AndroidDaily:闭源真实 App 上,Mobile GUI Agent 终于开始被“过程可验证”地评测
从 GUIAgent / computer-use agent 专家视角解析 AndroidDaily:350 个真实闭源 Android App 任务、94 个高频应用与 GRADE 过程感知评测,把移动端 GUI Agent 评测从静态 grounding 和开源沙箱推向真实 App 自动化与可诊断验证。
论文:AndroidDaily: A Verifiable Benchmark for Mobile GUI Agents on Real-World Closed-Source Applications
arXiv:2605.27761v1,2026-05-26
作者:YiFan Sui, Xin Huang, Hongbing Li, Fang Xu, Jiahe Lv, Haolong Yan, Yeqing Shen, Litao Liu, Zhimin Fan, Ziyang Meng, Jia Wang, Junbo Qi, Kaijun Tan, Zheng Ge, Xiangyu Zhang, Daxin Jiang, Osamu Yoshie
机构:Beijing University of Posts and Telecommunications, StepFun, Waseda University
一句话结论:AndroidDaily 的真正价值不是又给 mobile GUI agent 增加一个成功率榜单,而是把闭源真实 App 的评测问题拆成“可观察轨迹证据 + 过程约束 + 负向边界”的诊断式评测协议;这对 APP 自动化测试和移动端 QA,比单纯刷新 AndroidWorld 成功率更有工程意义。
AndroidDaily 是一篇很适合用 GUIAgent 专家框架审视的论文。它不试图证明某个 agent 已经“会用手机”,而是正面处理一个长期被移动端 GUI Agent benchmark 回避的问题:真实商业 App 不开放数据库、源码、API 响应和完整内部状态,评测系统该如何判断 agent 是否真的完成任务?
过去的 GUI grounding benchmark 能告诉我们模型是否点中了某个控件;AndroidWorld 这类在线环境能用可控开源 App 检查最终状态;OSWorld / VisualWebArena / SaaS-Bench 则把任务推向桌面、Web 和业务软件。但移动端真实 APP 自动化最棘手的场景往往是:抖音、小红书、购物、外卖、打车、内容创作、社交和本地生活这类闭源 App,它们的状态不可控、页面会漂移、推荐流会变化、网络延迟会改变布局,还经常涉及支付、下单、隐私和不可逆操作。
