MemGUI-Agent 论文解析:长程 Mobile GUI Agent 的瓶颈,正在从点屏转向上下文治理
从 GUIAgent / mobile QA 视角解析 MemGUI-Agent:ConAct 把历史折叠、UI 记忆和动作生成放进同一个端到端策略,MemGUI-3K 用 2956 条长程轨迹监督模型学习上下文管理,并讨论它对 APP 自动化测试、移动端 QA 与长流程回归的工程启发。
论文:MemGUI-Agent: An End-to-End Long-Horizon Mobile GUI Agent with Proactive Context Management
arXiv:2606.19926v1,2026-06
项目页:https://memgui-agent.github.io/
代码:kwai/MemGUI-Agent
数据集:lgy0404/MemGUI-3K
模型:lgy0404/MemGUI-8B-SFT
作者:Guangyi Liu, Gao Wu, Congxiao Liu, Pengxiang Zhao, Liang Liu, Mading Li, Zhang Qi, Mengyan Wang, Liang Guo, Yong Liu
机构:Zhejiang University, Kuaishou Technology
一句话结论:MemGUI-Agent 真正推进的不是“再让模型多点几步手机屏幕”,而是把长程移动 GUI 任务中的上下文管理变成可学习、可执行、可评测的动作协议;这对 APP 自动化测试最直接的启发是:长流程稳定性不能只靠更强 VLM,还要把中间事实、已完成步骤、失败恢复和断言证据做成一等状态。
MemGUI-Agent 抓住了 mobile GUI agent 里一个越来越明显的问题:短任务里,模型失败常常是看错控件、点错位置;长任务里,模型失败更多是忘了前面查到什么、忘了哪些步骤已经做过、跨 App 后丢掉关键事实,或者把越来越长的 ReAct 轨迹塞进 prompt,最后上下文变成噪声。
这和 APP 自动化测试的痛点很像。一个简单的“打开页面并点击按钮”可以靠 Appium 选择器、Maestro flow 或 VLM 点屏解决;但一个真实回归流程往往要跨搜索、详情页、表单、权限弹窗、联系人、短信、地图、支付前置页、WebView 和本地文件。此时最容易出问题的不是某一步“会不会点”,而是系统能不能记住:哪个账号、哪个商品、哪个地址、哪个验证码、哪个表单字段、哪些步骤已经完成、哪些副作用绝对不能发生。
MemGUI-Agent 的核心方案叫 ConAct(Context-as-Action)。它把上下文管理从外部规则或被动日志,改成模型每一步都要显式输出的动作:折叠历史、写入/更新/删除 UI 记忆、描述当前屏幕事实,并继续生成下一步 GUI action。论文同时发布了 MemGUI-3K,包含 2,956 条成功移动 GUI 轨迹、82,103 个任务步骤、64,430 个 evaluator-approved reasonable steps,用于训练 MemGUI-8B-SFT。
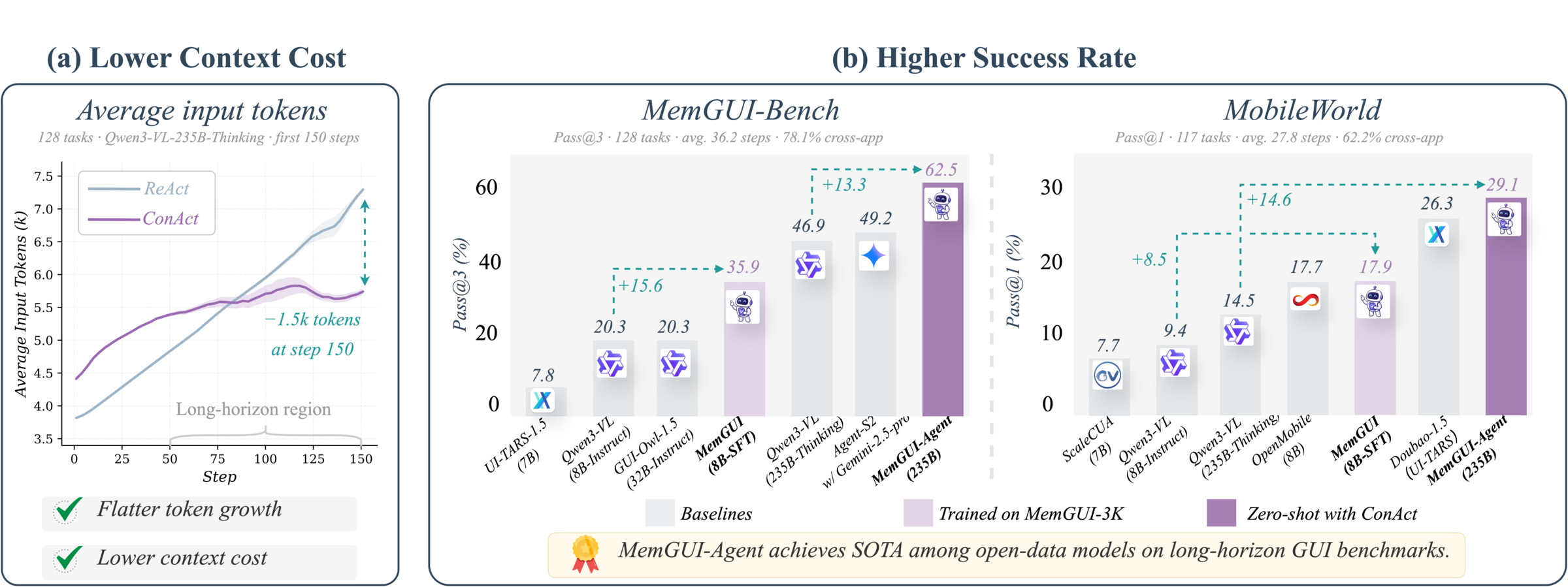
