Argus 论文解析:GUI Agent 什么时候应该相信自己的点击
从 GUIAgent 与移动端 QA 视角解析 Argus:它把 computer-use agent 的不确定性量化从通用 VLM 校准拉回到可执行 GUI grounding,系统比较 27 种 open-weight UQ 方法、8 种 API-only 方法与 conformal click disks,提醒工程系统不要只看 top-1 坐标,还要判断何时拒绝、复查或交给人。
论文:Uncertainty Quantification for Computer-Use Agents: A Benchmark across Vision-Language Models and GUI Grounding Datasets
arXiv:2606.25760v1,2026-06-24
作者:Divake Kumar, Sina Tayebati, Devashri Naik, Amanda Sofie Rios, Nilesh Ahuja, Omesh Tickoo, Ranganath Krishnan, Amit Ranjan Trivedi
一句话结论:Argus 真正推进的不是又做了一个 GUI grounding 榜单,而是把“这个点击能不能执行”变成可度量问题:同一个坐标预测旁边,要同时有错误检测、选择性执行、校准、空间覆盖半径和跨模型迁移稳定性。对 APP 自动化测试来说,它的启发很直接:低置信度点击不应该硬点,危险页面更不能只靠 top-1 坐标。
GUI Agent 评测里常见的默认假设是:模型给出一个坐标,落在目标框里就是对,落在外面就是错。这个设定适合做 grounding accuracy,但离真实执行还差一步。真实系统里,Agent 点错一个按钮,后果可能不是“这道题不得分”,而是提交表单、删除内容、切换账号、触发支付、修改线上配置,或者把测试流程带进一个无法恢复的状态。
Argus 这篇论文切入的正是这个缝隙:computer-use agent 不只需要预测一个 click,还要知道自己对这个 click 有多不确定;更进一步,系统要能利用这种不确定性决定是否执行、是否放大检查、是否换策略、是否让人确认。
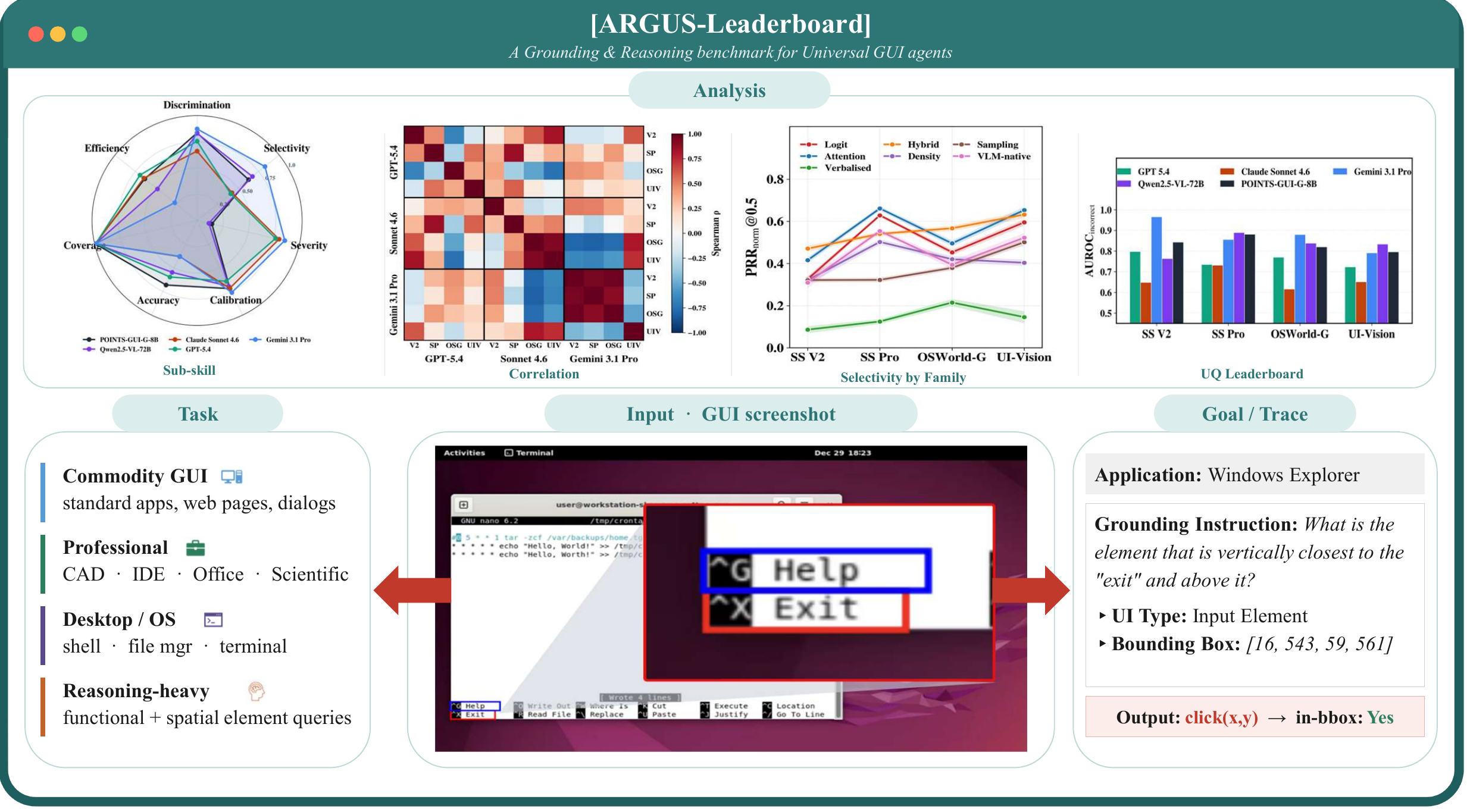
这张 overview 放在附录,但其实最能说明论文的位置。Argus 把任务限定在 single-step executable GUI grounding:输入 GUI screenshot 和 grounding instruction,模型输出 click(x, y),然后为这个预测配套计算不确定性分数。它不是 OSWorld、AndroidWorld、VisualWebArena 那类长程交互 benchmark,也不声称解决规划和恢复;它解决的是更底层但很关键的问题:当一个 GUI Agent 准备点击时,系统有没有办法判断“这一下可能不靠谱”。
