MobileForge:Mobile GUI Agent 从人工标注走向真实 App 自适应
从 GUIAgent 专家视角解析 MobileForge:用 MobileGym 与 HiFPO 把真实移动 App 探索、自动任务生成、层级反馈和 GRPO 训练连成 annotation-free adaptation 闭环,并讨论它对 APP 自动化测试与移动端 QA 的价值和风险。
论文:MobileForge: Annotation-Free Adaptation for Mobile GUI Agents with Hierarchical Feedback-Guided Policy Optimization
arXiv:2606.19930v1,2026-06
项目页:https://mobile-forge.github.io/
作者:Guangyi Liu, Pengxiang Zhao, Gao Wu, Yiwen Yin, Mading Li, Liang Liu, Congxiao Liu, Zhang Qi, Mengyan Wang, Liang Guo, Yong Liu
机构:Zhejiang University, Kuaishou Technology, Tsinghua University
一句话结论:MobileForge 真正推进的不是某个移动端榜单数字,而是把“真实 App 探索—任务挖掘—多次 rollout—过程反馈—策略优化”做成了无需人工任务、示范和 reward label 的自适应闭环;它把 mobile GUI agent 的核心矛盾从“能不能点准”推进到“能不能在持续变化的 App 中自动产生可训练经验”。
MobileForge 是 2026 年 6 月一篇很值得 GUIAgent 领域关注的新论文。它面对的不是静态 GUI grounding,也不是再构造一个固定 benchmark,而是一个更接近真实工程的问题:移动 App 数量巨大、版本更新频繁、业务流程随推荐流/地区/账号/弹窗变化而漂移,依赖人工写任务、录示范、标 reward 的适配方式很快失效。
论文提出的答案是 MobileForge:由 MobileGym 负责在真实目标 App 上探索、挖掘任务、执行 rollout 和生成层级反馈;由 HiFPO(Hierarchical Feedback-Guided Policy Optimization)把 trajectory outcome、step-level process feedback、corrective hints 转换成带 hint 上下文的 step-level GRPO 更新。结果上,MobileForge 用自动生成的 annotation-free adaptation data 将 Qwen3-VL-8B 在 AndroidWorld 上提升到 67.2% Pass@3,接近闭源数据训练的 GUI-Owl-1.5-8B base 的 69.0%;进一步得到的 ForgeOwl-8B 在 AndroidWorld 达到 77.6% Pass@3,在 MobileWorld GUI-only out-of-domain split 达到 41.0% success。
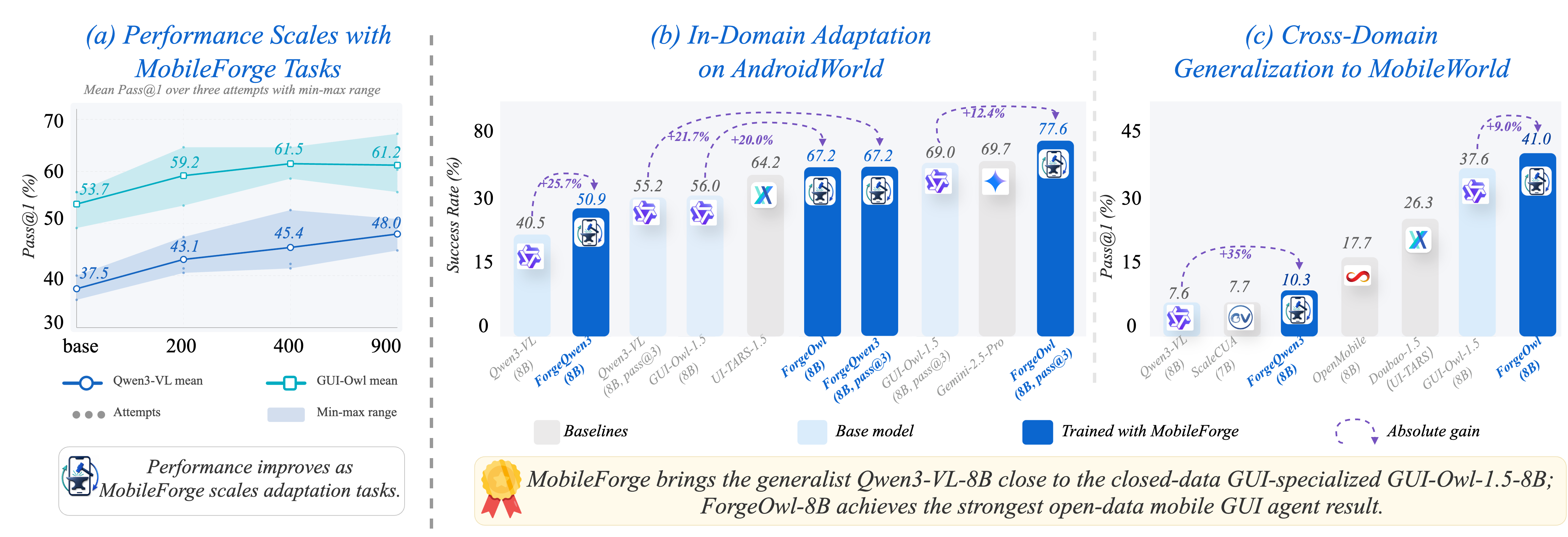
这张图重要,因为它把 MobileForge 的核心 claim 压缩成三件事:第一,自动生成任务数量增加时,AndroidWorld in-domain performance 呈现可扩展性;第二,Qwen3-VL-8B 这种通用 VLM 可以被推近 GUI-specialized base model;第三,AndroidWorld 侧生成的数据还能部分迁移到 MobileWorld GUI-only。对 APP 自动化测试来说,这意味着“从线上 App/灰度包自动采集探索轨迹,再转化成可训练、可回归的任务”可能比长期维护手写脚本更有战略价值。
为什么这篇论文值得 GUIAgent 领域关注