这张主结果图很关键。左侧说明 ConAct 的输入 token 随步骤增长更慢,到 150 步附近比 ReAct 少约 1.5K input tokens;右侧说明它不是简单“少放点历史”,而是在 MemGUI-Bench 与 MobileWorld 上同时提升 zero-shot 235B 和训练后的 8B 设置。对移动端 QA 来说,这对应一个很现实的判断:长流程自动化不是把所有截图、动作和日志无限堆进上下文,而是要把它们压缩成可复用状态。
这篇论文在 GUIAgent 谱系中的位置
站在 GUIAgent / computer-use agent 领域看,MemGUI-Agent 的位置比较清楚:它不是新的静态 grounding benchmark,也不是只靠 prompt engineering 包一层 mobile agent,而是把 long-horizon context management 放到 mobile GUI agent 的核心能力轴上。
和几个相邻方向相比:
- 相对 GUI grounding:ScreenSpot、GUI-Actor、UI-AGILE、GUI-G1 等方向主要回答“目标元素在哪里、动作参数怎么更准”。MemGUI-Agent 关注的是另一层:动作做对以后,信息怎样跨 50、100、150 步保存下来。
- 相对 AndroidWorld / MobileWorld:AndroidWorld 平均步数相对短,MobileWorld 与 MemGUI-Bench 更强调长程、多 App、信息保持。论文指出 GUI-Owl-1.5-8B 在 AndroidWorld 上有 71.6%,但在 MobileWorld 降到 38.2%,在 MemGUI-Bench 只有 11.7%。这组数字把“长程上下文”从主观感觉变成了可测问题。
- 相对 AndroidDaily / GRADE:AndroidDaily 关心真实闭源 App 中如何评测轨迹和过程证据;MemGUI-Agent 关心 agent 自身如何维护上下文。前者更像 QA oracle,后者更像执行策略内部的状态治理。两者结合,才更接近可部署的移动端自动化闭环。
- 相对 MementoGUI / memory agent:外部 memory 可以缓解遗忘,但常把“何时写、写什么、怎么更新”交给规则或独立模块。MemGUI-Agent 的立场更激进:memory action 本身应由同一个端到端策略学习。
- 相对 OSWorld / VisualWebArena / SaaS-Bench:桌面和 Web 环境常能用文件、DOM、后端状态或工具调用做验证;移动端 App 更弱可观察,很多时候只有截图、动作反馈和有限系统接口。MemGUI-Agent 处理的就是这种弱可观察长程控制。
因此,这篇论文真正推进的是一个能力边界:GUI agent 不只需要 perception、grounding、planning,还需要 上下文生命周期管理。哪些信息应该进入长期 UI memory,哪些历史应该被折叠,哪些最近步骤要保留完整细节,这些都不再是 prompt 模板里的边角料,而是动作空间的一部分。
问题定义:ReAct 日志为什么撑不住长程移动任务
传统 mobile GUI agent 常用 ReAct 风格:每一步记录 observation、thought、action、result,然后下一步把历史继续塞进 prompt。短任务中这样很自然;但任务一长,会出现三个问题。
第一是 prompt explosion。历史线性增长,模型每一步都要重新读大量旧信息,成本和延迟上升。移动端动态 UI 对延迟很敏感,慢一步可能就碰到广告、弹窗、页面刷新或会话超时。
