Headroom:把 AI Agent 的上下文压缩做成本地代理层
拆解 chopratejas/headroom:它不是单个压缩算法,而是用 wrap、透明代理、provider-specific live zone、块级压缩器和 CCR,把工具输出压缩变成对 Agent 透明的一层本地基础设施。
项目:chopratejas/headroom
分析版本:main 分支bc12ace
一句话结论:Headroom 的核心不是“压缩文本”,而是把 Agent 发给模型前的上下文变成一条可拦截、可判定、可局部改写、可追回原文的本地代理链路。
先说它在解决什么
AI Agent 的上下文浪费,通常不是来自用户手写的几句话,而是来自 Agent 自己读到的东西:工具输出、日志、搜索结果、RAG chunk、文件内容、git diff、历史消息。它们往往有三个特点:
- 长,几千到几十万 token 很常见。
- 结构化程度高,比如 JSON 数组、编译日志、grep 结果、统一 diff。
- 真正有价值的信息密度低,模型不需要逐字看到全部原文。
普通的“压缩库”只能解决一小段文本怎么变短的问题。Headroom 试图解决的是另一个层级的问题:不改 Agent 主体逻辑,也尽量不改模型调用代码,在请求进入 LLM provider 之前,把上下文中适合压缩的部分改写掉。
README 里把它称为 Context Optimization Layer。源码拆开看,这个说法是准确的:Headroom 不是一个单点算法,而是 Python CLI、Rust proxy、provider-specific JSON walker、内容检测器、压缩器、CCR 存储和 MCP retrieve tool 组成的一层本地基础设施。
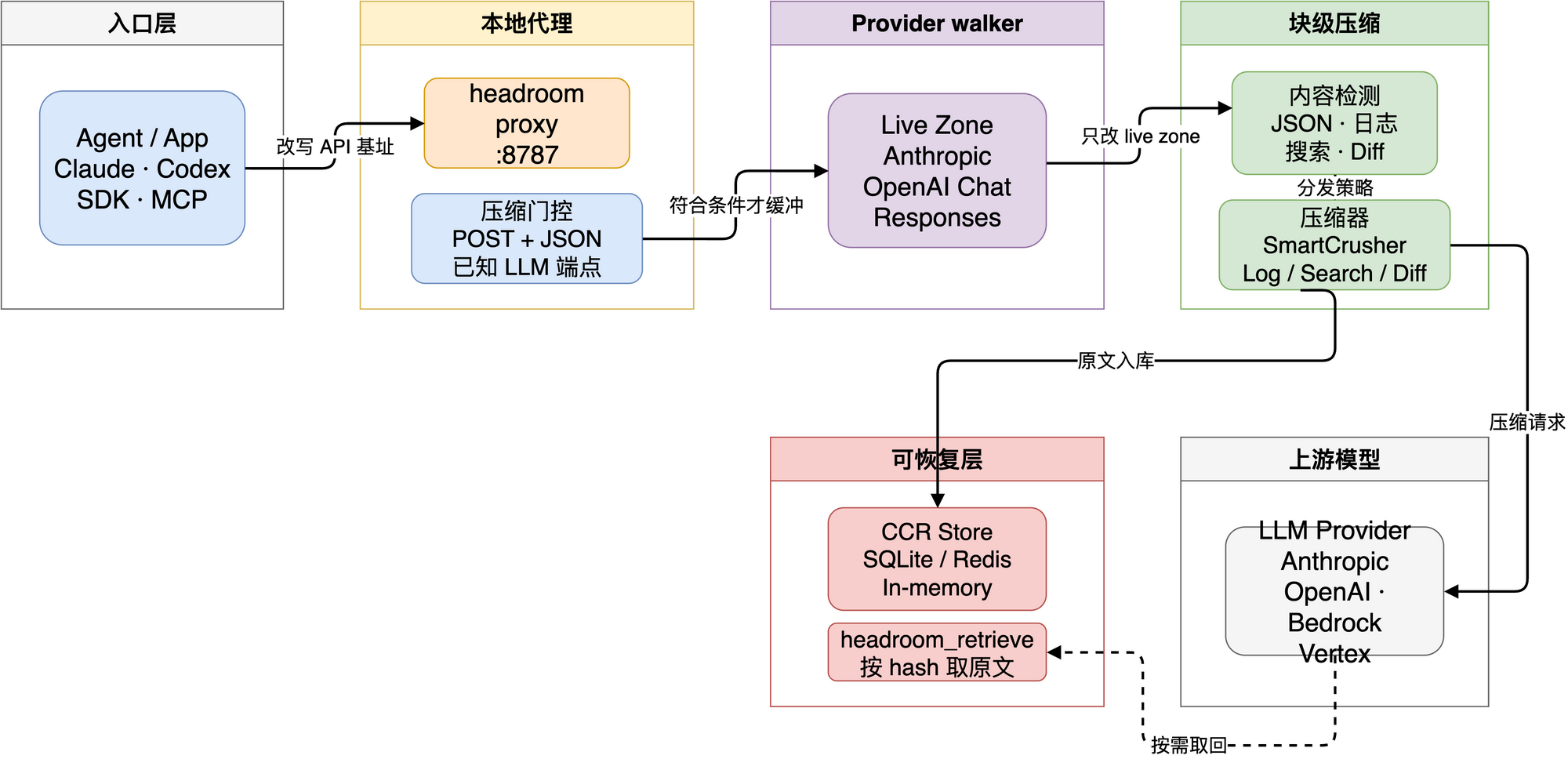
图 1:Headroom 的主路径是“Agent/App -> 本地代理 -> live zone 定位 -> 内容检测 -> 压缩器 -> CCR -> LLM provider”。
仓库结构:Python 做入口,Rust 做热路径
这个仓库有两个明显的语言边界。
Python 侧主要在 headroom/:
headroom/cli/:命令行入口,包含proxy、wrap、mcp、memory、learn等命令。headroom/providers/:不同 Agent/provider 的启动环境适配,比如 Claude、Codex。headroom/api/、headroom/core/:给 Python 用户直接调用的库接口和兼容层。
Rust 侧在 workspace 里:
crates/headroom-core:核心压缩、live zone、CCR、内容检测。crates/headroom-proxy:HTTP 透明代理,负责拦截、分类、压缩、转发。crates/headroom-py:通过 maturin 暴露给 Python 的扩展模块。crates/headroom-parity:用于锁定 Python/Rust 行为一致性的校验。
pyproject.toml 里包名是 headroom-ai,核心依赖包括 tiktoken、litellm、click、rich。proxy extra 里则有 fastapi、uvicorn、mcp、zstandard、onnxruntime、sqlite-vec 等依赖。这个组合说明它不是只想做一个纯算法包,而是要承担运行时代理、CLI、MCP 和本地存储。
