,但截图、控件树、可点击区域、历史测试脚本和线上探索日志确实可以持续积累。
这篇论文在 GUIAgent 谱系中的位置
放在 GUIAgent / computer-use agent 的近期谱系里,GUICrafter 不是一个新的在线环境 benchmark,也不是一个完整的 APP 测试框架。它更像是 GUI foundation/action model 的数据训练论文。
它和几条线都有关系:
- 和 UI-TARS、OS-Atlas、Aguvis、ShowUI 这类 GUI 原生模型相比,GUICrafter 关注的是如何少用人工标注数据来训练可用的 GUI grounding / action model;
- 和 GUI-R1、MobileGUI-RL、WebAgent-R1、ZeroGUI 这类 RL 方向相比,它减少了对显式任务标注、reward model 或 world model 的依赖,把奖励更多绑定到环境交互信号;
- 和 Mind2Web、ScreenSpot-Pro、AndroidControl、AITW、AndroidWorld、OmniACT 这类评测相比,它展示的是同一个训练思路能不能跨 Web、桌面和移动端 benchmark 迁移。

Table 1 的信息很关键。很多 GUI Agent RL 工作会依赖 LLM 生成任务、reward model、world state model 或人工任务。GUICrafter 的取舍更朴素:先不要求模型理解完整任务语义,只要求它从截图里学会“这个界面上哪些地方可能被操作”。这个目标比端到端任务完成更弱,但也更容易规模化。
这里不要把它理解成“弱监督已经替代人工轨迹”。更准确的说法是:Stage 1 学的是 GUI 可供性和视觉定位的底座,Stage 2 才把这个底座对齐到具体任务语义。 这也是后面实验里反复出现的模式:只做 Stage 1 有明显提升,但完整效果来自 Stage 1 + Stage 2。
Stage 1:把未标注截图改造成 meta-task
GUICrafter 的 Stage 1 做了三件事。
第一,收集真实网页与截图。Web 侧,作者从热门网站抓取页面,并用 MHTML 保存页面和资源,递归访问链接形成类似真实 GUI 任务分布的页面树;移动端侧,使用 AndroidControl 和 AITZ 中的大量页面截图与自动收集到的交互元素,但不使用其中人工标注的任务轨迹。
第二,抽取交互信号。网页里的按钮、输入框、菜单、可点击区域,本身就隐含了人机交互结构;移动端数据里的交互元素也能提供类似线索。论文把这些线索抽象成可验证的目标区域。