站在 GUIAgent / computer-use agent 专家视角,MobileForge 的位置可以这样判断:它不是一个单纯的 mobile agent framework,也不是一个新的 AndroidWorld prompt wrapper,而是把 annotation-free mobile adaptation 做成了较完整的训练范式。
放在近两年的 GUIAgent 谱系中:
- 相对 GUI grounding:ScreenSpot、GUI-Actor、UI-AGILE 等方向主要解决“目标元素在哪里、点击参数如何更准”。MobileForge 的重点不是单步定位,而是从多步尝试中抽取可复用经验,让 grounding 错误、路径绕行、任务中断都能变成训练信号。
- 相对 AndroidWorld / MobileWorld:AndroidWorld 与 MobileWorld 是评测锚点,MobileForge 则把 benchmark 环境反过来变成自适应数据生产器。它的贡献在 training/adaptation loop,而不只是 benchmark score。
- 相对 AndroidDaily / GRADE:AndroidDaily 强调闭源真实 App 的过程可验证评测;MobileForge 强调目标 App 内的自动任务生成和反馈驱动优化。前者更像 QA oracle,后者更像持续训练流水线。两者若结合,会更接近真实 APP 自动化闭环。
- 相对 SaaS-Bench / VisualWebArena / OSWorld:Web/桌面 benchmark 更容易拿到 DOM、文件或后端状态;mobile app 常常只有截图、动作和有限系统接口。MobileForge 的挑战在于把弱可观察的移动交互转为可优化信号。
- 相对 RL / 过程监督方向:论文的关键不在“用了 GRPO”这个标签,而在它没有直接拿粗粒度成功/失败做稀疏 RL,而是先经过 MobileGym-Critic、hint-guided multi-attempt、step filtering,再做 hint-contextualized step-level GRPO。
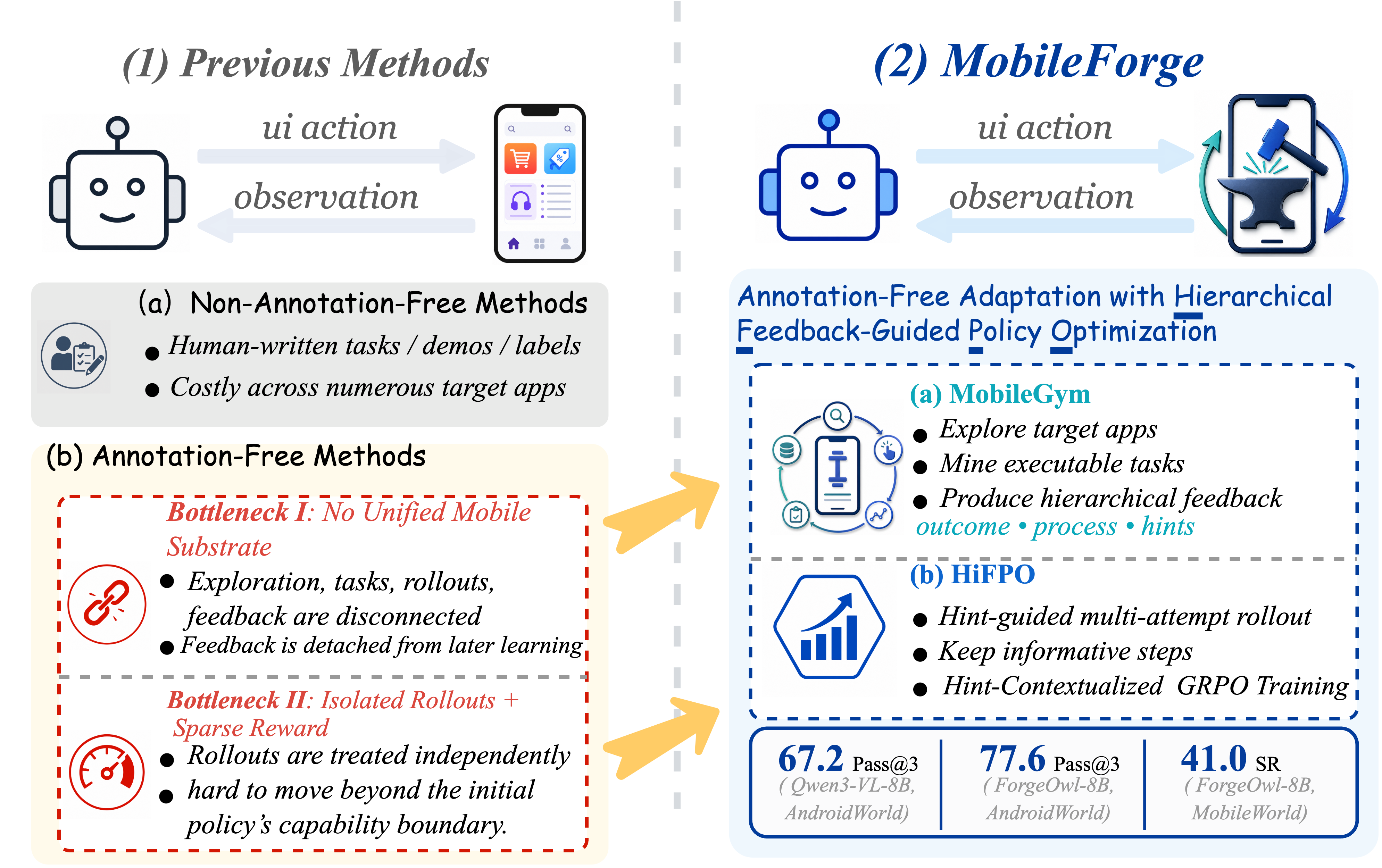
这张 overview 图是阅读论文的入口。它指出现有 annotation-free GUI learning 的两个断点:一是缺少统一的 target-app interaction/evaluation substrate,二是 rollout 经验往往孤立且只有粗 reward。MobileForge 的设计价值就在于把探索、curriculum mining、rollout、critic feedback 和 policy optimization 接成一个闭环。对移动端 QA 平台而言,这相当于把“探索测试 + 用例生成 + 执行记录 + 失败归因 + 用例演化”串成一条流水线。
背景与问题定义:移动端自适应为什么比固定榜单更难
移动端 GUI Agent 已经有相当多的基础能力研究:
- 屏幕理解与 GUI grounding:模型要理解截图、OCR、图标、布局,并输出 tap、swipe、type、wait、terminate 等动作。
- 在线执行 benchmark:AndroidWorld、MobileWorld、MobileAgentBench 等评估 agent 在真实/模拟手机环境中的多步任务成功率。
- 数据生成与训练:从人工示范、Web tutorial、合成任务、用户轨迹、在线探索中获取训练数据。
- 过程监督与 RL:用 reward model、verifier、critic 或 execution feedback 把失败轨迹转化为改进信号。