Rust workspace 的 serde_json 打开了 preserve_order、arbitrary_precision、raw_value。这点很关键:Headroom 不是把 JSON 读出来再随便序列化回去,它需要尽可能保持请求字节稳定,尤其是 prompt cache 相关区域。
接入方式:library、proxy、wrap 和 MCP
Headroom 给了几种层级不同的接入方式。
最直接的是 library:你把一段内容交给 Headroom,它返回压缩后的内容。这个适合自己控制调用链的应用。
更有意思的是 proxy:Agent 仍然调用 OpenAI、Anthropic 这类 provider 兼容接口,但 base URL 指向本地 Headroom 代理。代理收到请求后,判断是否可压缩,局部改写请求体,再转发给真实 provider。
headroom wrap 则把这件事再往前包了一层。比如启动 Claude 或 Codex 时,它会先拉起本地 proxy,再把对应的环境变量指向 proxy:
cmd = [sys.executable, "-m", "headroom.cli", "proxy", "--port", str(port)]Codex 适配里会把 OpenAI base URL 指向本地代理:
def proxy_base_url(port: int) -> str:
return f"http://127.0.0.1:{port}/v1"Claude 适配则走 Anthropic 风格的 base URL,并且会处理 MCP 配置。这里的关键不是“自动启动一个服务”这么简单,而是把不同 Agent 的 provider 配置差异收口在 wrap 层:用户继续启动原来的 Agent,Headroom 插进网络路径。
MCP 的角色也很重要。压缩后如果上下文里只留下一个 CCR marker,模型需要在确实需要原文时调用 headroom_retrieve 取回原始 payload。也就是说,Headroom 不是单纯丢掉信息,而是把“全量塞进 prompt”变成“必要时按 key 取回”。
代理门控:不是所有请求都压缩
透明代理最怕过度聪明。Headroom 的 proxy 入口在 crates/headroom-proxy/src/proxy.rs,实际拦截前有很明确的门控条件:
let should_intercept = state.config.compression
&& method == Method::POST
&& compression::is_compressible_path(uri.path())
&& is_application_json(req.headers());这四个条件把范围压得很窄:
- 开启压缩配置。
- 只处理 POST。
- 只处理已知可压缩 provider endpoint。
- 只处理 JSON 请求体。
endpoint 分类在 crates/headroom-proxy/src/compression/mod.rs:
pub enum CompressibleEndpoint {
AnthropicMessages,
OpenAiChatCompletions,
OpenAiResponses,