这篇论文在 GUIAgent 谱系中的位置
放在 GUIAgent / computer-use agent 的谱系里,Argus 位于三个方向的交叉点。
第一,它继承的是 GUI grounding 方向。ScreenSpot、ScreenSpot-Pro、OSWorld-G、UI-Vision-EG 这类数据集都在问:给定目标描述,模型能不能定位到正确 UI 元素。Argus 没有重新定义目标框,而是在同一个预测结果上叠加不确定性评估。
第二,它借用了 VLM / LLM uncertainty quantification 的工具箱。论文把 logit、sampling consistency、hybrid、attention、hidden-state density/probe、verbalised confidence、VLM-native perturbation 等方法放到同一个矩阵里比较。也就是说,它不是只提出一个新分数,而是在问:已有 UQ 方法换到 GUI click grounding 后,哪些还可靠,哪些会失效。
第三,它对 computer-use agent 的部署语义更敏感。一个普通分类器的 UQ 可以服务于“低置信样本交给人工标注”;GUI Agent 的 UQ 则对应“这个点击要不要执行”。这就把问题从离线 ranking 推向在线控制:拒绝执行、重新观察、局部放大、调用结构化 selector、转人工确认,都是 UQ 分数下游要承担的动作。

Table 1 的价值在于划清了边界。Argus 不是通用 VLM hallucination benchmark,也不是只看静态图文问答置信度。它要求预测能够落成一个 GUI click,并给出 per-item records、splits、UQ scores、closed-source API responses 和分析脚本。对工程团队来说,这种“每个样本都有预测、分数、错误距离、可复算脚本”的组织方式,比单一总分更适合接入测试平台。
任务设定:不是“模型准不准”,而是“不准时能不能知道”
Argus 的核心实验矩阵分为两层。
Open-weight 部分覆盖 4 个 VLM / GUI grounding agent 与 4 个 GUI grounding datasets。论文里用的缩写包括 Qwen2.5-VL-7B、Qwen2.5-VL-72B-AWQ,以及两个 GUI grounding specialist;数据侧包括 ScreenSpot-V2、ScreenSpot-Pro、OSWorld-G 和 UI-Vision-EG。这个设定允许作者访问 logits、hidden states、attention maps 等内部信号,所以能评估完整的 27 种 UQ 方法。