第三,构造 meta-task。比如:点击任意 clickable 区域、从下拉菜单选择有效选项、向输入框输入文本。模型根据截图和 meta-task 输出动作,奖励由动作类型、位置命中和文本输入等因素组成。

这张图说明了 GUICrafter 的一个重要判断:很多 GUI 能力不是从“完整任务”开始学的,而是从界面可供性开始学的。 人看到一个页面时,先知道哪里像按钮、哪里像输入框、哪里像菜单,再结合目标决定动作。GUICrafter 的 Stage 1 正是在模拟这个前置能力。
换到 APP 自动化测试里,这个思路很有启发。传统 Appium / UIAutomator / XCUITest 更偏结构化控件定位,视觉测试更偏截图差异,而 GUI Agent 需要把两者接起来:在没有稳定 accessibility id、页面有 H5/Hybrid 或控件树不可靠时,仍然能从截图判断哪些区域可交互。未标注截图、控件树、埋点点击热区和历史探索日志,都可能成为类似 Stage 1 的弱监督来源。
但这里也有边界。Stage 1 的 meta-task 只是“可交互区域”级别,不等于业务任务。一个支付页上“取消”“确认”“返回”“优惠券”“同意协议”都可能可交互,但测试 agent 必须知道当前用例意图和风险等级。GUICrafter 后面用 Stage 2 校准,正是因为可供性不能替代任务语义。
Stage 2:少量高质量数据做任务校准
Stage 2 的处理更接近常规 GUI Agent 训练,但数据量明显小得多。
论文对 Mind2Web 训练集做了清洗:重新截图或过滤渲染不一致页面,删除任务描述不清的样本,过滤无效 action history,修正部分不准的 bounding box。最终 Web / desktop 域得到 6,795 条高质量数据,其中包括 Mind2Web 的 4,966 条清洗样本,以及 GUI-R1-3K 中 1,744 条 Web 样本和 85 条桌面样本。移动端则从 AMEX 中选择 3,200 条样本。
这一步的作用不是扩大规模,而是做语义对齐:让模型知道在某个具体用户任务下,应该选择哪个可交互元素,而不是随便点一个可点击区域。
论文在 Figure 3 里给了一个很直观的例子:Stage 1 已经知道页面上有哪些可操作区域,但在具体任务中可能点错目标;经过 Stage 2 后,模型能把任务语义和目标区域对上。