}对应路径主要是 /v1/messages、/v1/chat/completions、/v1/responses。不在这个列表里的请求,代理会按原始请求转发。这个设计牺牲了一些覆盖面,但换来了更清晰的安全边界:只有理解 shape 的请求才进入压缩路径。
代理还会根据认证模式构造 CompressionPolicy。源码里能看到对 auth mode、PAYG fallback、volatile detector、cache drift detector 的处理。这里隐含的工程判断是:压缩上下文不是纯文本变换,它会碰到计费模式、provider 语义、缓存稳定性和请求兼容性。
live zone:只改可以改的那一段
Headroom 最值得拆的是 live zone 这个概念。它不是简单遍历整个 JSON,把所有长字符串都压缩掉。crates/headroom-core/src/transforms/live_zone.rs 里明确把压缩限制在 message 内部,并且要找出一段可以变化而不破坏 prompt cache 的区域。
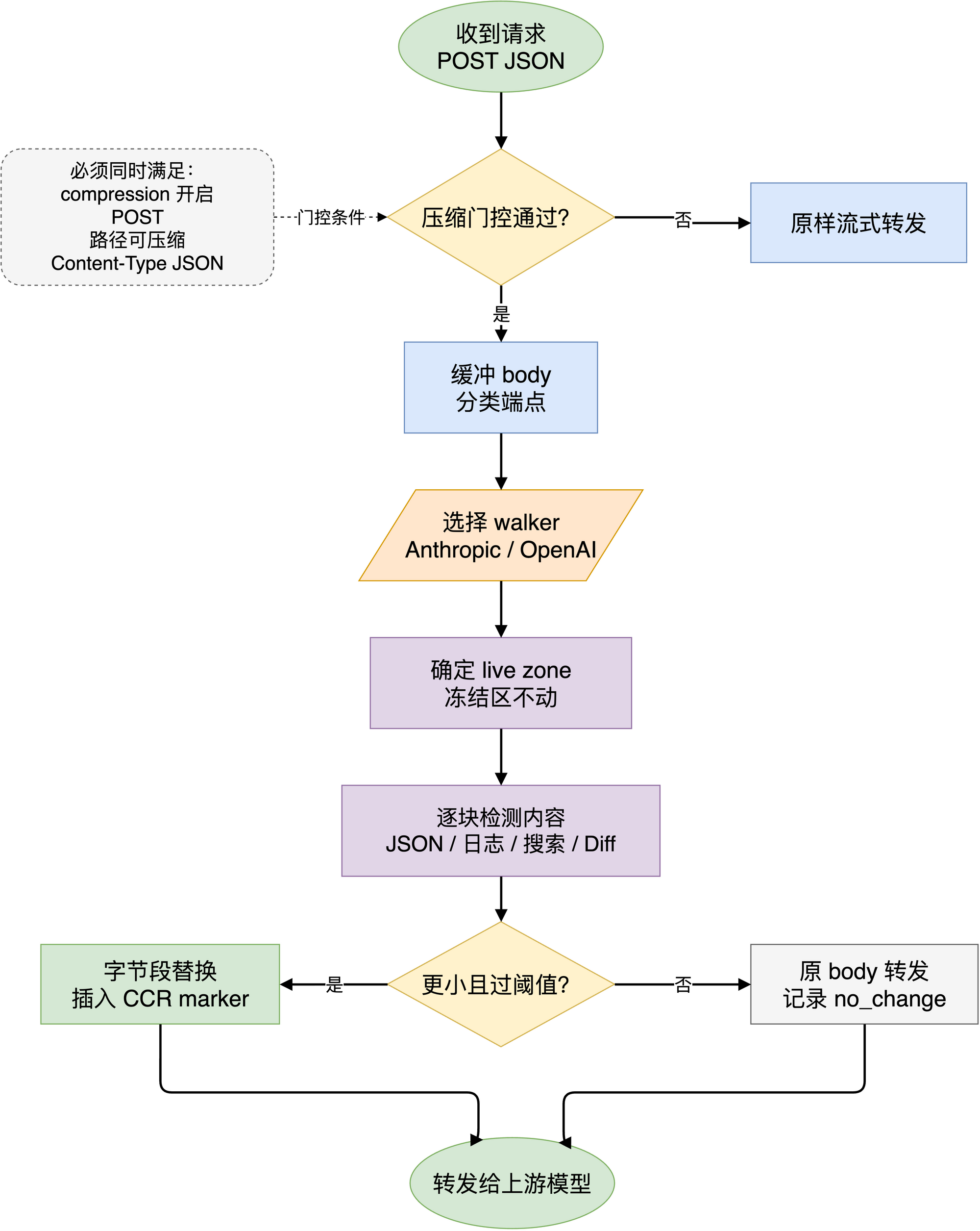
图 2:Headroom 先判断请求是否可压缩,再按 provider shape 找 live zone,最后只对 live zone 内的块做内容检测和压缩。
为什么需要 live zone?因为很多 Agent 请求会依赖 provider 的 prompt cache。前缀一旦变化,缓存就会失效。Headroom 的策略是:
- frozen prefix 尽量不碰。
- 最新一轮用户消息、工具结果、日志输出等更可能是可变区域。
tool_use、thinking、redacted_thinking、compaction等块会形成热区边界。- 只对边界内的候选块做压缩。
这个设计把“节省 token”和“保住缓存命中”放在同一个问题里处理。很多压缩方案只关注压缩率,但 Agent 真实成本里还有缓存命中率、延迟和 provider 的请求格式兼容性。
更关键的是,Headroom 不是重建整个 JSON。live zone 模块强调 byte-range surgery:定位要改的字节范围,只替换那段内容,外部字节保持不变。测试里也专门检查压缩块前后的 prefix/suffix 字节哈希保持一致。
Provider-specific walker:不要假装所有聊天协议长一样
Headroom 没有写一个“通用 JSON 递归遍历器”去猜哪里能压。它为不同 provider 做了不同 walker。
Anthropic messages 的结构是 messages[].content[] block。live_zone_anthropic.rs 会解析 messages,计算 frozen count,再交给 core 的 compress_anthropic_live_zone。它关心最新 user message、tool_result、text block,以及 Anthropic 自己的 thinking/tool_use 等块。
OpenAI Chat Completions 的 shape 不同。live_zone_openai.rs 里把 scope 限定在最新 tool message 和最新 user text,而且明确不改 tools、tool_choice 这些定义区。它还对 n > 1 的请求直接 passthrough,因为多候选输出会让行为更难界定。
OpenAI Responses 又是另一套 item shape。于是 proxy 入口先把 endpoint 分出来,再走对应压缩函数:
match endpoint {
CompressibleEndpoint::AnthropicMessages => { /* Anthropic */ }
CompressibleEndpoint::OpenAiChatCompletions => { /* OpenAI Chat */ }
CompressibleEndpoint::OpenAiResponses => { /* OpenAI Responses */ }
}这个分支看起来不优雅,但很务实。Agent 请求不是抽象的“聊天消息”,而是 provider API 的具体 JSON。压缩层如果假装它们一样,最后很容易破坏工具调用、缓存语义或 provider 校验。
内容检测:先识别结构,再选压缩器
live zone 只是确定“哪里可以动”。下一步是判断“这段内容是什么”。content_detector.rs 把输入分成几类:
- JSON 数组。
- 源码。
- 搜索结果。
- 构建输出或日志。
- Git diff。
- HTML。
- 普通文本。
这个检测器是规则型的,源码注释里也强调没有 ML、没有 I/O。这样做的好处是 proxy 热路径稳定、可预测、容易做 parity test。它不追求语义理解,而是把明显有结构的上下文交给对应压缩器。
压缩器大致可以按输入类型理解:
| 输入类型 | 压缩器 | 主要策略 |
|---|---|---|
| JSON 数组 | SmartCrusher | 保 schema、抽样行、把丢弃行放进 CCR |
| 构建日志 | LogCompressor | 按错误、警告、命令、路径等类别评分和裁剪 |
| grep/ripgrep 结果 | SearchCompressor | 按文件和匹配行聚合,保留相关片段 |
| unified diff | DiffCompressor | 限制文件和 hunk,裁剪上下文 |
| 源码 | 当前 Rust 路径多为 no-op | 保守处理,避免破坏代码语义 |
这里能看出 Headroom 的工程取舍:它优先压缩那些“人类也会摘要”的输出,比如日志、搜索结果、diff、大 JSON 数组;对源码这种细节敏感的输入,则暂时更保守。
SmartCrusher:压 JSON 不是截断 JSON
SmartCrusher 负责处理 JSON 数组。简单截断 JSON 很危险,因为模型经常需要知道字段 schema、字段分布、异常行和少量代表样本。Headroom 的做法是先把数组转成中间表示,再分析结构是否统一,最后输出更短但仍保留 schema 的表示。
默认配置也透露了它的思路:
min_items_to_analyze: 5,
min_tokens_to_crush: 200,
max_items_after_crush: 15,
enable_ccr_marker: true,也就是说,小数组和短内容不值得压;真正要压时,先保留 schema 和代表行。对于被裁掉的原始行,不是直接消失,而是进入 CCR 存储,并在上下文里留下 marker。
SmartCrusher 的另一点是 lossless-first。它会优先尝试不丢信息的紧凑表达;只有收益不足时,才进入更激进的裁剪路径。这个顺序很重要,因为压缩层一旦默认丢信息,Agent 的行为就会变得很难解释。
CCR:线上 lossy,端到端 lossless