MobileForge 抓住的痛点是:固定 benchmark 只能告诉我们某一批任务上的能力,不能解决一个新 App、一个新版本、一个新业务流程如何快速适配。 在 APP 自动化测试里,这一点更明显。测试团队每天面对的是新页面、新弹窗、新实验、新接口、新登录态和新机型组合。靠人工维护 Appium/Maestro 脚本,维护成本常常超过初始编写成本;靠通用大模型直接点屏,又很难保证稳定性、可解释性和安全边界。
论文因此把任务定义为 annotation-free adaptation:给定目标 mobile app environment 和初始 GUI policy,不使用人工任务、专家示范或 reward label,让系统自己探索 App、生成可执行任务、多次尝试、评估轨迹,并更新策略。
这张图重要,因为它比 teaser 更具体地展示了 MobileForge 的闭环:Explore(E) -> Curriculum(Z) -> Rollout(policy, task, hint) -> Critic -> HiFPO -> GRPO。注意这里的关键变量不是最终成功率,而是 exploration evidence、generated curriculum、multi-attempt trajectories、hierarchical feedback 和 hint context。对测试平台来说,这对应的工程对象分别是探索轨迹库、自动生成用例库、执行日志、过程诊断和失败修复建议。
MobileGym:annotation-free adaptation 的底座
MobileGym 承担了 MobileForge 中最工程化的一层:它让 agent 与目标移动 App 真实交互,收集可达 GUI 状态和转移,基于探索轨迹挖掘任务,再对完成尝试进行层级评估。
论文强调 MobileGym 不是简单的“跑一批随机点击”。它需要完成三类工作:
- Target-app exploration:在目标 App 中探索可达状态、记录 GUI transitions 和关键操作路径。
- MobileGym-Curriculum:从探索证据中生成 trajectory-grounded tasks,而不是只从 landing screen 或页面文本凭空生成任务。
- MobileGym-Critic:对 agent 的完整尝试输出 trajectory-level outcome、step-level process feedback 和 corrective hints。
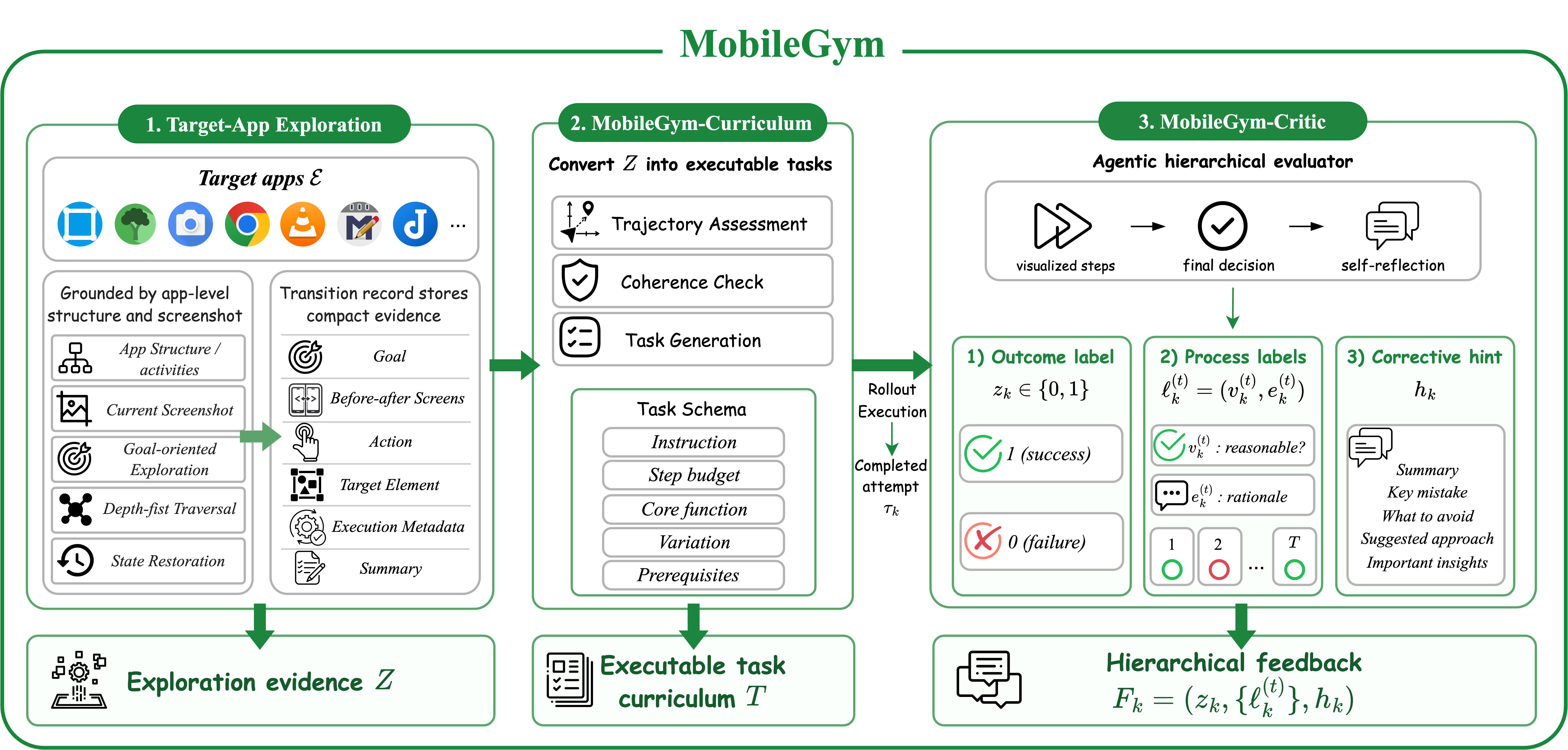
这张图对 APP 自动化测试尤其有启发。很多自动化体系把“探索测试”“脚本生成”“执行评估”“失败归因”拆成孤立模块,导致探索轨迹很难变成回归用例,失败日志很难变成下一轮修复策略。MobileGym 的价值在于把它们统一到一个 substrate:探索到的可达路径用于生成任务,任务执行产生的失败又被 critic 压缩成 hints,hints 进入下一轮 rollout 和训练。
从工程角度看,MobileGym-Critic 的质量决定了整个系统上限。如果 critic 只能看最终截图,它会把许多“看起来完成”的轨迹误判为成功;如果 critic 能结合截图序列、动作历史、任务约束、页面状态和可恢复错误,它就更接近 QA 中的过程 oracle。
HiFPO:把失败轨迹变成可训练信号
MobileForge 的训练核心是 HiFPO。它处理的是 GUI agent RL 中最典型的问题:移动任务 reward 稀疏、失败路径多、每次 rollout 成本高,而且失败轨迹并不全是垃圾。一个失败尝试可能前 10 步都正确,只是在最后一个权限弹窗、搜索结果选择或返回路径上出错。
HiFPO 的关键设计包括:
- Hint-guided multi-attempt rollout:同一任务多次尝试,后续尝试带入之前 critic 总结的 corrective hints。
- 任务过滤:去掉已经全成功的 mastered tasks,保留 all-fail 与 mixed tasks,因为失败任务中仍可能包含有价值局部步骤。