这个案例对工程落地很重要。很多团队引入 GUI Agent 做 APP 测试时,会先被“模型能看懂屏幕、能点按钮”吸引,但真正跑用例时失败经常发生在语义层:它知道哪里能点,却不知道现在该不该点;它能打开筛选器,却不知道筛选条件是否符合用例;它能提交表单,却不知道后端业务状态有没有变成预期。
所以,GUICrafter 的两阶段设计可以对应到测试平台里的两层数据:
- 弱监督层:页面截图、控件树、点击热区、历史探索路径、可输入区域、页面跳转关系;
- 任务校准层:人工维护的核心 E2E 用例、业务流程、断言规则、mock 数据、接口日志、数据库状态和 crash/ANR 证据。
前者让模型获得广泛页面理解能力,后者决定它能不能在业务测试里可靠执行。
主结果:少量标注数据下接近或超过强基线
GUICrafter 的实验覆盖六类 benchmark:Mind2Web、ScreenSpot-Pro、OmniACT、AndroidControl、AITW 和 AndroidWorld。指标包括 Element Accuracy、Operation F1、Step Success Rate、grounding accuracy、Episode Success Rate 等。
Mind2Web 是 Web 任务里的关键表。论文报告 GUICrafter-3B 在平均 Element Accuracy 上达到 60.2,超过 UI-TARS-2B 的 59.5;GUICrafter-7B 达到 70.0,也高于 UI-TARS-7B 的 68.3。更重要的是,作者强调 UI-TARS 使用约 18.4M 样本,而 GUICrafter 的训练包含 6,795 条高质量样本和 20,000 条无人工标注成本的弱监督样本。
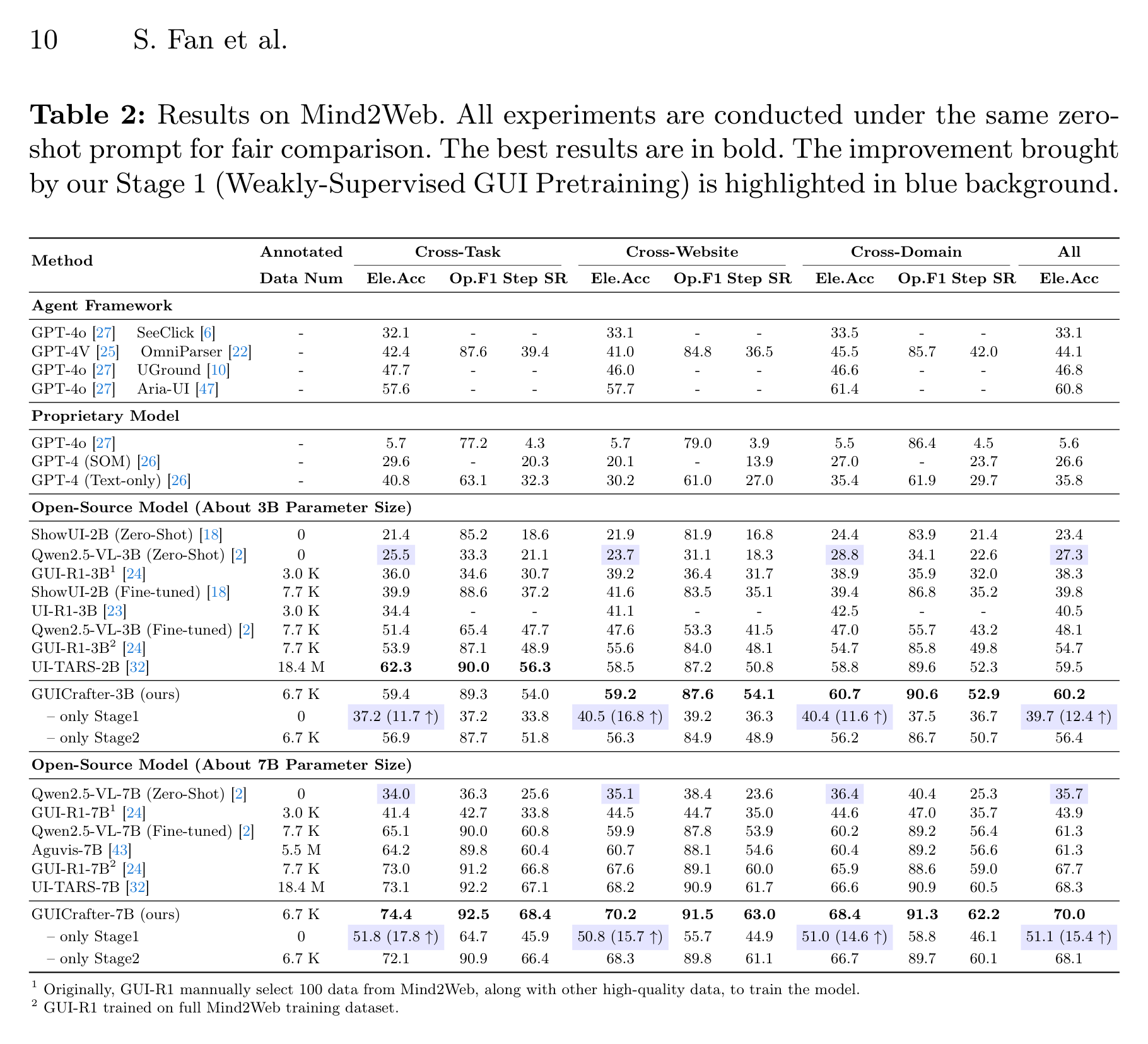
这个表最值得看的不是单个最高数字,而是两个模式。
第一,Stage 1 对跨分布泛化有帮助。 Web 任务里 Cross-Website 和 Cross-Domain 更接近真实迁移,GUICrafter 在这些 split 上的优势说明:大量真实页面弱监督可能确实让模型见过更丰富的 GUI 外观。
第二,Stage 1 + Stage 2 比只做 Stage 2 稳定更好。 论文总结在 Mind2Web 上有约 3%–4% grounding accuracy 增益。这说明弱监督预训练不是噱头,至少在这些 benchmark 上给后续小规模高质量训练提供了更好的初始化。