Closed-source / API-only 部分覆盖 3 个 frontier vendors 与 4 个数据集。这里拿不到 logits、hidden states 和 attention maps,只能使用 response-level 信号,例如采样一致性、文本自评置信度、paraphrase / image perturbation 后的一致性等。因此 closed-source 只保留 8 种 harmonised 方法。
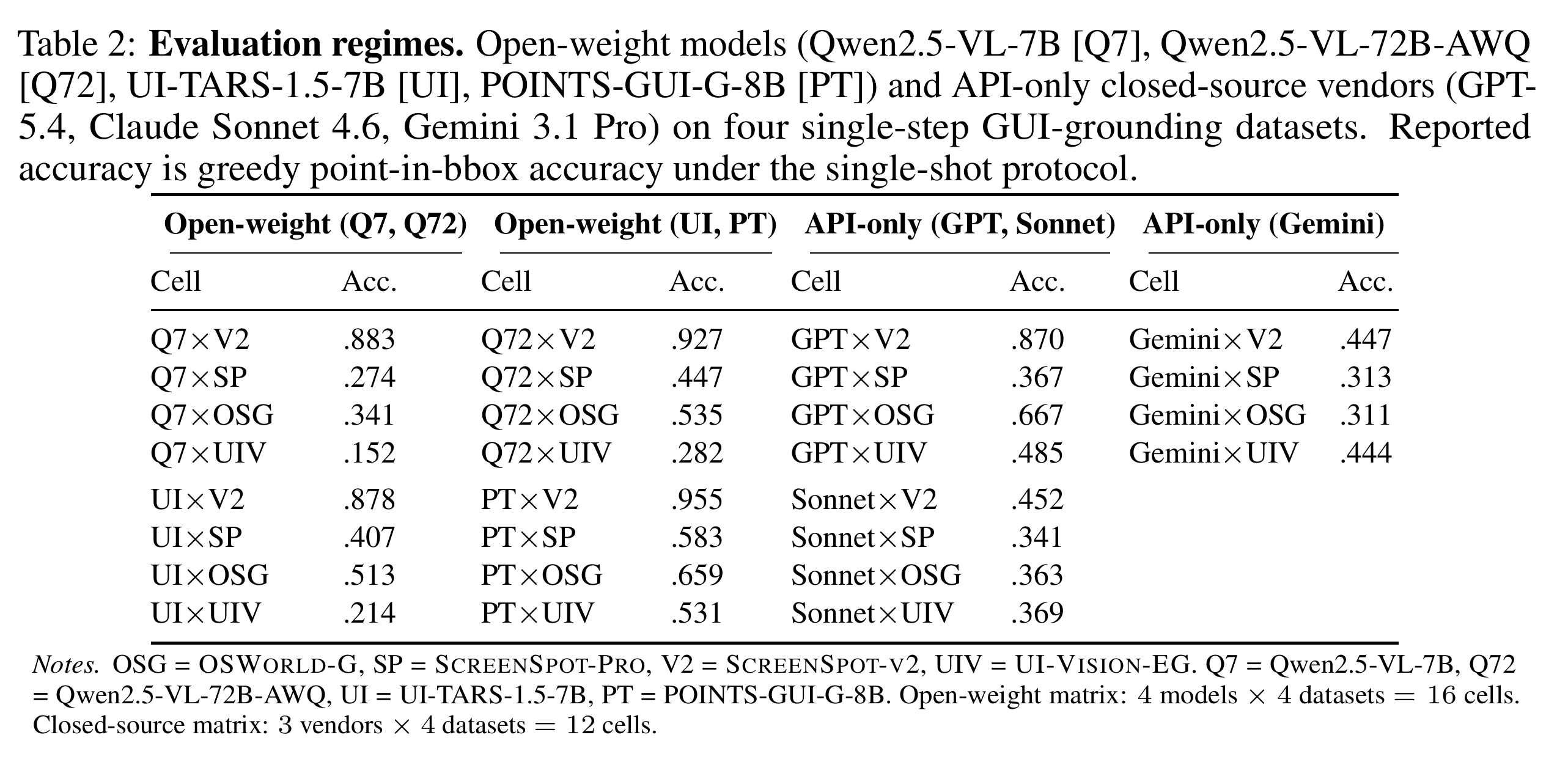
这个区分很重要。很多 UQ 论文默认可以访问模型内部状态,但实际 APP 自动化测试平台常常接的是商业 VLM API,或者接入的是一个封装好的 GUI Agent 服务。此时 hidden state、token logit、attention head 全部不可见。Argus 的结论也因此分成两套:open-weight 里表现稳定的方法,不能直接照搬到 API-only 系统。
论文还把 protocol 写得比较细:评估的是单步 executable click;泄漏控制、metric、release artifact、split 方式都有说明。
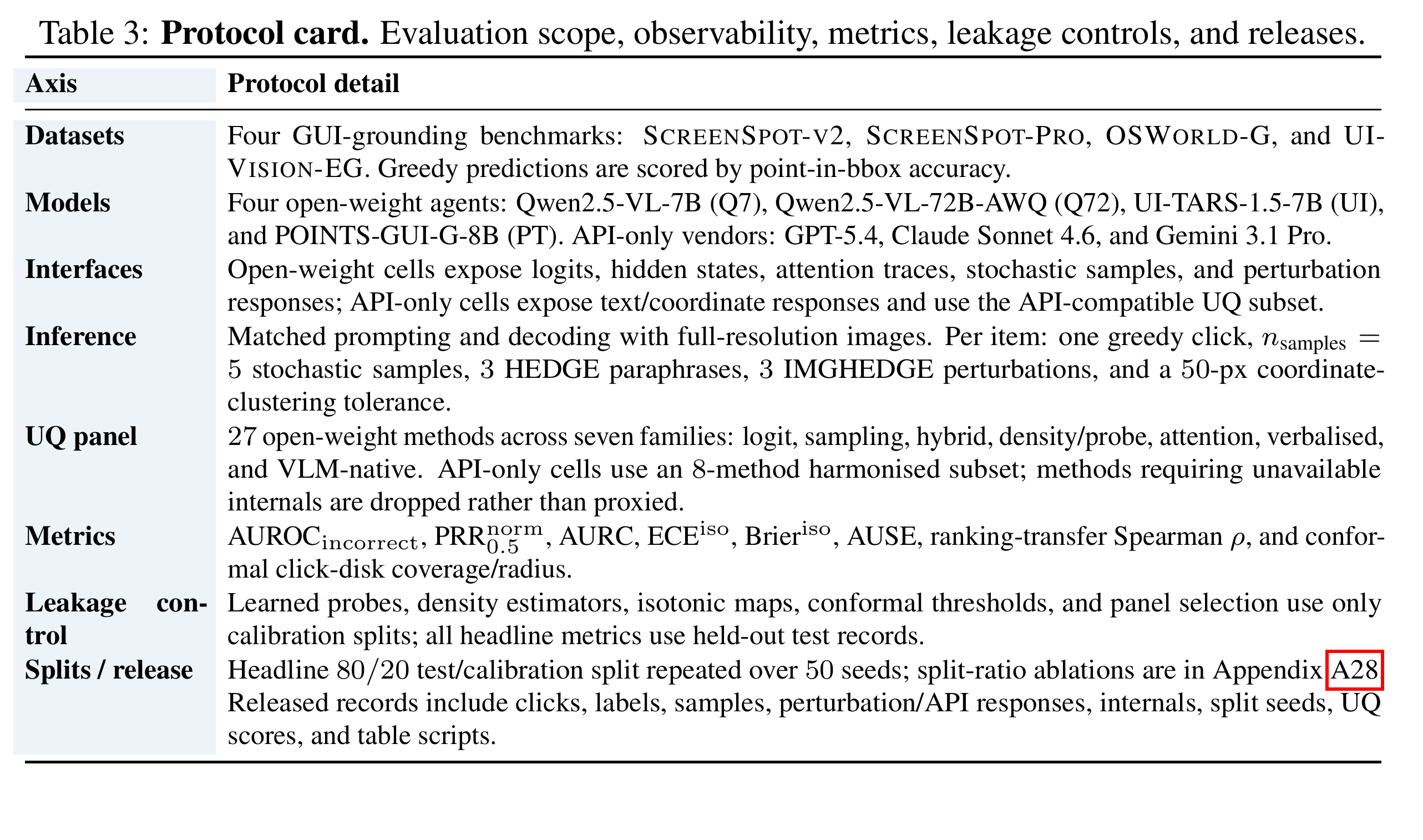
对 QA 系统来说,Table 3 比很多 headline score 更有参考价值。GUI Agent 的测试结论经常会被环境状态、截图分辨率、目标框定义、模型调用策略和重试逻辑污染。Argus 至少把这些因素摆到台面上:哪些信号能用、哪些不能用、指标到底回答什么部署问题。
方法矩阵:27 种 open-weight UQ,不是在比一个万能分数
Argus 把 UQ 方法分成几个 family:
- Logit family:最大 softmax probability、perplexity、token entropy、sequence probability 等;
- Sampling family:多次采样后看点击聚类、一致性、semantic entropy、lexical similarity;
- Hybrid family:把生成概率和采样一致性组合起来,例如 CoCoA、CCP;
- Attention family:用 attention head 或 attention chain 推导不确定性;