- Step-level extraction:从层级反馈中抽取局部合理步骤,避免把整条失败轨迹直接 SFT。
- Hint-contextualized GRPO:把 hint context 放进策略输入,用 step-level reward 做 group-relative optimization。
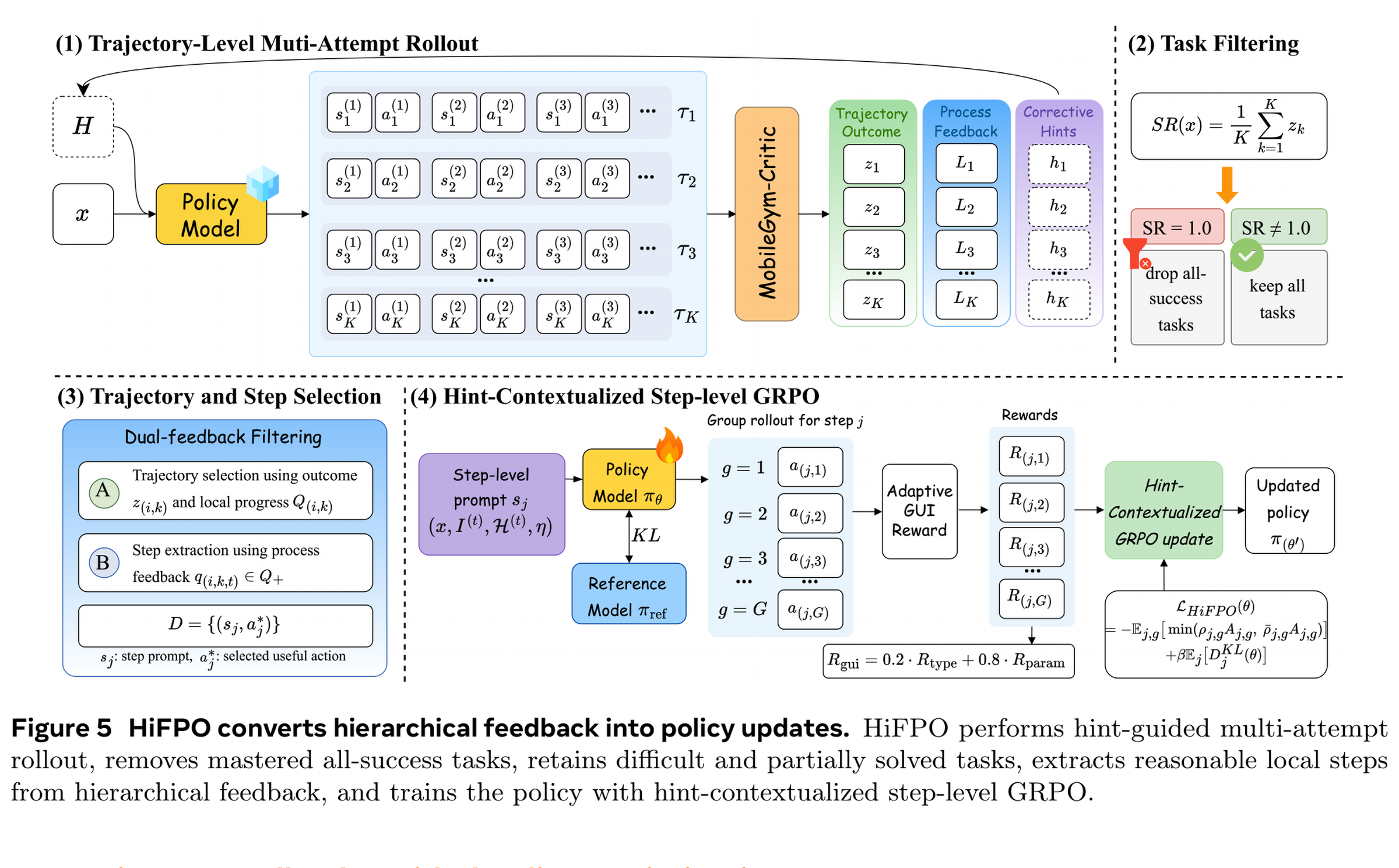
这张图重要,因为它解释了 MobileForge 为什么不等同于“多跑几次 + 成功轨迹 SFT”。它真正复用的是失败中的局部正确动作和 critic 生成的纠错 hint。对于 APP 自动化测试,这一点可以直接迁移:不要只把 pass 的脚本沉淀为资产,也要把 flaky、半成功、被弹窗打断、被网络延迟影响的执行轨迹转成“等待策略、恢复路径、断言补充、选择器修正”的训练材料。
论文的 corrective hint 消融很强:在 200 个生成任务上,加入 hints 后整体 rollout success 从 52.0% 提升到 77.0%,Pass@3 从 49.0% 提升到 72.5%,平均每次尝试步数从 18.4 降到 17.2。
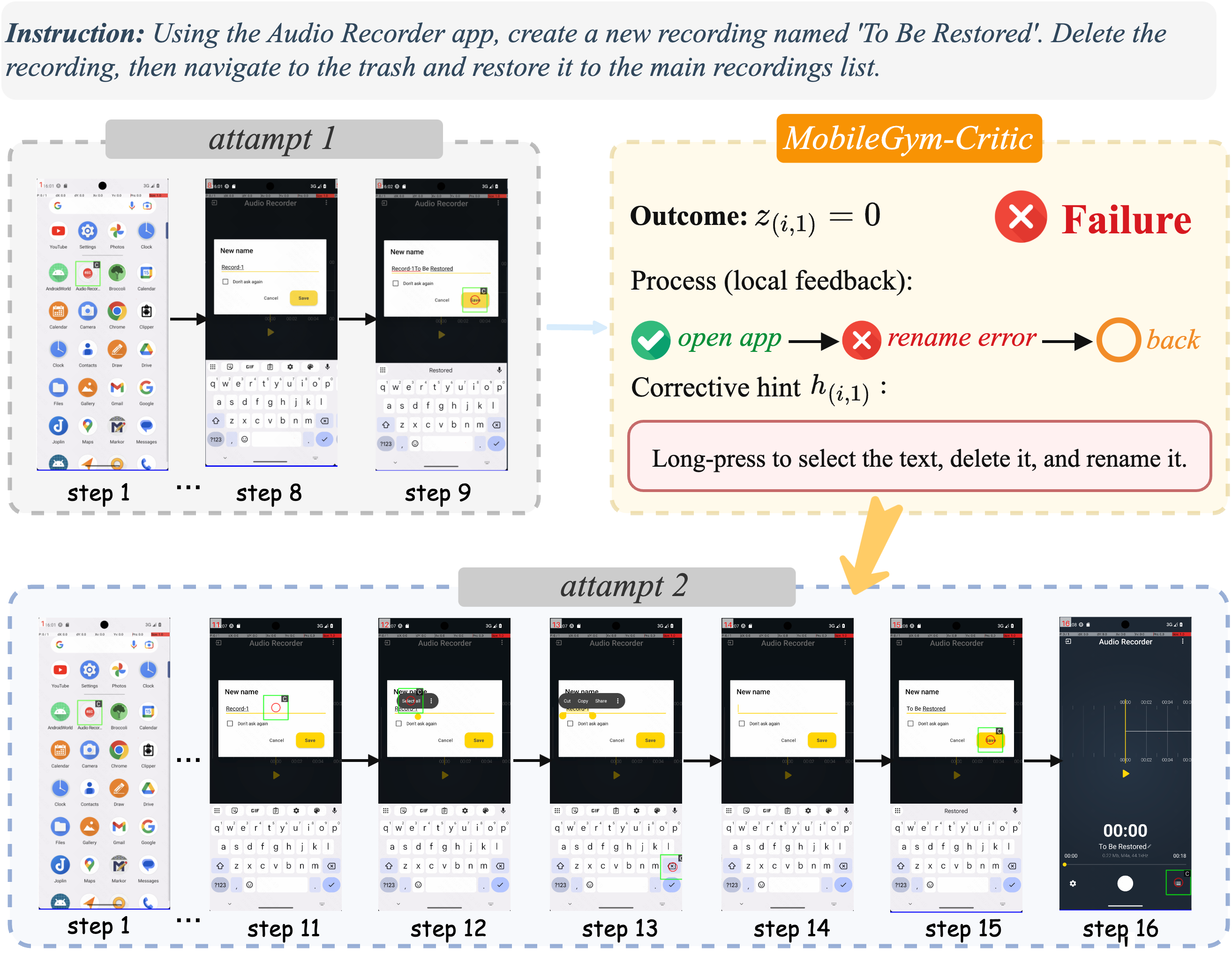
这张图把 hint 的作用讲得很直观:失败并不只是负样本,它也能暴露 App 操作知识。MobileGym-Critic 将失败原因压缩为提示,后续尝试可以避开重复错误。移动 QA 中的类比是:一次失败执行如果能产出“弹窗需要先关闭”“搜索结果要按日期过滤”“WebView 加载后需等待特定文本”“返回会丢失表单状态”等结构化修复建议,就能显著提升自动化稳定性。
实验结果:强点在自适应闭环,弱点在评测边界
论文主实验围绕 AndroidWorld in-domain adaptation 和 MobileWorld GUI-only out-of-domain transfer 展开。
AndroidWorld 上,Qwen3-VL-8B base 的 Pass@1/2/3 分别为 40.5% / 49.1% / 55.2%;用 900 个自动生成任务适配后,ForgeQwen3-8B 达到 50.9% / 60.3% / 67.2%。GUI-Owl-1.5-8B base 的 Pass@1/2/3 为 56.0% / 68.1% / 69.0%;ForgeOwl-8B 达到 67.2% / 75.0% / 77.6%。值得注意的是,Qwen3-VL-8B 在 Hard difficulty 上从 19.3% 降到 17.5%,而 GUI-Owl-1.5-8B 在 Hard 上从 19.3% 升到 29.8%。这说明 MobileForge 对不同 base agent 的收益并不均匀,generalist VLM 的困难任务泛化仍然脆弱。
MobileWorld GUI-only 上,ForgeOwl-8B 达到 41.0%,高于 GUI-Owl-1.5-8B 的 37.6%,也高于 OpenMobile-8B 的 17.7%、ClawGUI-2B 的 17.1%。但 ForgeQwen3-8B 只有 10.3%,相比 Qwen3-VL-8B 的 7.6% 是提升,却仍远低于 GUI-specialized agents。这一点很关键:annotation-free adaptation 能放大 base agent 的移动端能力,但不能凭空补齐 mobile GUI prior。
论文的核心表格可以重建为下面两张。
| Base Agent | Tasks | Pass@1 | Pass@2 | Pass@3 | Easy | Medium | Hard | Overall Avg. |
|---|---|---|---|---|---|---|---|---|
| Qwen3-VL-8B | 0 | 40.5% | 49.1% | 55.2% | 44.8% | 35.2% | 19.3% | 40.7% |