第二是 information dilution。真正关键的事实,比如电话号码、商品价格、日程时间、联系人邮箱、验证码、搜索结果标题,会被大量普通动作日志淹没。模型不是完全没有看到,而是难以在后续关键步骤把它稳定取出来。
第三是 mechanical truncation 的副作用。简单截断最早历史或保留最近 N 步,会把跨 App 任务中最重要的前置事实删掉。比如先在 Google Maps 查到公司电话,再去 Contacts 创建联系人;如果电话在跳转后被截掉,后续模型可能猜一个看似合理但错误的号码。
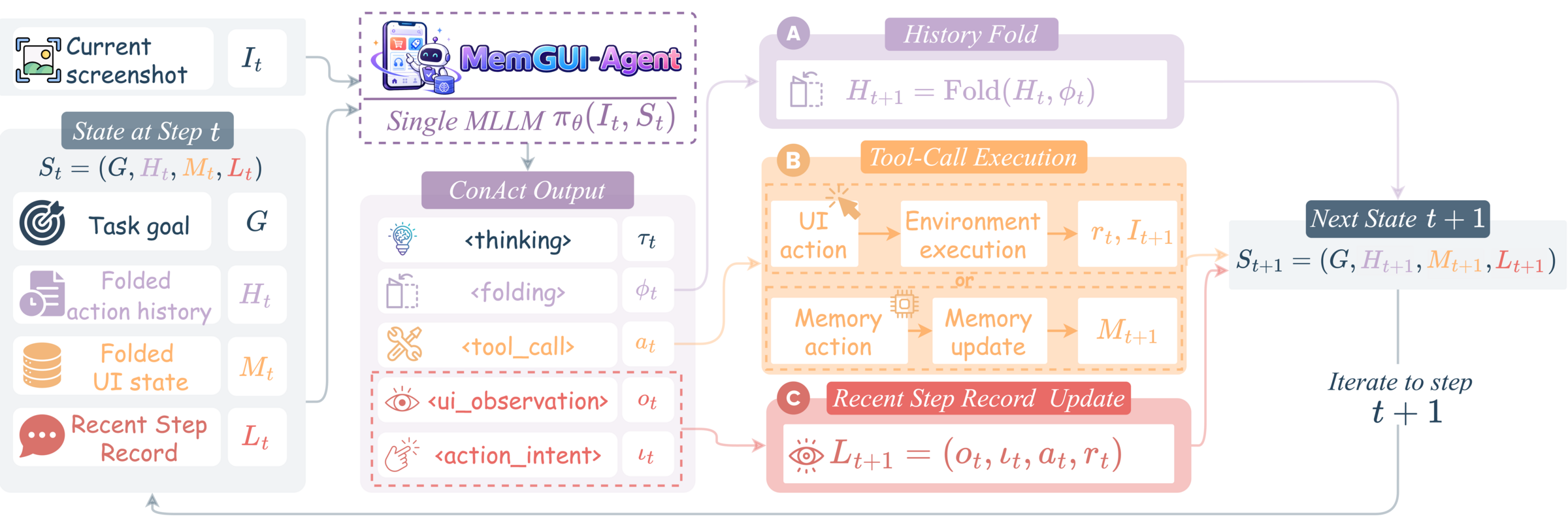
这张图是论文方法的核心。ReAct 把每步记录被动追加,ConAct 则维护三个结构化字段:Folded Action History、Folded UI State 和 Recent Step Record。这三个字段分别对应长流程自动化中的三类信息:已经完成的流程摘要、必须跨页面保存的业务事实、以及下一步动作仍然需要的局部上下文。
对 APP 自动化测试来说,这个拆分比“加一个 memory 模块”更有启发。测试系统里也应该区分:
- 流程摘要:已经登录、已经进入商品详情、已经选择配送地址;
- 业务事实:商品名、价格、库存、联系人电话、订单号、优惠券状态;
- 局部上下文:当前页面刚出现的弹窗、输入框焦点、最近一次点击结果、加载状态。
把这三类信息混在同一个日志里,后面很难做断言、恢复和复盘。
ConAct:把上下文管理变成动作协议
ConAct 的形式化状态是:
S_t = (G, H_t, M_t, L_t)其中:
G是任务目标;H_t是 Folded Action History,保存被压缩后的已完成历史;M_t是 Folded UI State,保存持久 UI 事实;L_t是 Recent Step Record,保存最近一步的局部细节。
每一步,模型不只输出一个 click/type/swipe,而是输出五类内容:reasoning、folding directive、tool call、UI observation、action intent。也就是说,模型要同时决定“怎么操作手机”和“怎么更新自己的上下文”。
这张图值得反复看,因为它把 memory 从“旁路模块”变成了 action policy 的一部分。tool_call 可以是 UI action,也可以是 memory action,例如 memory_add、memory_update、memory_delete。这意味着模型需要学习:什么事实值得长期保存,什么时候旧事实已经过期,什么时候只需要把最近几步折叠成摘要。
论文里一个重要设计是:UI memory 存完整信息,而不是含糊引用。比如保存完整电话号码、完整商品规格、完整文本片段,而不是“刚才那个号码”或“上面那个价格”。这点对移动 QA 很关键。断言和恢复不能依赖语义模糊的记忆,否则 replay 时会变成“看起来对,但无法验证”。
如果把 ConAct 映射到测试工程,可以得到一个更实用的执行状态模型:
| ConAct 字段 | Mobile GUI Agent 含义 | APP 自动化测试里的对应物 |
|---|---|---|
| Folded Action History | 已完成步骤的压缩摘要 | 测试阶段、页面路径、已处理目标 |