- Density / probe family:基于 hidden state 的 Mahalanobis、relative Mahalanobis、SAPLMA、SEP 等;
- Verbalised family:让模型直接给 confidence 或判断自己的答案是否正确;
- VLM-native family:对 instruction 或 image 做扰动,看输出是否稳定。
这套分类的好处,是避免把“不确定性”讲成一个抽象概念。不同方法依赖的接口不同,计算成本不同,下游适配也不同。比如 hidden-state density 方法在 open-weight 模型上可能很强,但商业 API 根本拿不到 hidden state;verbalised confidence 在 API-only 场景可用,但模型说自己有信心并不等于坐标真的准。
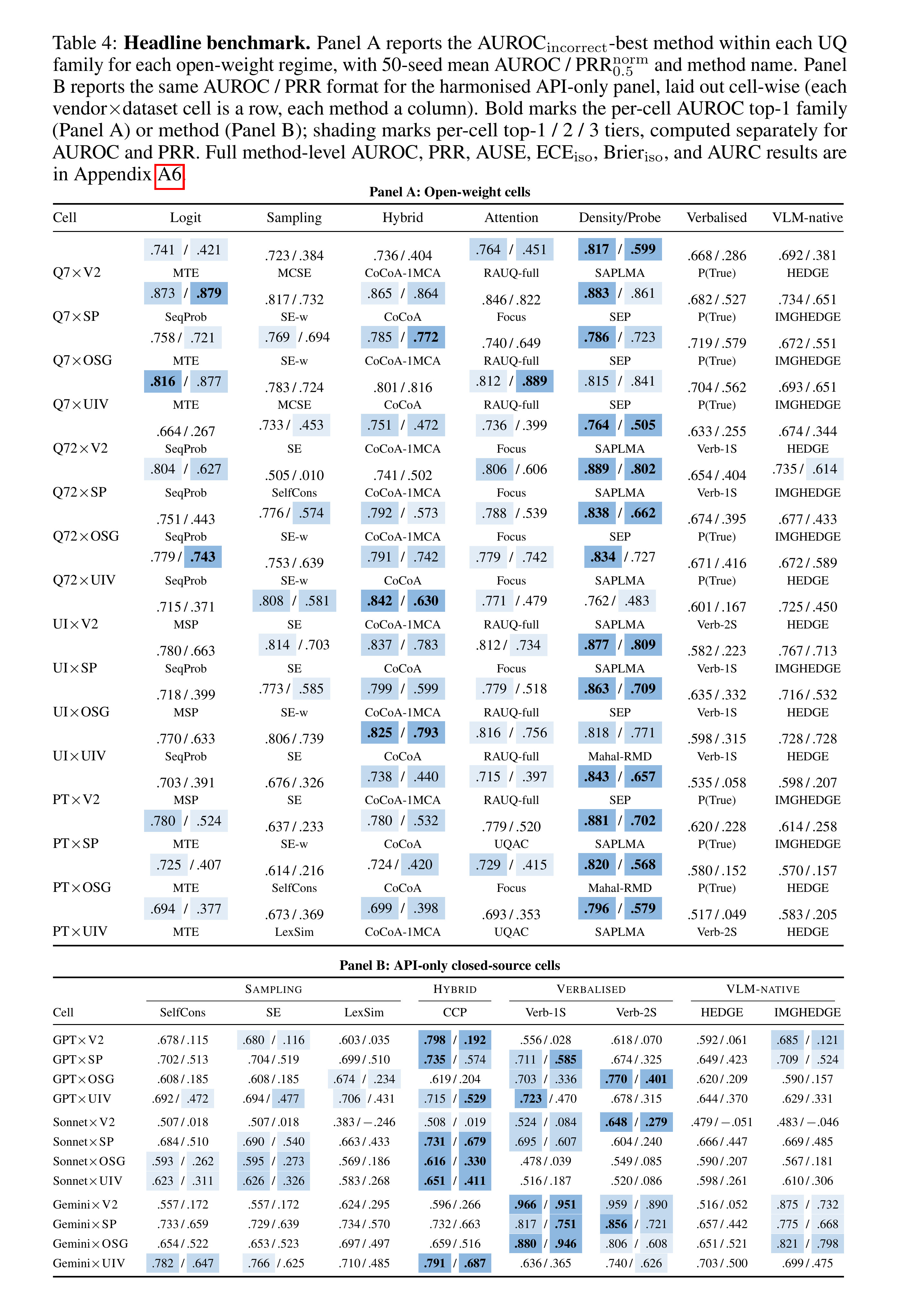
Table 4 是论文主证据之一。结论不是“某个方法最好”,而是更细:
- 在 open-weight regime 中,hidden-state / density-probe 方法整体更稳定,尤其 SAPLMA、SEP、Mahal-RMD 这类方法经常进入高位;
- CoCoA-1MCA、Focus、sampling-based scores、verbalised self-assessment 分别在特定 regime 里有优势;
- API-only closed-source regime 中,可用方法集合被压缩,CCP、Verbalised-1S / 2S 等 response-level 信号更常成为候选;
- AUROC、PRR、AUSE、calibration 并不会总是选择同一个 winner。
这点对工程落地很关键。如果平台目标是“发现可能点错的步骤”,AUROCincorrect 更相关;如果目标是“把错得更离谱的样本排到前面”,miss severity / AUSE 更相关;如果目标是“把分数解释成风险概率”,ECE / Brier 和校准更重要。一个分数在错误检测上好,不代表它能直接用作安全门限。
跨 regime 迁移:固定模型内比较稳,跨接口就会塌
论文最值得关注的结果,是 UQ ranking 的迁移性。
在 open-weight 矩阵里,如果模型固定,只换数据集,UQ 方法排序比较稳定。论文报告的 mean cross-cell Spearman ρ 是 0.705,最高能到 0.969。这说明在同一个模型 family 下,从一个 GUI grounding 数据集学到的 UQ 方法偏好,可能迁移到另一个数据集。