ScreenSpot-Pro 更偏细粒度 GUI grounding,覆盖 Dev、Creative、CAD、Scientific、Office、OS 等专业场景,并区分 Text/Icon。GUICrafter-3B 的 All Avg. 是 33.5,高于 GUI-R1-3B 的 28.6 和 UI-TARS-2B 的 27.7;GUICrafter-7B 的 All Avg. 是 39.5,也高于 UI-TARS-7B 的 35.7。
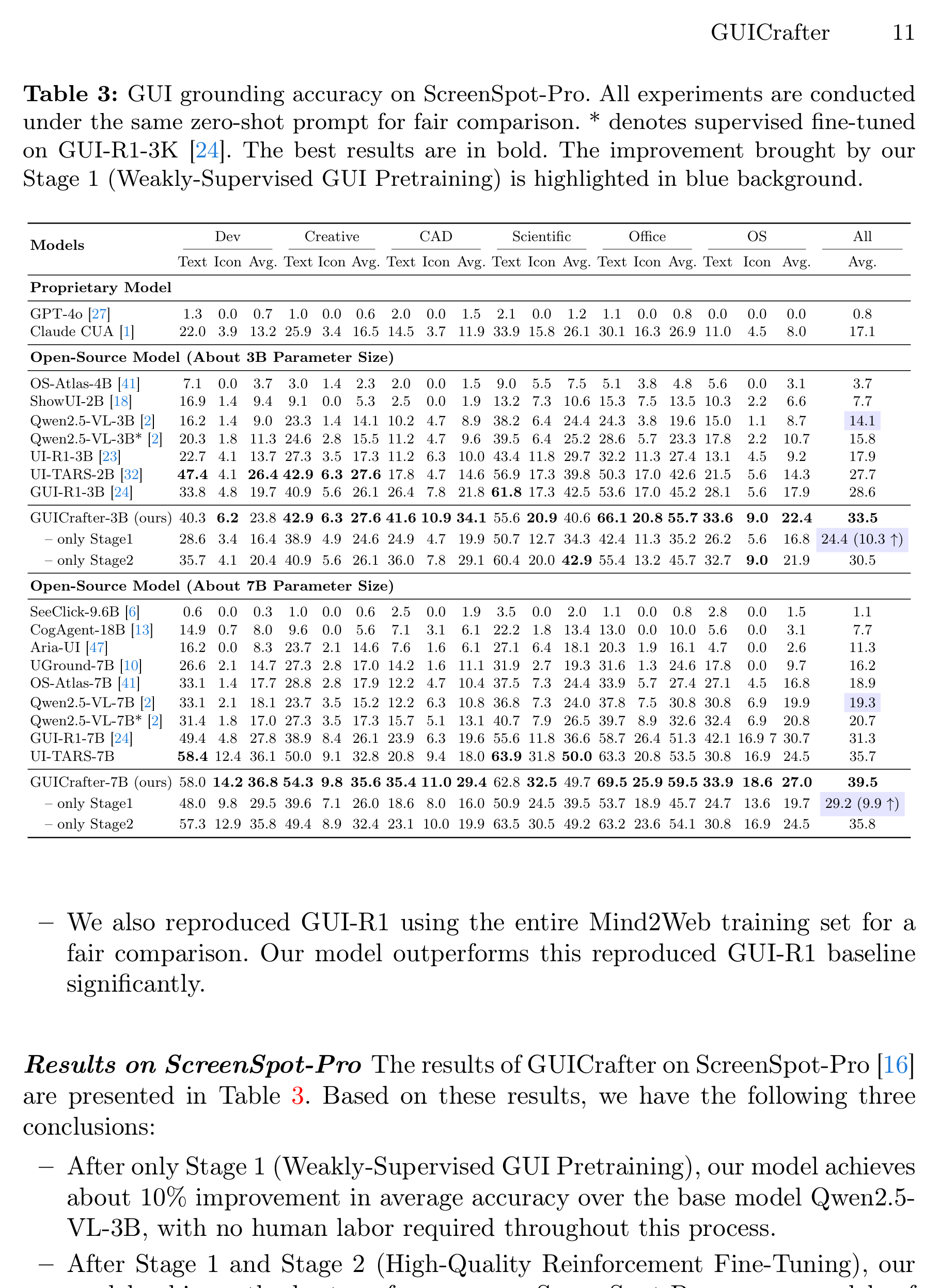
ScreenSpot-Pro 对移动端 QA 的启发在于:细粒度控件定位仍然是瓶颈。真实 APP 里小图标、浮层按钮、底部 tab、半透明遮罩、WebView 内控件、列表项里的局部按钮,都容易让视觉 grounding 出错。GUICrafter 提高了 grounding,但表里的绝对数字也提醒我们:这类能力还远不到可以脱离结构化执行工具单独上线。
移动端结果:AndroidControl、AITW、AndroidWorld 更接近 QA 关注点
对 RainPot 这类面向 APP 自动化测试 / Mobile QA 的视角,移动端实验比 Web grounding 更关键。
在 AndroidControl 上,GUICrafter-3B 在 Low split 上 Step SR 达到 70.73,High split 上 Step SR 达到 56.50;只做 Stage 1 时也能达到 62.35 / 44.65。在 AITW zero-shot 上,GUICrafter-3B overall 是 50.89,高于 GUI-R1-3B 的 43.60,接近 GPT-4V + history 的 52.96,但仍低于 OmniParser 辅助方案的 57.7。
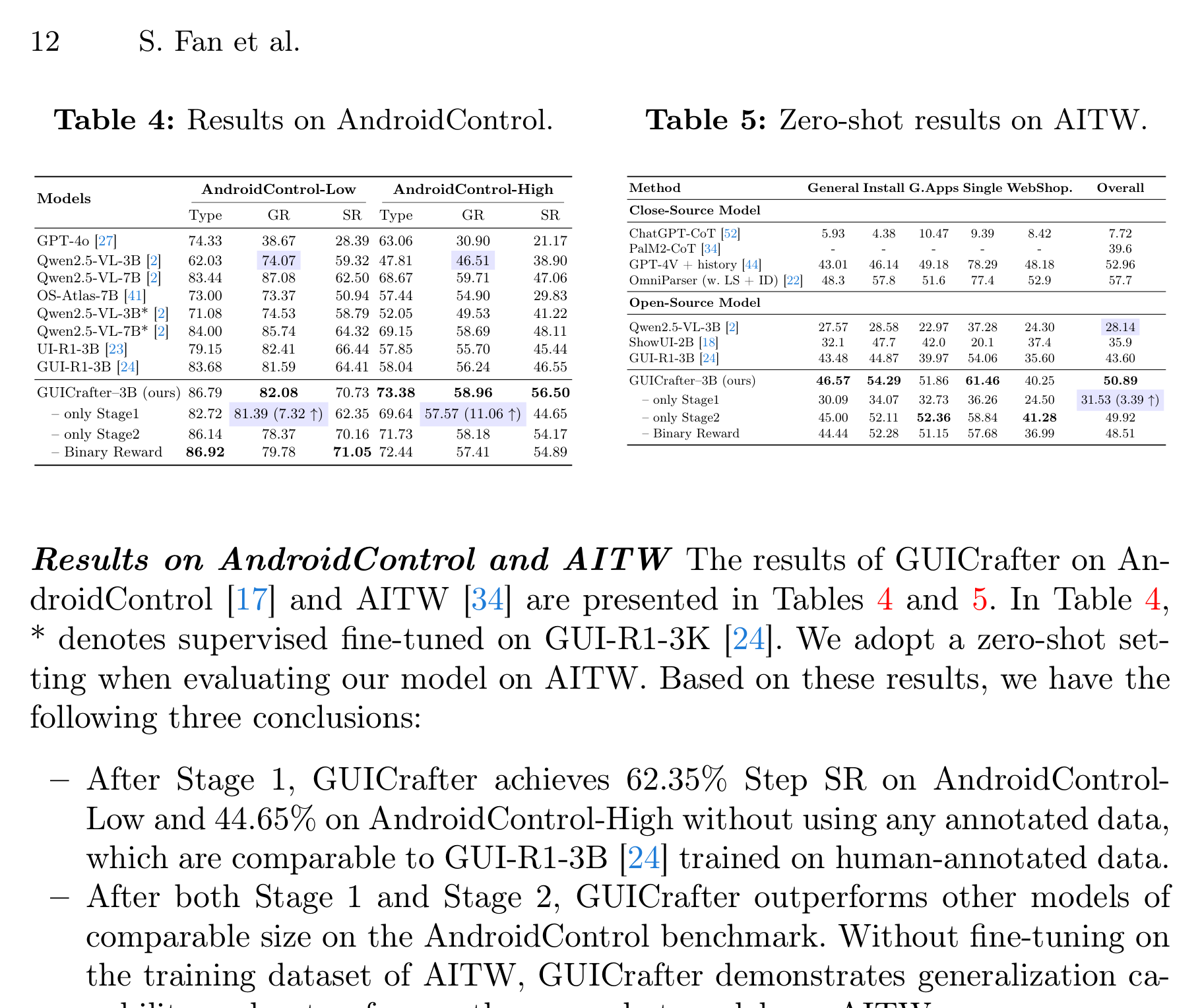
AndroidWorld 更值得单独看,因为它是在线 benchmark,评价的是 episode success,而不是只在离线轨迹上预测下一步。论文报告 Qwen2.5-VL-3B 是 10.34,GUI-R1-3B 是 14.22,GUICrafter-3B 是 25.43;只做 Stage 1 是 14.66。这个提升说明两阶段训练确实有可能转化到在线任务,但绝对成功率仍然不高。
这对 APP 自动化测试的判断很直接:
- GUICrafter 这种弱监督预训练可以改善“看屏幕、找控件、做下一步动作”的底层能力;