| Qwen3-VL-8B | 900 | 50.9% | 60.3% | 67.2% | 61.2% | 41.7% | 17.5% | 49.8% |
| GUI-Owl-1.5-8B | 0 | 56.0% | 68.1% | 69.0% | 66.7% | 50.0% | 19.3% | 54.9% |
| GUI-Owl-1.5-8B | 900 | 67.2% | 75.0% | 77.6% | 73.2% | 57.4% | 29.8% | 63.4% |
这张表来自论文 Table 1。它最值得关注的不是绝对成功率,而是两种 base agent 的提升结构不同:Qwen3-VL-8B 在 Easy/Medium 上收益明显,但 Hard 任务下降;GUI-Owl-1.5-8B 的 Hard 任务收益更明显。对工程落地来说,这提示移动端 agent 的自适应不是“数据越多越万灵”,还要看 base model 是否已有足够的 UI action prior、长程状态保持能力和动作参数稳定性。
| Agent | MobileWorld GUI-only SR |
|---|---|
| GUI-Owl-1.5-32B | 43.9% |
| MAI-UI-235B-A22B | 39.7% |
| GUI-Owl-1.5-8B | 37.6% |
| Qwen3-VL-8B | 7.6% |
| OpenMobile-8B | 17.7% |
| ClawGUI-2B | 17.1% |
| ForgeQwen3-8B | 10.3% |
| ForgeOwl-8B | 41.0% |
这张表来自论文 Table 2。它支持“AndroidWorld-side annotation-free adaptation 能迁移到 MobileWorld”的 claim,但也暴露出 MobileWorld 仍然是强 mobile GUI base model 的战场。ForgeQwen3-8B 的 out-of-domain 结果提醒我们,若把 MobileForge 用到企业 App 或复杂 Hybrid App,不能只看 in-domain AndroidWorld 增益,还要单独测跨 App、跨版本、跨设备、跨语言的泛化。
Ablation:哪些结论可信,哪些可能被高估
MobileForge 的 ablation 比较完整,尤其是 hints、training objective、task filtering 和 evaluator model。
| Setting | Key result |
|---|---|
| No Hint Context → With Corrective Hints | Overall success 52.0% → 77.0%;Pass@3 49.0% → 72.5% |
| No-hint SFT 900 tasks | AndroidWorld Pass@1 44.0% |
| Hint SFT 900 tasks | AndroidWorld Pass@1 47.4% |
| Hint-contextualized GRPO 900 tasks | AndroidWorld Pass@1 50.9% |
| Keep all-fail + mixed tasks | AndroidWorld 48.3%,MobileWorld 15/117,在过滤策略中综合最好 |
| Replace evaluator with Qwen3-VL-8B | 仍可从 40.5% Pass@1 提升到 44.8%,说明不完全依赖单一 proprietary evaluator |
这些结果让论文的核心机制更可信:提升不只是来自更多 rollout,也不只是来自 SFT;corrective hints 与 step-level GRPO 确实是关键因素。
但站在 GUIAgent 领域专家视角,也要警惕几个可能被高估的部分。