但跨模型类别、跨可观测接口时,这个稳定性明显下降。尤其 open-weight 到 closed-source 的 8-method intersection,mean cross-tier transfer 只有 ρ = +0.08,bootstrap 95% CI 是 [-0.219, +0.373],包含 0。换句话说,把 open-weight 上排出来的 UQ 方法顺序直接搬到商业 API agent 上,统计上很难说有稳定收益。
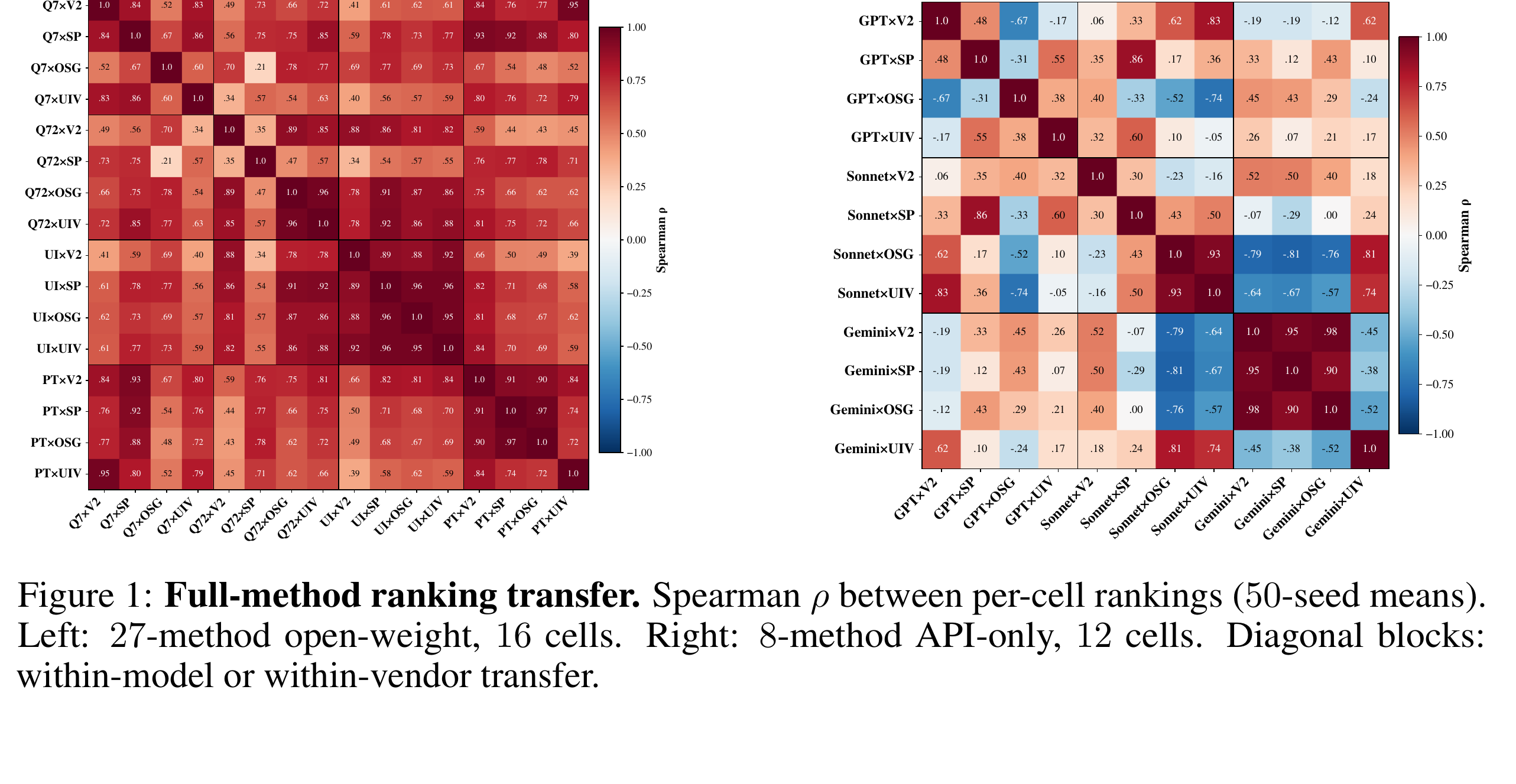
这张 heatmap 对移动端 QA 有很强的提醒。很多团队会先在公开 benchmark 上选一个“最优置信度分数”,然后接到自己的 App 测试 agent 里。但 Argus 说明,UQ 不是方法自己的固有属性,而是方法、模型、数据集几何、可观测接口和部署目标共同决定的结果。换模型、换供应商、换 App UI 形态后,应该重新在目标校准集上排序,而不是照搬论文里的 top-1。
论文还分析了 vanilla VLM 到 GUI specialist 的变化。attention、verbalised、VLM-native family 在 vanilla → specialist transitions 上都有下降;density/probe family 最稳定,mean ΔAUROC = +0.008,跨多个 transition 基本保持平。这个结果也很符合直觉:GUI fine-tuning 改变了模型输出分布和注意力模式,原本适用于通用 VLM 的 token / attention 信号未必还可靠。
Conformal click disks:从“风险分数”走到“空间安全区域”
Argus 不只看 UQ score 的排序,还进一步问:这些分数能不能转化成可执行的空间区域。论文使用 split-conformal click disks,在预测 click 周围给出一个 disk,目标是让 disk 以指定覆盖率包含真实 target-box center。
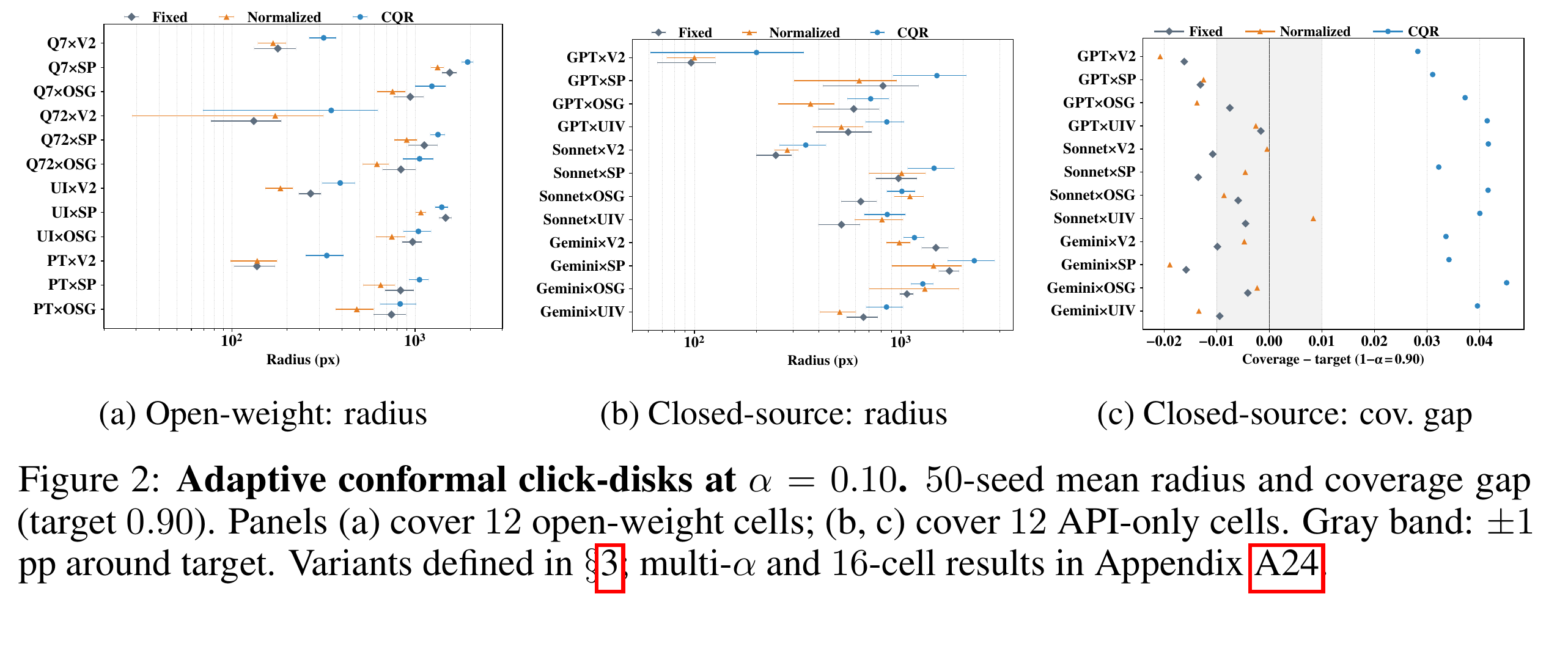
这个图把 UQ 从“这个点可不可靠”推进到“如果要执行,安全半径需要多大”。结果里有几组数字值得记住:
- Disk-Normalized 在不少 open-weight cells 上能缩小半径,例如 PT×OSG 从 743 px 到 481 px,减少 35%;Q72×OSG 从 837 px 到 620 px,减少 26%;UI×SP 从 1469 px 到 1076 px,减少 27%;
- 论文总结里提到,合适的 plug-in UQ 校准后,Disk-Normalized 可以把半径缩小 40–60%;