| Folded UI State | 跨页面/跨 App 持久事实 | 订单号、账号、价格、联系人、表单值、后端 ID |
| Recent Step Record | 最近动作和观察 | 当前截图、控件状态、等待结果、弹窗状态 |
| memory actions | 增删改持久事实 | 更新测试上下文、保存 oracle 证据、清理过期变量 |
| folding directive | 历史压缩策略 | 日志摘要、轨迹切片、失败复盘摘要 |
真正麻烦的不是把这张表写出来,而是让 agent 在执行中稳定维护它。MemGUI-Agent 的价值就在这里:它把状态维护做成可训练目标,而不是靠人工写几条 prompt 规则。
MemGUI-3K:用长程轨迹教模型“何时记、记什么、怎么折叠”
MemGUI-3K 是论文的第二个关键贡献。它不是普通的点击轨迹集合,而是带 ConAct annotations 的长程移动 GUI 数据集。数据来自 MemGUI-Bench 的 128 个 seed tasks,经过 entity substitution、memory-operation augmentation、task simplification 扩展,再由 Qwen3-VL-235B-Thinking teacher 在 snapshot-based Android 环境中执行,之后用 MemGUI-Eval 做 trajectory-level 和 step-level 过滤。
最终数据规模包括:
- 2,956 条成功轨迹;
- 26 个 Android apps;
- 82,103 个 task steps;
- 64,430 个 reasonable step-level SFT samples;
- 训练 / 测试按轨迹划分为 90/10;
- 与 128 个 MemGUI-Bench evaluation tasks 做了 zero overlap 检查。
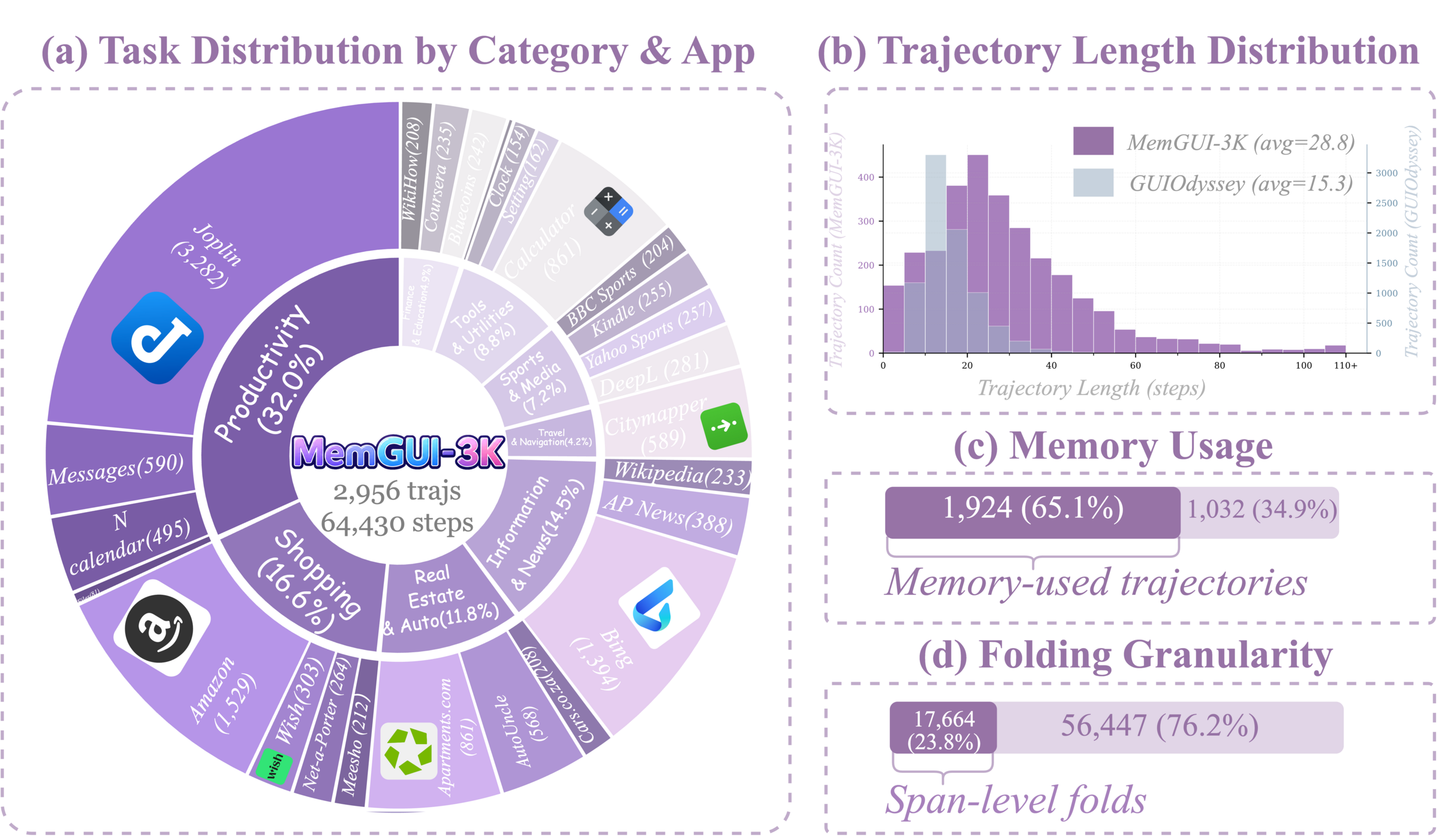
这张统计图说明 MemGUI-3K 的重点不是“多”,而是“长”和“有上下文动作”。论文报告轨迹平均 28.8 步,比 GUIOdyssey 的 15.3 步长约 1.9x;65.1% 的轨迹包含 memory actions;23.8% 的 folding 是 span-level abstraction,平均 span 长度 6.25 步,88.7% 的轨迹至少包含一次 span-level fold。
这些数字有两个含义。
一方面,MemGUI-3K 确实在训练模型做上下文管理,而不只是换一种输出格式。只要轨迹足够长,模型才会遇到“哪些步骤应该折叠、哪些事实应该保留”的真实选择。
另一方面,它也带来边界:数据来自 teacher 成功轨迹和 evaluator-approved reasonable steps,失败恢复、真实 App 漂移、弱网、随机广告、登录态变化、支付/下单副作用等生产环境问题不会自然全部覆盖。对移动端 QA 平台来说,这类数据适合学习 context discipline,但不能直接替代真实灰度包、线上埋点和测试环境中的失败轨迹。
实验结果:上下文管理确实有效,但不是所有模型都能零样本学会
论文有一个很重要的负结果:ConAct 不是简单换 prompt 就能让所有模型变强。Table 1 在不同 Qwen3-VL 尺寸上做 zero-shot ConAct,对较小模型或非 thinking 模型,协议复杂度可能反而拖累表现;明显收益主要出现在 Qwen3-VL-235B-Thinking 上。这说明主动上下文管理本身也是能力,需要监督数据教模型学会。