- 但在线任务成功率仍然说明,真实执行还受等待、重试、页面跳转、状态验证、异常恢复影响;
- 测试平台不能只接一个 GUI action model,还需要 Appium/Maestro/UIAutomator/XCUITest 这类执行层、接口/日志/数据库 oracle、设备状态 reset 和失败复现机制。
换句话说,GUICrafter 可以成为测试 agent 的“视觉与动作底座”,但还不是完整的测试系统。
消融:meta-task 足够简单,但不是万能
论文的 Table 7 很有意思。作者比较了四种 Stage 1 任务形式:only-click task、meta-task、LLM 生成任务、人工标注任务。评估在 Mind2Web 的一个 hard subset 上进行:unseen domain,轨迹长度超过 10 步,148 个 episodes,平均长度 13.57。
结果是:Stage 1 阶段,人工标注任务明显更强;但经过 Stage 2 后,meta-task、LLM-gen task 和 annotated task 的表现非常接近。比如 Stage 1+2 的 Step SR 分别是 51.3、51.5、52.1。

这个结论对工程有两层含义。
第一,弱监督任务不必一开始就做得像真实业务用例。只要它能覆盖基本交互类型,并且能提供稳定奖励,就可能作为大规模预训练底座。
第二,Stage 2 不能省。Meta-task 再有效,也只是把模型带到“懂 GUI 结构”的状态;业务测试中的“该点哪里、何时停止、如何断言失败”仍然需要高质量任务数据和验证信号。
移动端 QA 可以借鉴这个分层:用大量低成本数据训练通用页面交互能力,再把有限人工成本集中到高价值业务流,例如登录/支付/下单/IM/直播/地图/权限/异常恢复等场景。不要反过来,把人力耗在给每个普通按钮都标注轨迹。
数据规模与噪声:弱监督可以扩,但噪声天花板仍在
GUICrafter 还分析了 Stage 1 数据规模和噪声。
Figure 4 显示,随着 Stage 1 数据从 10、100、1,000、10,000 增加到 50,000,Mind2Web 和 ScreenSpot-Pro 的 grounding accuracy 持续提升。论文还提到,用 10 条弱监督样本就能让 Qwen2.5-VL-3B 在 Mind2Web 上提升 1.7%,在 ScreenSpot-Pro 上提升 2.6%;数据继续扩大时,性能仍未在 50k 处饱和。