- 但 CQR 更保守,可能 over-cover;API-only / vendor 行为变化下,也会出现 coverage mismatch。
这件事对 APP 自动化测试很实用。比如一个 Agent 想点“确认支付”“删除草稿”“授权通讯录”“发布内容”这类按钮,只知道 top-1 坐标不够。系统应该知道:目标附近的不确定半径有多大、这个半径内是否还有危险控件、当前页面是否允许自动执行。如果 conformal disk 大到覆盖多个按钮,正确动作就不该是继续点击,而是触发视觉放大、结构化 selector、deeplink 替代、mock 后端验证,或者人工确认。
论文给出的选择 recipe:先按 regime 选候选,再在目标 split 上重排
Argus 最工程化的一张表是 Table 5。它没有把 benchmark 结果包装成一个固定排行榜,而是给出 regime-aware UQ selection recipe。

这张表可以压缩成几条规则:
- 先看接口:如果 hidden states 可用,把 SAPLMA / SEP / Mahal-RMD 放进候选;如果 API-only,从 CCP、SelfCons、SE、LexSim、Verb-1S、Verb-2S、HEDGE、IMGHEDGE 这些 response-level 方法开始。
- 再看模型类型:specialist GUI agents 上,不要默认 logit 和 lexical-overlap score 仍然可靠;模型 fine-tuning 会改变 family preference。
- 按目标选指标:拒绝执行看 AUROC / PRR,严重程度排序看 AUSE,风险解释看 ECE / Brier。
- 迁移要谨慎:固定模型跨数据集可以复用 prior panel;跨模型 family 或接口变化,必须在目标 calibration split 上重排。
- 空间执行要检查 coverage:Disk-Normalized 可以显著缩小半径,但必须确认 coverage 没有在目标场景退化。
这比“使用最佳 UQ 方法”更像真实工程建议。APP 自动化里的目标也不是单一的:回归测试可以容忍保守拒绝,探索测试可能更看重覆盖率,支付/隐私/删除流程则需要极低误触风险。不同目标下,UQ 分数的使用方式应该不一样。
对 APP 自动化测试 / 移动端 QA 的启发
Argus 对移动端 QA 最直接的启发,是把 GUI Agent 的执行策略从“预测并点击”改成“预测、估计风险、再决定动作”。