主结果可以概括为三组。
第一,zero-shot 235B 设置下,MemGUI-Agent-235B 在 MemGUI-Bench 上达到 62.5% Pass@3;在 out-of-distribution MobileWorld GUI-only 上达到 29.1% success rate,比 Qwen3-VL-235B-Thinking baseline 高 14.6 个点。
第二,8B 训练设置下,MemGUI-8B-SFT 在 MemGUI-Bench 上达到 23.4% Pass@1、35.9% Pass@3、30.2% IRR;MobileWorld GUI-only 上达到 17.9% success rate。Hugging Face 模型卡也明确指出,这是论文实验中 best open-data 8B performance。
第三,step-level offline evaluation 显示,MemGUI-3K 不只是提高格式合规率。论文报告 UI action match 从 29.2% 提升到 36.3%,memory timing 的 trigger F1 从 19.9% 提升到 48.0%,format compliance 达到 99.9%。最值得看的是 memory timing:模型学到的不只是“长这样输出”,而是更知道何时把瞬时观察提升为持久记忆。
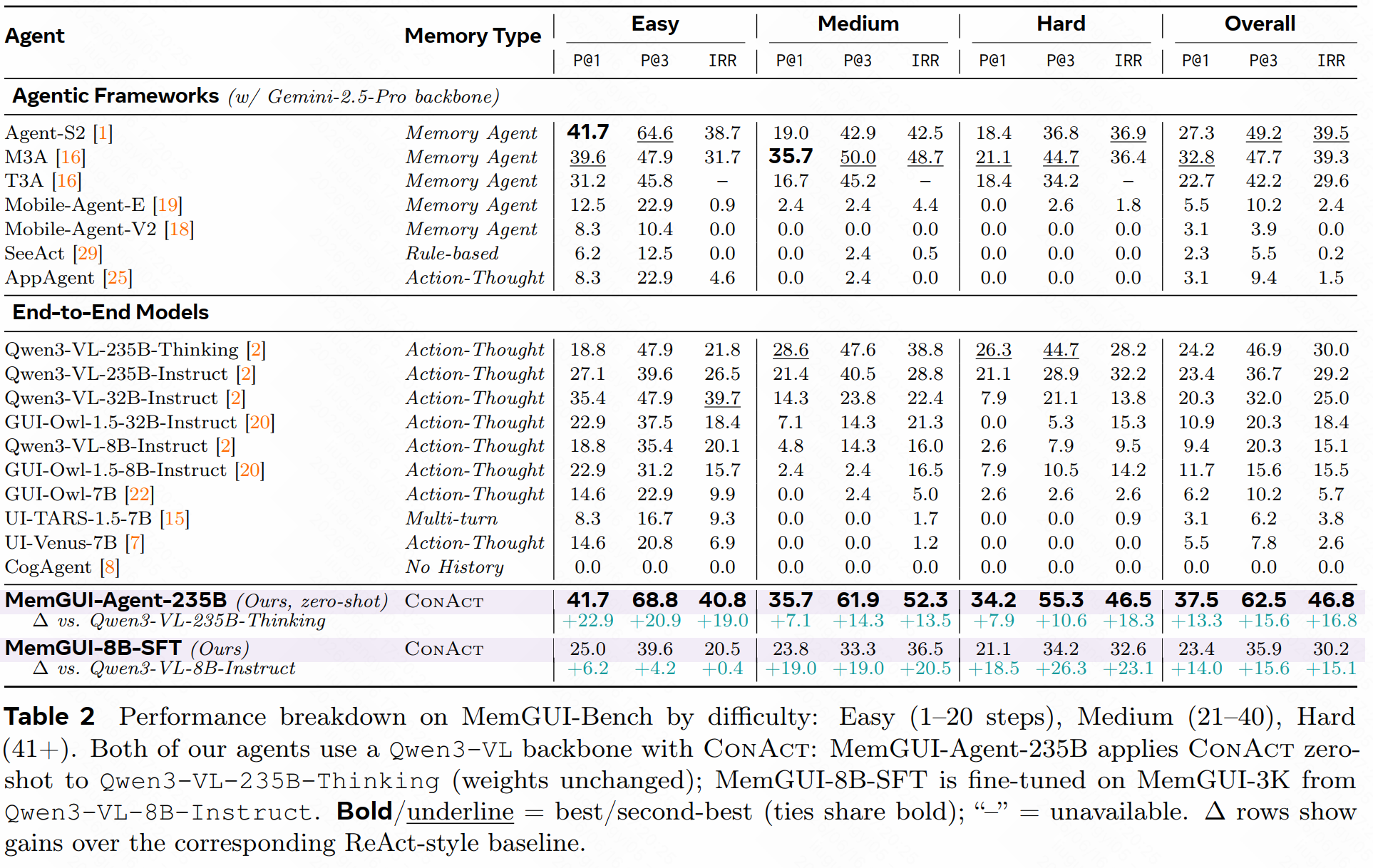
这张表的价值在于把“记忆能力”拆成了不止一个成功率指标。MemGUI-Bench 关注 Pass@1 / Pass@3,也关注 IRR 等记忆相关指标。对测试平台来说,这种拆法很重要:一个 agent 最终成功,可能是靠多次试错;一个 agent 记忆质量好,可能表现为中间变量没有被污染、跨页面事实没有被篡改、错误不会重复发生。只看最终 pass/fail,很难定位到底是 grounding、planning、memory 还是 oracle 出了问题。
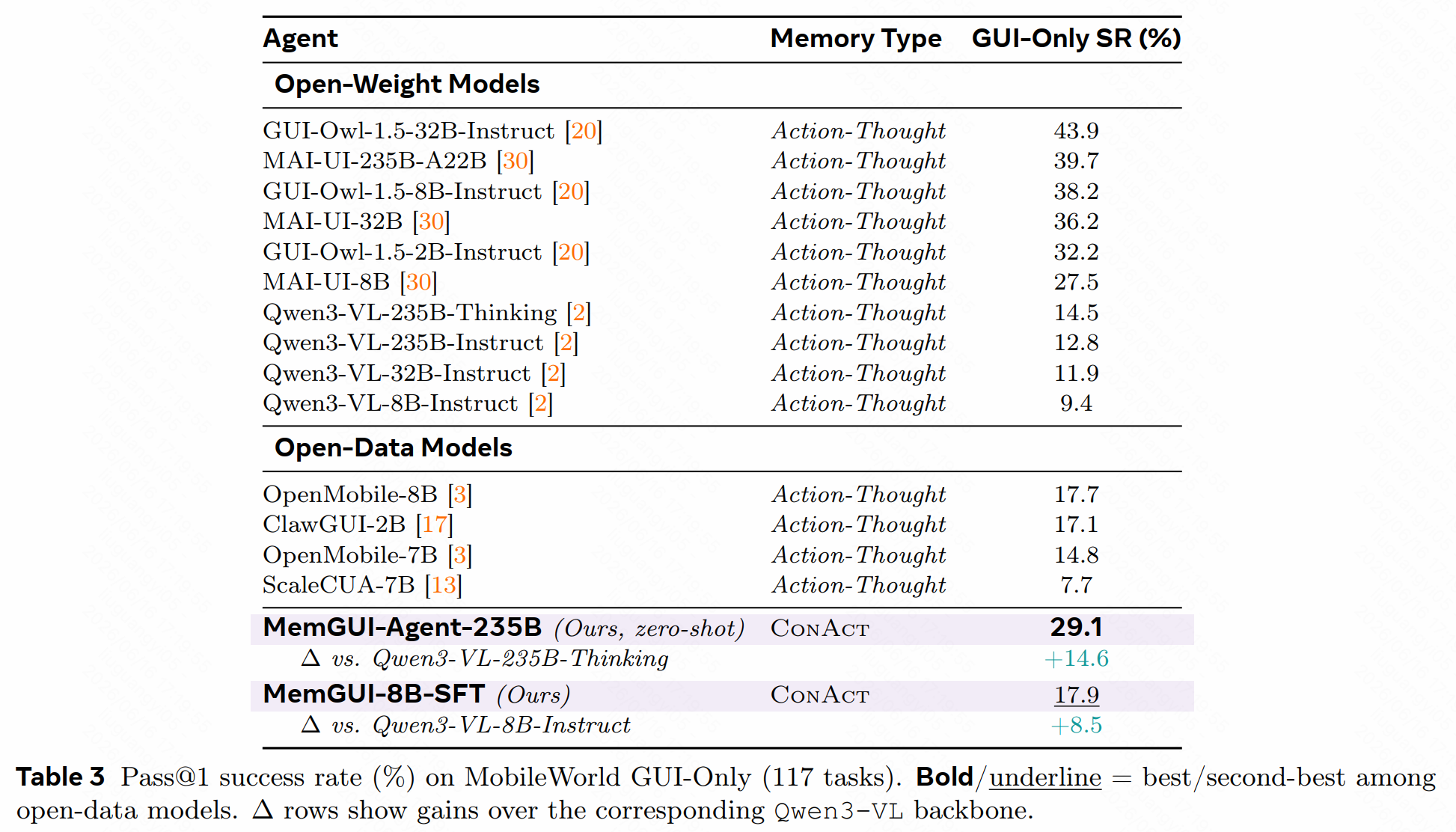
MobileWorld 结果支持了跨环境迁移,但也提醒我们不要过度解读。即使有 ConAct 和 MemGUI-3K,8B 模型在 MobileWorld GUI-only 上仍是 17.9%。这说明长程移动 GUI 的难点远不止 memory:还包括 UI grounding、App-specific prior、工具调用、等待策略、页面漂移、账号状态和 evaluator 差异。
Ablation:三个组件是互补的,不是任选一个就够
论文在 MemGUI-Bench-40 上做了 ConAct component ablation。ReAct baseline 的 Pass@1 / Pass@3 是 5.0% / 27.5%;只加 UI memory actions,Pass@1 到 17.5%;只加 history folding,Pass@1 到 22.5%;只加 self-describing step,Pass@1 到 25.0%;完整 ConAct 达到 40.0% Pass@1 / 62.5% Pass@3,IRR 到 51.0%。
这个结果的含义很直接:
- 只压缩历史不够:压缩能控 token,但不能保证关键事实被保留;
- 只加 memory 不够:有记忆槽位,不代表模型会正确写入、更新、读取;
- 只描述当前步骤也不够:局部 observation 不能替代长期事实;
- 三者组合才接近长程控制所需状态。
对 APP 自动化测试来说,这和真实工程经验一致。只存截图不够,只存日志不够,只存变量也不够。稳定的长流程回归需要三件事一起做:过程摘要、关键状态、局部证据。否则出了 flaky failure,很难判断是页面没加载、选择器漂移、业务状态不一致,还是 agent 把前面查到的信息忘了。
案例:跨 App 事实保持比单步点屏更像真实移动 QA
论文和项目页给了多个案例。典型任务包括:
- 在 AP News 里读 Technology 和 Business 的多篇文章,再到 Joplin 写分节摘要;
- 在 Amazon 收集 iPhone、Galaxy、Pixel 的屏幕、电池、存储信息,再写入 Joplin;
- 在 Google Maps 找到阿里杭州总部电话,再到 Contacts 创建联系人;
- 在 Mastodon 读取 Olivia 的新电话和邮箱,更新 Contacts 后再发短信。
这些任务都不是单纯“点中某个按钮”。它们真正考验的是:查到的信息是否完整保存,跨 App 后是否还可用,长流程中是否知道哪些子目标已经完成,最终输出是否使用真实证据而不是模型幻觉。

这张 case study 对移动端 QA 的启发很强。很多 APP 自动化测试失败并不是因为模型不会点击,而是因为业务事实丢了:优惠券金额、配送地址、联系人、订单状态、搜索结果、支付前置条件、WebView 里复制的内容,在页面跳转后没有被结构化保存。ConAct 的 memory writes 可以看作一种 agent 内部的测试上下文变量;folded history 可以看作可压缩的执行摘要;recent step record 则是下一步动作的局部证据。
如果要把这套思想落到企业移动测试平台,最容易先做的不是训练一个新模型,而是改造执行框架:
- 每个测试任务维护
流程摘要 / 业务事实 / 最近步骤三类状态; - 每一步动作后强制生成可验证 observation,而不是只保存截图;
- 对跨页面事实做结构化变量保存,例如订单号、价格、联系人、文案、接口 trace id;
- 对过期事实做显式删除或版本更新,避免旧状态污染后续断言;
- 失败复盘时把“状态写错 / 状态丢失 / 状态过期 / 动作错误 / oracle 错误”分开归因。
这比简单把 LLM 接到 Appium 上更工程化,也更接近能长期维护的测试系统。
哪些地方可能被高估
MemGUI-Agent 的方向很有价值,但几个边界需要说清楚。
1. ConAct protocol 本身不是免费午餐
论文已经用 Table 1 说明,小模型 zero-shot 使用 ConAct 可能不升反降。原因也合理:输出协议变复杂后,模型必须同时做屏幕理解、动作决策、历史折叠、memory 更新、局部描述。能力不够时,协议会变成额外负担。工程上不能假设“加上三段状态 + 几个标签”就能解决长程任务。
2. MemGUI-3K 主要来自 teacher 成功轨迹,失败世界仍然不够完整
数据集通过 MemGUI-Eval 过滤出 reasonable steps,这有助于训练干净策略,但真实测试平台最需要的往往是失败轨迹:弹窗、弱网、权限异常、账号过期、灰度差异、埋点缺失、后端 500、WebView 白屏、系统打断。若只学习成功轨迹,agent 可能更会“顺利完成标准路径”,但对异常恢复仍然不足。