CCR 可以理解成 Headroom 的“原文逃生通道”。压缩器把大块原文存进本地 store,用 hash 生成 marker,prompt 里只留下类似这样的占位:
<<ccr:HASH>>crates/headroom-core/src/ccr/mod.rs 里定义了 CcrStore,后端包括内存、SQLite 和 Redis。默认 TTL 是 1800 秒,默认容量是 1000,key 由 BLAKE3 派生并截取前 24 个十六进制字符。
这让 Headroom 的信息模型变成两层:
- wire 上给模型的是短上下文,可能已经丢掉了部分原始行。
- 本地 store 里保留原文,模型可以通过 MCP retrieve tool 按 marker 取回。
所以它不是“不可逆摘要器”。更准确地说,它把 prompt 里的长上下文改成了引用式上下文:默认不给全量,必要时再取。ccr_roundtrip 测试也围绕这个行为写:压缩、存储、取回、重建必须能闭环。
缓存稳定和失败回退
Headroom 的 proxy 路径有几个保守点值得注意。
第一,压缩只发生在 live zone 内。外部字节不动,是为了尽量不破坏 provider prompt cache,也避免重序列化 JSON 带来的格式漂移。
第二,压缩错误是可恢复的。live zone 的 outcome 分为 NoChange 和 Modified,遇到不能处理的输入时可以回到原始 bytes 转发。proxy 里也有 Outcome::NoCompression 分支,直接使用 buffered 原请求。
第三,不同认证和计费模式下策略不同。源码里有 auth mode 分类、PAYG fallback,以及 PAYG-only normalization pass。也就是说,Headroom 不把所有请求都当成同一种商业路径处理。
第四,它会做只读检测。volatile detector 和 cache drift detector 不直接改请求,而是帮助判断上下文变化和缓存风险。压缩层要进入生产链路,光有压缩率不够,还要能解释“为什么这次压了、为什么这次没压”。
测试如何锁住行为
这个项目的测试不是只测函数返回值,还在锁几个关键不变量。
live_zone_dispatch 测试覆盖了内容类型到压缩器的路由:JSON tool_result 应该进 SmartCrusher,日志进 LogCompressor,diff 进 DiffCompressor,源码目前保持 no-op。
更重要的是字节保真测试。它会检查压缩块外部的 prefix 和 suffix 是否保持一致,并确认被压缩的块确实显著变短。这个测试直接对应 Headroom 的核心承诺:只改 live zone,不碰 frozen 区。
ccr_roundtrip 则测试 CCR 闭环:压缩后 marker 必须能在 store 里找到,取回后能恢复原始 payload。没有这个测试,CCR 很容易退化成“把内容删掉并留下一个看起来像引用的字符串”。
设计取舍:它强在哪里,也限制在哪里
Headroom 最强的点是插入位置。它不要求每个 Agent 框架都改 prompt 构造逻辑,而是站在 provider request 之前做透明处理。对于 Claude、Codex 这类已有工具链,wrap 启动本地 proxy 并改 base URL,是很现实的接入方式。