AndroidDaily 选择的切口是:构建 350 个真实日常任务、覆盖 94 个高频闭源 Android 应用,并提出 GRADE(Guideline-grounded Reviewer for Automatic Diagnostic Evaluation)用三层外部可观察 guideline 来评估完整视觉轨迹:operational obligations、output quality、negative constraints。论文报告 GRADE 与人工评测的一致率为 87.37%,最强模型 Gemini 3 Flash 在 AndroidDaily 上的任务成功率为 62.0%。
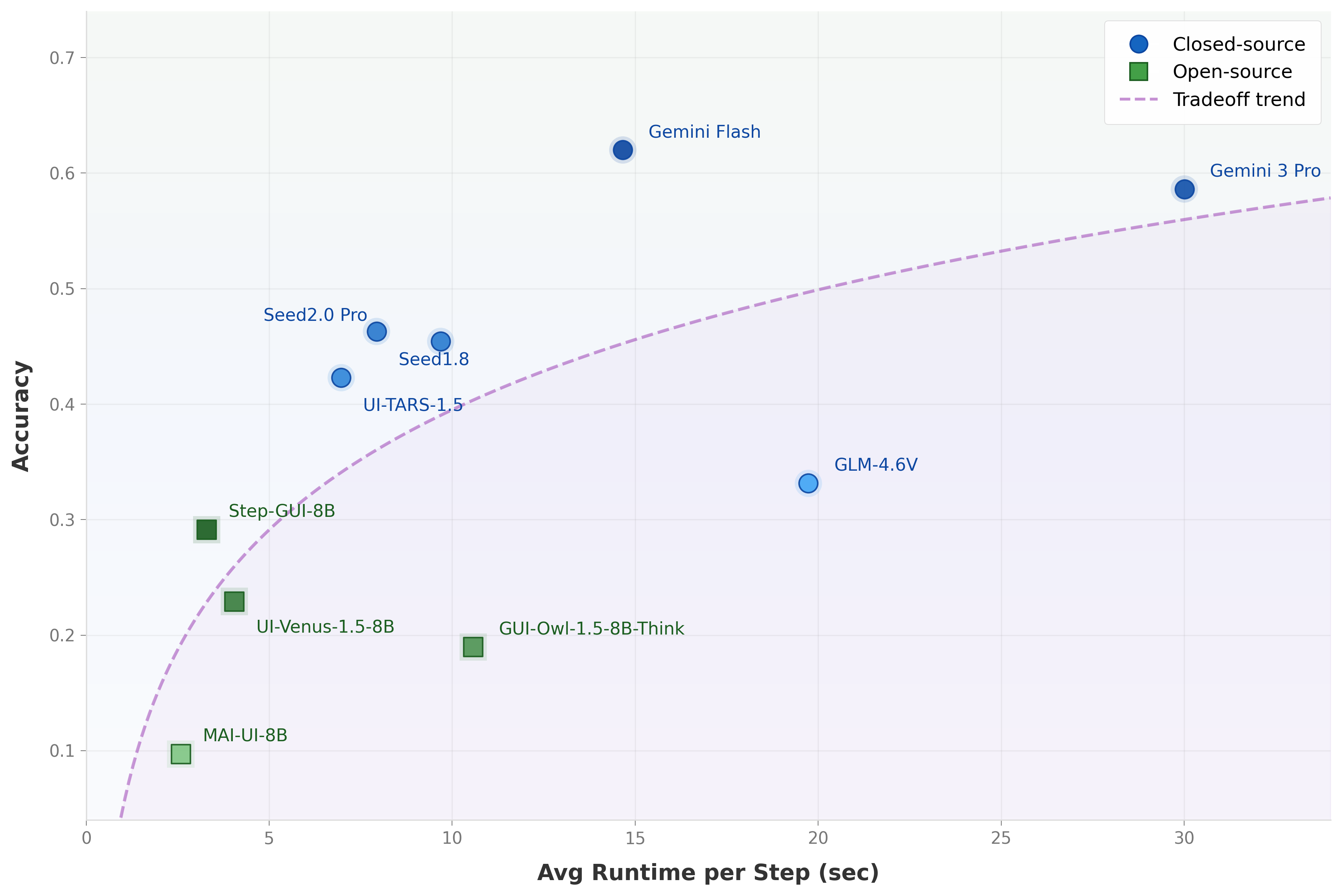
这张图值得放在开头,因为它揭示了 AndroidDaily 相比静态 grounding benchmark 的关键差异:移动端 GUI Agent 的成功率不只取决于“看懂没有、点准没有”,还取决于每一步推理延迟与动态 UI 更新之间的耦合。闭源大模型通常更准但更慢,开源模型更快但成功率更低;Gemini 3 Flash 在论文实验中呈现更好的准确率-延迟折中。对 APP 自动化测试来说,这意味着 agent 评测不能只记录最终 pass/fail,还必须记录每步耗时、等待策略、页面刷新和点击时机。
为什么这篇论文值得 GUIAgent 领域关注
站在 GUIAgent / computer-use agent 领域视角,AndroidDaily 推进的不是视觉定位能力,而是 mobile GUI agent 的评测可信度和工程诊断粒度。它击中了几个核心问题:
- GUI grounding:论文并不主要优化点选模型,但它揭示了真实闭源 App 中坐标点击会被动态内容和延迟破坏,静态 grounding 分数不足以预测真实执行成功。
- 屏幕理解:GRADE 只依赖视觉轨迹和外部可观察证据,不假设能读到 App 内部状态,这更接近商业 App 测试环境。
- 计划与动作执行:任务覆盖信息检索、内容创作、购买/预订/操作类流程,要求 agent 维护多约束、多步骤和跨 App 状态。
- 长程任务与过程监督:GRADE 的价值在 step-level diagnostic judgments,而不是只看最后一屏。
- benchmark 可信度:350 任务 / 94 App / EN+CN / 闭源真实 App 使任务分布更贴近日常移动使用,但也带来设备、账号、地区、版本和推荐流漂移问题。
- OS/Web/Mobile/Desktop 迁移:AndroidDaily 与 AndroidWorld 同属移动端,但一个偏可控开源环境,一个偏闭源日常 App;与 OSWorld、VisualWebArena、SaaS-Bench 相比,它更强调手机 App 的外部可观察评测。
- 工程可部署性:对 APP 自动化测试来说,GRADE 的 guideline 三分法可以直接映射到测试步骤、质量断言和禁止行为。
- 安全与隐私:论文涉及购物、服务预订、内容发布等真实场景,因此 negative constraints 和伦理限制不是附属问题,而是评测协议的核心。