在 Appium、UIAutomator、XCUITest、Maestro 这类传统自动化里,执行动作通常依赖确定性 selector 或脚本步骤。GUI Agent 加入后,视觉 fallback 能覆盖 selector 失效、WebView、动态卡片、跨 App 流程、系统弹窗等场景,但风险也随之增加:模型给出的坐标并不总是可信。
一个更稳的测试 agent 可以把 Argus 里的思路接到执行链路中:
- 对普通探索动作,允许较低门槛执行,但记录 UQ score、截图、坐标和后续状态;
- 对登录、支付、删除、发布、权限授权、隐私设置等高风险动作,提高拒绝门槛;
- 对低置信度点击,先做局部 crop / zoom、OCR、accessibility tree 查询或 selector fallback;
- 对 WebView / Hybrid 页面,把视觉 UQ 和 DOM / network / mock server 状态一起作为断言证据;
- 对失败 case,不只记录最终截图,还记录“执行前 UQ 是否已经提示风险”。
这样一来,UQ 不只是一个模型指标,而会进入测试平台的调度策略。比如同一个“点击提交”动作,可以根据风险分数走三条路径:直接执行、视觉复查后执行、转人工确认。对移动端回归测试而言,这比盲目提高模型准确率更可控。
还有一个容易忽略的点:Argus 评估的是单步 click,不是完整任务成功率。它能帮助我们把“这一步是否可靠”说清楚,但不能替代 end-to-end oracle。真正的 APP QA 仍然需要页面状态、接口返回、日志、数据库/mock server、崩溃/ANR、业务状态变化一起验证。UQ gate 只是降低错误动作进入系统的概率,不是最终断言。
可能被高估的部分
Argus 的价值很清楚,但边界也需要保留。
第一,它不是长程 computer-use agent benchmark。论文主动把任务限定在 single-step executable GUI grounding。这个设定干净,方便比较 UQ 方法,但不会覆盖多步规划、历史记忆、动作恢复、环境 reset、登录态和跨页面业务流。不能因为某个 UQ 方法在 Argus 上表现好,就推断它能让 AndroidWorld 或真实 App E2E 任务成功率提升。
第二,UQ 方法的胜负依赖可观测接口。open-weight 里稳定的 density/probe 方法,商业 API 场景可能完全用不了;API-only 里表现不错的 verbalised confidence,也可能受 prompt、vendor policy、temperature 和 response formatting 影响。工程上要把“论文推荐”当作候选,而不是直接上线的门限。