第二个强点是它把 provider shape 当成一等约束。很多上下文压缩方案停留在“文本太长,所以摘要一下”,但 Agent 请求里有工具定义、工具调用、thinking block、cache 边界、response format、multi-output 参数。Headroom 的 provider-specific walker 虽然写起来更重,但更符合真实 API。
第三个强点是 CCR。上下文压缩最大的争议通常是“你删掉的信息之后怎么办”。CCR 给了一个工程答案:删出 prompt,但不要删出系统。模型能按需 retrieve,用户也能在本地存储里保留原文。
限制也很明显:
- 它只拦截明确支持的 endpoint 和 JSON 请求。
- OpenAI Chat 的
n > 1等场景会保守 passthrough。 - Rust 路径下源码压缩目前很谨慎,很多 source code 输入不会被压。
- CCR 把一部分可靠性转移到了本地 store 和 MCP retrieve tool。
- 仓库里有不少 roadmap 和实验性能力,阅读时应该以源码和测试为准,而不是只看 README 的愿景列表。
这些限制不是坏事。对于一个坐在 Agent 和 provider 中间的代理层,保守边界比盲目覆盖更重要。
建议的源码阅读顺序
如果只想快速理解 Headroom,可以按这个顺序读:
README.md:先看它对外宣称的接入方式和总架构。headroom/cli/wrap.py:理解它怎么启动 proxy、怎么给 Claude/Codex 注入 base URL。crates/headroom-proxy/src/proxy.rs:看请求从 HTTP 入口到压缩函数的门控。crates/headroom-proxy/src/compression/mod.rs:看可压缩 endpoint 的分类。crates/headroom-core/src/transforms/live_zone.rs:看 live zone、不变量和 provider dispatch。crates/headroom-core/src/transforms/content_detector.rs:看内容类型如何判定。crates/headroom-core/src/transforms/smart_crusher/、log_compressor.rs、search_compressor.rs、diff_compressor.rs:看不同压缩器的策略。crates/headroom-core/src/ccr/:看原文如何存储、marker 如何生成、retrieve 如何闭环。crates/headroom-core/tests/live_zone_dispatch.rs和ccr_roundtrip.rs:看项目最关心哪些行为不能坏。
总结
Headroom 的价值不在于某一个压缩算法多精巧,而在于它把上下文压缩放到了正确的位置:Agent 输出之后,LLM 请求之前。
这个位置带来的问题很多:不同 provider 的 JSON shape、prompt cache、工具调用、thinking block、认证模式、失败回退、原文取回。Headroom 的源码基本都在围绕这些问题做边界设计。
所以它更像一层 Agent context runtime,而不是一个文本压缩工具。它让上下文不再只有“全塞进 prompt”或“提前摘要掉”两种选择,而是多了第三种路径:本地保留原文,prompt 里放结构化压缩结果和可追回引用,把 token 预算留给真正需要模型判断的部分。