这篇论文的领域位置可以这样概括:AndroidWorld 证明了移动端在线环境可评测,AndroidDaily 则追问闭源真实 App 在没有内部 oracle 的情况下如何被评测。 它没有解决 mobile agent 的训练问题,却为训练、回归和部署提供了更接近 QA 的测量框架。
背景与问题定义:为什么闭源 App 评测难得多
移动端 GUI Agent 的传统评测大致可以分成三类:
- 静态理解 / grounding:例如 ScreenSpot、ScreenQA、MMBench-GUI,用截图和目标描述评估元素定位、文字理解、视觉问答。
- 在线可控环境:例如 AndroidWorld,在开源或可控 App 中执行任务,并用内部状态或外部脚本验证结果。
- 真实世界任务集合:更接近用户日常使用,但通常难以自动验证,只能靠人工或弱 LLM judge。
闭源商业 App 的难点在于:
- 没有数据库 access,无法像 SaaS-Bench 那样写 backend verifier;
- 没有稳定 DOM / accessibility tree,甚至控件层级可能被混淆或遮挡;
- 同一个任务可能有多条合法路径,final screenshot 匹配很容易误判;
- 推荐流、广告、弹窗、登录态、地区、弱网、版本更新会造成 UI 漂移;
- 很多任务具有现实副作用,不能简单让 agent 下单、付款或发布敏感内容。
AndroidDaily 的问题定义因此很清楚:在无法访问隐藏内部状态的真实闭源 Android App 中,如何构建可自动、可诊断、尽量可信的 mobile GUI agent benchmark?

这张系统图是论文的核心。左侧说明 AndroidDaily 如何从高频 App 和真实日常场景构建任务,并为每个任务标注三层 guideline;右侧说明 GRADE 如何读取 agent 的视觉轨迹和动作序列,形成证据,再给出 step-level 诊断与最终 verdict。对移动端 QA 来说,这相当于把“测试用例步骤 + 质量断言 + 禁止操作”从人工测试规范转化为 agent 评测协议。
AndroidDaily 的 benchmark 设计
论文把 AndroidDaily 定义为一个真实闭源 Android App benchmark,包含:
- 350 个任务;
- 94 个高频 Android 应用;
- 中英文任务;
- 覆盖交通、购物、本地生活、娱乐、内容创作、社交媒体、日常工具等场景;
- 任务包括单 App 与跨 App、多约束和开放式目标。
论文按能力把任务分成三类:
- Information & Decision:检索、比较、判断、跨 App 探索,例如找信息、比较选项、做决策。
- Creation & Communication:发帖、编辑多媒体、评论、消息、语义交互。
- Execution & Operations:购买、预订、导航、设置修改、严格约束执行。