1. AndroidWorld 既是生成侧环境又是评测锚点,存在 benchmark overfitting 风险
论文强调 MobileWorld 不使用任何适配数据,这是重要控制。但 AndroidWorld in-domain 的大幅提升,本质上仍然来自 AndroidWorld-side generated tasks。即便测试任务不同,App、动作空间、任务风格、verifier 语义和环境约束都可能共享。对领域判断来说,AndroidWorld 提升应解读为“能适配同一环境族”,而不是“普遍移动端能力同等提升”。
2. Critic feedback 可能形成隐藏 oracle
MobileGym-Critic 负责生成 outcome、step labels 和 hints。如果 critic 能访问比真实部署更多的状态、任务结构或 evaluator prompt 先验,它就可能成为隐藏 oracle。论文通过 evaluator model ablation 缓解了“只靠强 proprietary judge”的担忧,但仍需要进一步公开 critic prompt、反馈样例、误判率和人工一致性。
3. 任务生成质量决定上限,自动 curriculum 可能偏向可探索路径
MobileGym-Curriculum 基于探索轨迹生成任务,这比 landing-screen baseline 更好。但它天然偏向 agent 已经能探索到的功能。真正困难的业务路径,例如登录态切换、权限恢复、支付前置条件、深层设置、跨 App 分享、WebView 内嵌流程,可能因为探索不足而缺席。对 QA 来说,这类似“探索测试覆盖了容易到达的路径,却漏掉高风险深层业务流”。
4. Pass@k 需要结合执行成本与安全边界看
Pass@3 / Pass@4 能体现多次尝试能力,但真实 App 自动化不能无限重试。一次误点删除、误发消息、误下单就可能造成副作用。MobileForge 的 negative constraints 和安全机制不是论文主线,因此把它用于生产 App 测试时,必须加上权限隔离、mock 数据、灰度账号、后端回滚和危险动作审批。
5. 复现成本不低
论文附录给出 900-task 8B runs 使用 8 x 80GB GPUs、约 80 小时。这对研究机构可接受,对多数移动测试团队则偏重。工程落地更现实的路线可能是先复现 MobileGym-Curriculum 与 Critic,把输出用于测试用例生成和失败归因;训练环节可以从小规模 LoRA、策略 reranker 或 prompt/hint memory 开始。
案例分析:长程任务中的“流程保持”才是 mobile agent 难点
论文给了多个 case study,最有价值的是 base model 与 adapted model 在同一任务上的轨迹对比。它们显示 MobileForge 不只是提高点击准确率,而是在任务流程保持、失败恢复和搜索策略切换上带来改善。
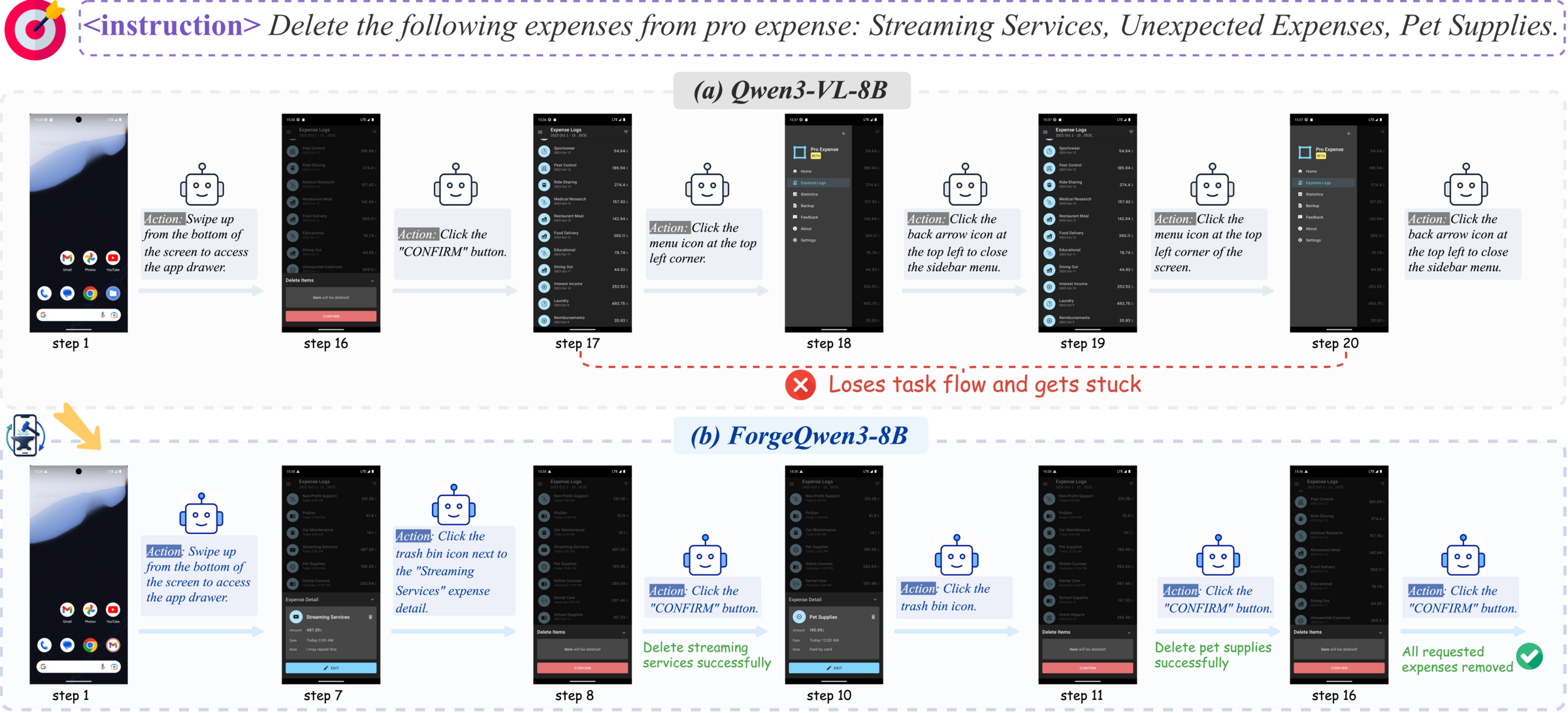
这张图说明的是长程任务中的 state tracking 问题。删除多个 expense 并不是视觉上很难的任务,难点在于删除一个项目后列表状态变化、菜单/侧边栏切换、剩余目标记忆和终止条件判断。对 APP 自动化测试来说,这类问题非常常见:批量编辑、购物车、多账号设置、消息列表清理、文件管理等流程都需要 agent 记住“哪些目标已处理、哪些仍需处理”。
这张训练曲线的意义在于提醒我们,GUI agent 的动作质量至少有两个层面:动作类型是否正确,以及动作参数是否正确。APP 自动化测试中也是如此:选择 Appium 的 click/type/swipe/wait 是动作类型问题,选择具体元素、输入文本、等待条件是参数问题。只优化最终 pass/fail,往往看不出 agent 是“知道该做什么但点错了”,还是“根本规划错了”。