第三,conformal click disk 的覆盖假设需要目标分布稳定。移动 App 的 UI 会被 AB 实验、灰度、广告、权限弹窗、键盘、深色模式、机型分辨率、系统版本影响。校准集和线上测试分布一旦不一致,coverage 就可能退化。论文也明确指出 mismatch 下 coverage 需要重新检查。
第四,Argus 还没有把 UQ 和恢复策略闭环起来。知道“不确定”之后,系统下一步该做什么,仍然取决于工程设计:放大截图、换 selector、调用 deeplink、检查后端状态、重跑步骤、还是请求人工确认。论文给了判断风险的仪表盘,但没有给出完整驾驶策略。
真正贡献:把 GUI Agent 的可靠性问题拆成可测的执行前风险
这篇论文真正推进的是一条可靠性轴:GUI Agent 不应该只报告“点中了多少”,还应该报告“哪些点击在执行前就能识别为高风险”。
这对 GUIAgent 领域是有意义的。过去很多工作把精力放在更强模型、更准 grounding、更真实 benchmark 上;Argus 关注的是部署中不可回避的问题:即使模型整体准确率不错,系统也必须知道什么时候不要相信它。尤其在 mobile QA 里,拒绝一次低置信度点击,往往比多完成一个不可靠步骤更有价值。
更重要的是,Argus 证明了 UQ 选择不能脱离 regime。固定模型跨数据集的 ranking transfer 可以很强,最高 ρ 到 0.969;但 open-weight 到 closed-source 的 cross-tier transfer 平均只有 +0.08。这个差距足以提醒工程团队:每次换模型、换供应商、换 UI 形态,都应该重新做小规模 calibration,而不是复用旧门限。
总结
Argus 把 GUI Agent 里的一个工程直觉做成了系统 benchmark:模型给出点击坐标后,平台还需要知道这个点击的风险。它比较了 27 种 open-weight UQ 方法、8 种 API-only 方法,分析 ranking transfer、错误检测、选择性执行、校准和 conformal click regions,最后给出 regime-aware selection recipe。
对 APP 自动化测试来说,最值得带走的不是某个具体 UQ 分数,而是执行链路的改造方式:
- top-1 坐标只是候选动作,不是执行许可;
- UQ score 应该接入点击前 gate;
- 高风险页面要有更保守的门限和人工/结构化工具兜底;
- 换模型、换 App、换 UI 分布后要重新校准;
- 最终 oracle 仍然要结合 UI、后端、日志、网络和 crash/ANR 信号。
GUI Agent 真正进入测试平台时,可靠性不会只来自更大的模型。它还来自这些看似朴素的机制:知道自己可能错,知道错了会有什么后果,并在执行前把风险拦下来。