Table 8 则看噪声鲁棒性。作者人工检查 1,000 条 Stage 1 数据,认为 84.9% 完全正确;噪声定义为交互元素缺失、重叠或顺序错误。当噪声率从 0% 增加到 30%,只做 Stage 1 的性能明显下降;但经过 Stage 2 后,Mind2Web 从 59.1 降到 58.3,ScreenSpot-Pro 从 32.9 降到 31.8,差距被明显压缩。
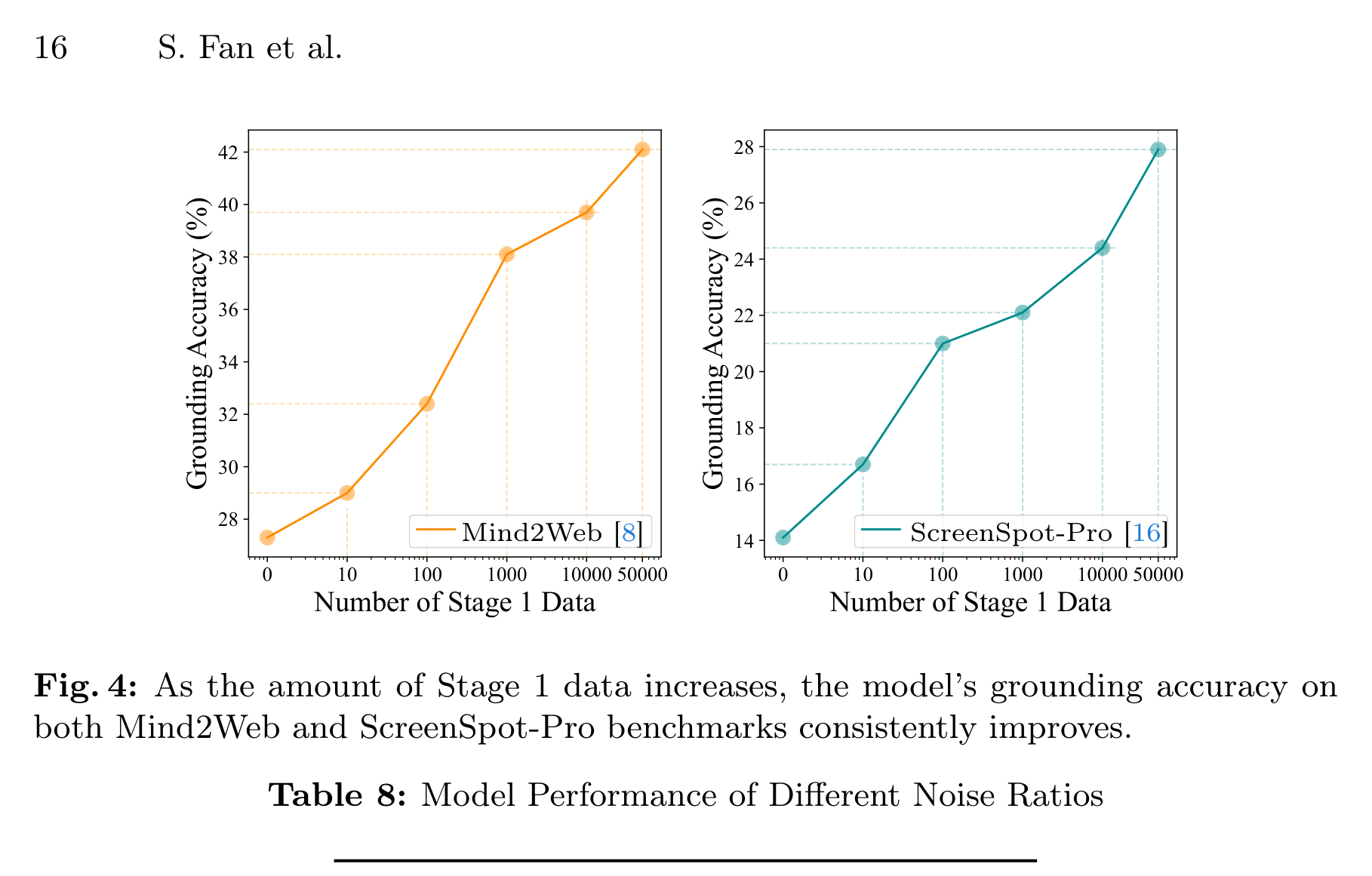
这点很适合落到 APP 自动化测试平台。真实移动端数据一定有噪声:控件树不完整、OCR 误识别、点击热区和视觉元素错位、WebView 控件不可见、列表复用导致元素 ID 不稳定、埋点和实际 UI 不一致。GUICrafter 的结果说明,弱监督数据不必完美才能有价值;但也不能完全不清洗,因为 Stage 1 的噪声会直接影响模型对可交互区域的理解。
更稳妥的做法是:
- 把弱监督数据来源分层打分,例如 accessibility tree、历史真实点击、人工探索、OCR/视觉检测、埋点热区分别有不同置信度;
- 对关键页面做小规模人工审计,估计噪声类型,而不是只看总量;
- 用高质量回归用例和业务 oracle 做 Stage 2 式校准,避免模型只学到“哪里能点”,却学不到“为什么点”。
OmniACT 补充结果:桌面/网页动作能力也有提升
OmniACT 放在附录,但对跨平台能力有参考价值。GUICrafter-3B 在 OmniAct-Web 上 SR 为 77.37,在 OmniAct-Desktop 上 SR 为 82.88;GUI-R1-3B 分别是 75.08 和 78.31。只做 Stage 1 在 Desktop 上也有 78.81 的 SR。
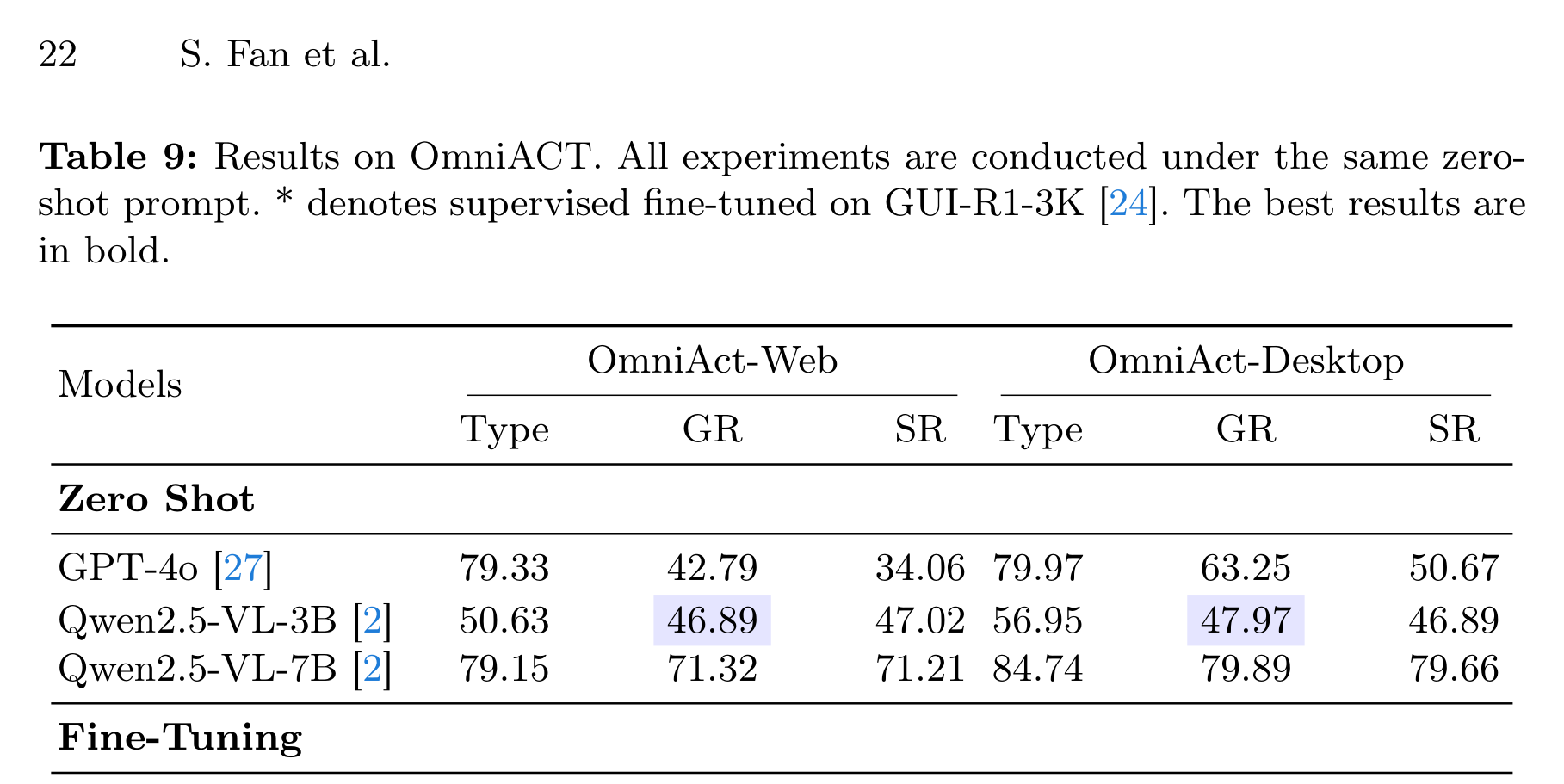
这说明 GUICrafter 学到的不是某一个 Android benchmark 的局部技巧,而是更通用的 GUI 可交互结构。不过,OmniACT 仍然主要评价动作预测和 grounding,不等同于真实桌面或移动端长程任务成功。真实测试系统还要处理应用状态、网络、权限、数据依赖和可回滚性。
真正贡献:把 GUI Agent 数据问题拆开了
GUICrafter 的贡献可以归纳成三点。
第一,把 GUI Agent 的数据瓶颈从“人工轨迹稀缺”拆成两层问题:可交互结构学习 + 任务语义校准。 这比单纯扩人工标注更可扩展。