这组图展示了一个很典型的 GUI 自动化失败模式:base model 在部分进展后陷入重复滚动,无法从“继续滚动”切换到“用搜索定位剩余目标”。ForgeQwen3-8B 的改善说明 MobileForge 学到的可能不是单一 App 的按钮位置,而是某些更通用的恢复策略:当列表查找低效时,切换搜索;当任务剩余目标明确时,避免无目的探索。
这组 MobileWorld 图更接近真实移动 QA 的跨 App 流程:查询信息、验证条件、创建日历事件、继续邮件工作流。这里真正的挑战不是单个点击,而是跨 App 状态、业务条件和中间产物的一致性。对 H5/Hybrid App、Push 唤起、外部支付、地图导航、系统分享面板等测试场景,类似的流程保持能力比单点 grounding 更关键。
专家点评:真正贡献、被高估部分、工程落地建议
真正贡献
MobileForge 的真正贡献有三点。
第一,它把 mobile GUI agent 的适配问题从“人工写任务/录示范”推进到“目标 App 内自动探索与自适应”。这对快速变化的移动生态非常关键。
第二,它把失败轨迹中的局部正确步骤、过程反馈和 corrective hints 转成可训练信号,避免了“只学成功轨迹”或“用整条失败轨迹做负样本”的粗糙处理。
第三,它证明了 annotation-free adaptation 对 GUI-specialized base agent 有明显增益,并且存在一定 out-of-domain transfer。这为未来 App 级持续学习、企业私有 App 适配、移动自动化回归提供了可参考路线。
可能被高估的部分
MobileForge 的结果不应被解读为“移动端 GUI Agent 已经可以自动适配任意 App”。论文仍然主要在 AndroidWorld / MobileWorld 这类研究环境中验证,真实商业 App 的登录、账号、地区、推荐流、隐私权限、支付和不可逆操作更复杂。critic 质量、任务覆盖、隐藏 oracle、UI 漂移和安全边界都会显著影响实际效果。
另外,ForgeQwen3-8B 在 MobileWorld 只有 10.3%,说明通用 VLM 通过 annotation-free adaptation 获得的迁移有限。MobileForge 更像是强 base model 的加速器,而不是弱 base model 的万能补丁。
工程落地建议
对 APP 自动化测试 / 移动端 QA,最值得采用的不是直接复现 8x80GB 的训练,而是复用 MobileForge 的四个工程模式:
- 探索轨迹资产化:让 agent 在测试包、灰度包、mock 环境中探索 App,把可达页面、操作路径、弹窗、错误状态沉淀为轨迹库。
- 轨迹驱动用例生成:不要只从 PRD 或页面文本生成测试用例,应结合真实探索路径生成可执行任务。
- 过程级 critic:把截图、动作、OCR、accessibility tree、日志、网络、崩溃、后端状态组合成 step-level feedback,而不是只看最终截图。
- 失败到修复 hint:每次失败执行都产出结构化 hint,例如等待条件、权限处理、选择器修正、fallback deeplink、数据准备和危险动作边界。
需要警惕的是:生产测试环境必须先解决权限和副作用。任何自动探索都应运行在测试账号、mock 支付、可回滚后端、沙箱设备和敏感动作拦截之下。
对 APP 自动化测试 / 移动端 QA 的启发
MobileForge 对移动 QA 的启发可以落到一个闭环:探索—生成—执行—诊断—优化—回归。
- 测试生成:从真实 App exploration evidence 生成任务,能覆盖人工脚本容易遗漏的页面状态和功能组合。
- 执行稳定性:corrective hints 可以被转化为等待策略、重试策略、弹窗处理策略和替代路径。
- Oracle 设计:MobileGym-Critic 的层级反馈可以扩展为 QA oracle:UI 状态 + 业务状态 + 网络/日志 + 崩溃/ANR + 后端校验。