3. Benchmark 与数据源存在环境族相近的问题
MemGUI-3K 从 MemGUI-Bench seed tasks 扩展而来,论文做了 evaluation tasks 的 zero overlap,也在 MobileWorld 上测试了 out-of-distribution transfer。这些控制是必要的。但从领域判断看,任务风格、App 类别、snapshot-based Android 环境和 evaluator 偏好仍可能共享结构。因此,MemGUI-Bench 的提升应解读为“长程记忆任务族内很有效”,而不是“任意真实商业 App 都同等提升”。
4. UI memory 可能变成新的 hallucination surface
把事实写入 memory 能防止遗忘,但也可能把错误事实固化。比如模型把错误电话、错误价格、错误联系人写进 Folded UI State,后续步骤会更稳定地复用这个错误。测试系统如果借鉴 ConAct,必须给 memory writes 加验证:OCR 置信度、截图证据、接口校验、二次读取、人工审批或 mock backend 对账。
5. 安全和副作用不是主线
论文任务包含联系人、短信、地图、笔记等移动 App 操作,但它主要讨论上下文管理,不是访问控制或安全治理。生产测试里,长程 agent 不能随意发短信、下单、修改真实联系人或访问个人数据。APP 自动化测试需要沙箱账号、mock 支付、后端回滚、敏感动作审批、轨迹审计和数据脱敏。
对 APP 自动化测试 / 移动端 QA 的工程启发
MemGUI-Agent 对移动端 QA 的价值不在于“直接拿 MemGUI-8B-SFT 替换自动化脚本”。更现实的启发是,把长程测试执行从“线性脚本 + 日志”改成“状态治理 + 证据驱动”。
1. 测试执行状态应该显式建模
传统 E2E 脚本常常只有步骤序列。失败时,人再去读日志和截图。GUI agent 时代,执行器应当实时维护:
- 当前业务阶段;
- 已完成子目标;
- 持久业务变量;
- 最近 UI 变化;
- 可疑状态与恢复建议;
- 禁止动作与副作用边界。
这正是 ConAct 三类状态的工程版本。
2. 断言不应只放在最后
长程移动任务里,最后一屏可能看似正确,但中间已经走错路径;也可能最后一屏不稳定,但关键业务状态已正确写入。更稳的方式是 step-level checkpoints:每个阶段都保存关键 UI 事实和业务事实,必要时用后端状态、日志、网络 trace 或 mock 数据对账。
3. Flaky failure 是训练资产,不只是噪声
MemGUI-Agent 强调 history folding 和 memory actions,MobileForge 强调从失败轨迹里提取 hints。两者放在一起看,移动 QA 平台应该把 flaky 执行转成结构化资产:什么状态丢了,什么等待不足,哪个事实被污染,哪个弹窗改变了路径。这样才能让 agent 或脚本在下一轮变稳。
4. VLM 点屏要和结构化工具结合