第二,证明简单 meta-task 有足够训练价值。 论文显示,Stage 1 不需要 LLM 为每个元素生成复杂任务描述,click/select/type 这类抽象任务已经能学到不少 GUI-specific knowledge。
第三,在 Web、桌面、移动端多个 benchmark 上给出一致证据。 Mind2Web、ScreenSpot-Pro、AndroidControl、AITW、AndroidWorld、OmniACT 的结果共同支持一个判断:弱监督 GUI 预训练能提升 grounding 和动作预测,并且部分转化到在线 episode success。
对 APP 自动化测试来说,这个贡献不是“可以马上替代 Appium”,而是提供了一种数据建设方向:把大量低成本 UI 观测转成训练信号,再用少量高价值业务轨迹校准。
可能被高估的部分
这篇论文也有几个需要保留的边界。
第一,benchmark 提升不等于测试闭环可用。 AndroidWorld 的提升很明显,但 25.43 的 Episode SR 仍然说明在线执行远未稳定。真实 APP 测试要求可复现、可断言、可回滚、可定位失败原因,不是完成一次任务就够。
第二,Stage 1 学到的是可交互性,不是业务正确性。 对测试来说,最难的往往不是点按钮,而是知道点击后后端状态、订单状态、日志、埋点、crash/ANR、风控提示是否符合预期。GUICrafter 没有解决 oracle 设计。
第三,弱监督数据来自已有数据集和网页抓取,和真实企业 APP 仍有差距。 企业内部 APP、金融/电商/直播/地图/IM 等场景会有登录态、权限、隐私数据、动态推荐流、Hybrid 页面和灰度开关。未标注截图能帮忙,但需要和设备 farm、mock 后端、埋点日志、接口录制结合。
第四,模型训练成本和复现细节仍要看开源质量。 论文说代码、数据和模型可用,这是好事;但真正复现时还要确认数据清洗规则、网页抓取质量、GRPO 超参、reward 计算和不同 benchmark 的 prompt 是否容易跑通。
对 APP 自动化测试和移动端 QA 的启发
如果把 GUICrafter 的方法迁移到 APP 自动化测试平台,最有价值的不是照搬论文里的 benchmark,而是复刻它的数据分层思想。
1. 把未标注 UI 资产变成弱监督数据。 现有自动化测试里其实已经有很多低成本信号:截图、控件树、点击坐标、页面跳转、OCR 文本、历史人工探索、monkey 测试轨迹、线上埋点热区、视觉回归基线。它们不一定能组成完整用例,但可以训练模型理解页面结构和可交互区域。