- Hybrid App 流程:对 WebView、系统分享、Push、支付 SDK、地图/相册/权限页等跨上下文流程,MobileForge 式 multi-attempt feedback 比单脚本维护更适合处理 UI 漂移。
- 工具关系:Appium、UIAutomator、XCUITest、Maestro 仍然适合确定性执行;GUI Agent 更适合探索、用例生成、失败修复建议和非稳定 UI 的 fallback。最佳架构不是替代传统自动化,而是让 agent 生成/维护脚本,并由传统工具执行和验证。
- 轨迹评估:不要只统计 final success rate,应记录 step-level error taxonomy:grounding 错误、等待不足、页面理解错误、业务条件漏检、重复动作、危险动作、oracle mismatch。
在企业实践中,一个可落地的最小版本是:先不训练模型,只做 MobileGym-like 探索与 critic,把自动生成任务和失败 hints 接入现有 Appium/Maestro 回归;当轨迹库和 oracle 稳定后,再考虑用 LoRA/GRPO 做 agent 策略微调。
局限性与未来方向
MobileForge 指向了 mobile GUI agent 的重要方向,但后续还需要补齐几个问题:
- 更真实的闭源 App 验证:需要在 AndroidDaily 这类闭源真实 App benchmark 上验证 adaptation 是否仍然有效。
- critic 可审计性:公开更多 critic prompt、误判案例、人工一致性和不同 evaluator 的 bias 分析。
- 安全约束内生化:把 negative constraints、危险动作审批、隐私保护和账号隔离纳入 training/evaluation loop。
- 跨版本 UI 漂移:验证同一 App 新旧版本、不同机型、不同语言和不同地区下的适配稳定性。
- 低成本训练路线:探索不依赖 8x80GB 的轻量适配,例如 small policy reranker、action verifier、hint memory、LoRA 或 test-time adaptation。
- 与传统自动化工具融合:让 MobileForge 生成的任务、hints 和 step labels 能输出为 Appium/Maestro/UIAutomator/XCUITest 可执行资产。
总结
MobileForge 值得关注,因为它把 mobile GUI agent 的研究重心从“固定任务上跑得更高”推进到“面对目标 App 自动产生适配经验”。这正是 APP 自动化测试长期缺失的一环:真实 App 会变化,人工脚本会腐化,单次成功轨迹不够,失败执行也应该产生价值。
它的最大贡献是闭环范式:MobileGym 负责把真实移动交互变成任务与反馈,HiFPO 负责把层级反馈变成策略更新。它的主要风险也很清楚:critic 是否可靠、任务生成是否覆盖关键业务流、benchmark 是否过拟合、真实 App 副作用是否可控。
对移动 QA 团队而言,MobileForge 最值得复现的不是榜单分数,而是三类基础设施:真实探索轨迹库、过程级评估器、失败到修复 hint 的沉淀机制。当这些基础设施成熟后,GUI Agent 才可能从“能演示用手机”走向“能持续维护移动端自动化闭环”。
参考链接
- 论文 abs:https://arxiv.org/abs/2606.19930
- 论文 HTML:https://arxiv.org/html/2606.19930
- 项目页:https://mobile-forge.github.io/
- AndroidWorld:https://github.com/google-research/android_world
- MobileWorld / GUI-Owl 相关工作:https://arxiv.org/abs/2602.16855
- AndroidDaily 论文:https://arxiv.org/abs/2605.27761