MemGUI-Agent 是 screenshot-driven mobile GUI agent,但生产 QA 不应该只依赖截图。能用 accessibility tree、Appium selector、UIAutomator、XCUITest、deeplink、mock API、日志和后端查询的地方,都应该作为更稳定的 action / observation channel。VLM 更适合处理未知页面、视觉异常、自然语言判断和兜底恢复。
5. Memory writes 要可审计
如果 agent 把“价格 399”“联系人 138…”“订单号 X”写进状态,系统需要知道这个事实来自哪一帧截图、哪次 OCR、哪个接口、哪个日志片段。没有 provenance 的 memory,很容易把 hallucination 包装成可靠上下文。
可复现建议:先复现状态协议,再考虑训练模型
对多数团队来说,直接复现 MemGUI-3K 训练并不轻。更合理的路线是分层复现:
- 先复现 ConAct 状态结构:在现有 Appium/Maestro/VLM 执行器外层维护
H_t / M_t / L_t; - 再复现 memory action 日志:每步记录哪些事实被新增、更新、删除,保存截图证据;
- 然后做 offline evaluator:评估 memory write 是否正确、是否过期、是否被后续步骤使用;
- 最后再考虑 SFT / LoRA:用本地测试轨迹训练小模型或 reranker,让它学会更稳定地写状态和选择恢复策略。
这样做的好处是,即使不训练新模型,也能提升自动化系统的可观测性和失败诊断能力。训练只是后续放大器,不是第一步。
总结
MemGUI-Agent 把 mobile GUI agent 的一个关键问题讲清楚了:长程任务失败不只是“模型不够聪明”或“点得不够准”,而是上下文没有被治理。ReAct 式日志追加会让 prompt 变长、信息变稀、关键事实被截断;ConAct 则把历史折叠、UI 记忆和最近步骤变成显式状态,并让模型把上下文更新当作动作来学习。
它真正推进的地方有三点:
- 把 context management 纳入 mobile GUI agent 的端到端动作协议;
- 用 MemGUI-3K 提供带 ConAct annotations 的长程轨迹监督;
- 用 MemGUI-Bench / MobileWorld 证明上下文治理能改善长程任务,而不只是让 prompt 更整洁。
它也没有解决全部问题。真实商业 App 的 UI 漂移、异常恢复、安全副作用、memory hallucination、弱网、账号状态和测试 oracle 仍然需要工程系统补齐。对 APP 自动化测试而言,最值得带走的不是某个榜单数字,而是这条设计原则:长流程自动化必须把“中间事实”和“执行状态”当成一等对象管理,否则再强的 GUI agent 也会在跨页面、跨 App、跨时间的任务里逐步失忆。
参考链接
- 论文:https://arxiv.org/abs/2606.19926
- PDF:https://arxiv.org/pdf/2606.19926
- 项目页:https://memgui-agent.github.io/
- 代码:https://github.com/kwai/MemGUI-Agent
- 数据集:https://huggingface.co/datasets/lgy0404/MemGUI-3K
- 模型:https://huggingface.co/lgy0404/MemGUI-8B-SFT
- MemGUI-Bench:https://lgy0404.github.io/MemGUI-Bench