2. 把人工成本集中到高价值业务流。 登录、支付、下单、退款、IM、直播、地图、权限、前后台切换、Push、WebView 跳转,这些流程才需要人工定义任务语义、断言和风险边界。普通控件可交互性不应该主要靠人工标注。
3. GUI Agent 要和传统测试工具组合。 GUICrafter 负责视觉 grounding 和动作建议;Appium、UIAutomator、XCUITest、Maestro 负责可控执行;接口日志、数据库、mock server、crash/ANR、埋点负责 oracle;RPA 或 deeplink 负责绕过不必要的 UI 路径。只有组合起来,才像测试系统。
4. 数据噪声要可观测。 论文里 84.9% 完全正确的弱监督样本是一个提醒:训练数据质量需要抽样审计。移动端尤其要记录噪声来源,是控件树错、OCR 错、坐标缩放错、WebView 结构缺失,还是截图和操作时刻不同步。
5. 在线评估不能省。 离线 Step SR 提升是好信号,但最终要看真实设备上的任务成功率、失败可复现率、平均恢复次数、误操作率、测试 oracle 命中率和人工接管率。
总结
GUICrafter 把 GUI Agent 训练里的一个核心问题讲清楚了:高质量人工轨迹很贵,但 GUI 世界本身充满弱监督信号。未标注截图、网页结构、可点击区域、输入框、选择器和历史交互都可以先教模型“界面上什么东西能操作”;少量高质量任务数据再教它“当前目标下应该操作哪个东西”。
这条路线对移动端 QA 很有价值。APP 自动化测试不缺截图,不缺执行日志,也不缺零散探索轨迹,缺的是把这些资产整理成能持续训练和评估 agent 的数据飞轮。GUICrafter 给了一个可参考的拆法。
但它也提醒我们,不要把 GUI grounding 提升误读成测试系统已经完成。真实 APP 测试最后看的不是模型能不能点中按钮,而是它能不能在有权限弹窗、WebView、网络抖动、后端状态和业务断言的环境里稳定执行,并在失败时留下可复现证据。
参考链接
- 论文:https://arxiv.org/abs/2606.29705
- PDF:https://arxiv.org/pdf/2606.29705
- arXiv HTML:https://arxiv.org/html/2606.29705v1
- 项目地址(论文摘要):https://github.com/fansunqi/GUICrafter
- 相关方向:UI-TARS、GUI-R1、ScreenSpot-Pro、Mind2Web、AndroidControl、AITW、AndroidWorld、OmniACT