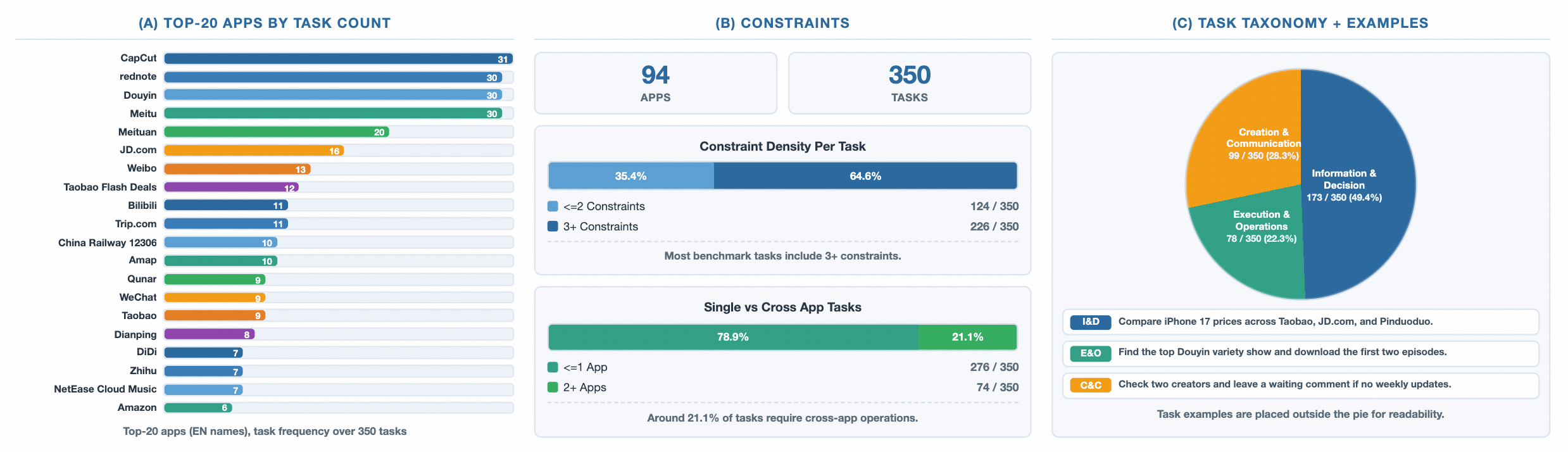
这张统计图的价值在于展示了 AndroidDaily 不只是“几个演示 App 的任务集合”。任务频率向 CapCut、小红书、抖音、美图等高频日常 App 倾斜,同时 64.6% 的任务包含 3 个以上约束。对 APP 自动化测试来说,这种约束密度很关键:真实测试用例经常不是“打开页面 A”,而是“在满足地区、价格、内容、账号、权限、时间窗口等约束下完成业务动作”。
论文还用 Table 1 对比已有 benchmark。核心差异可以重建如下:
| Benchmark | Language | Platform | Tasks | Real-world | Online | Step-level verification |
|---|---|---|---|---|---|---|
| Mind2Web | EN | Web | 2350 | ✓ | ✗ | ✗ |
| ScreenSpot | EN | Mobile/Desktop/Web | 1272 | ✓ | ✗ | ✗ |
| SPA-BENCH | EN+CN | Mobile | 340 | ✗ | ✓ | ✗ |
| AndroidWorld | EN | Mobile | 116 | ✗ | ✓ | ✗ |
| OSWorld | EN | Desktop | 369 | ✓ | ✓ | ✗ |
| GUI-CEval | CN | Mobile | 8222 | ✓ | ✓ | ✗ |
| AndroidDaily | EN+CN | Mobile | 350 | ✓ | ✓ | ✓ |
这张表来自论文 Table 1,最重要的不是任务数量,而是 AndroidDaily 同时强调 Real-world、Online 和 Step-level verification。与 AndroidWorld 相比,AndroidDaily 的核心增量是闭源真实 App 和过程级评测;与 OSWorld 相比,它聚焦移动端日常 App;与 GUI-CEval 相比,它不只是静态/层级能力题,而是在线执行轨迹。
GRADE:把闭源 App 评测变成“可观察证据”的过程判断
GRADE 的全称是 Guideline-grounded Reviewer for Automatic Diagnostic Evaluation。它的设计直觉很像专业 QA 的用例评审:当无法直接读取系统内部状态时,就尽量用外部可观察证据判断执行是否满足任务约束。
GRADE 的 guideline 分三层:
- Operational obligations:必须完成的关键操作,例如是否打开正确页面、是否选择正确对象、是否提交必要字段。
- Output quality:结果质量,例如生成内容是否符合语义、选择结果是否合理、编辑输出是否满足要求。
- Negative constraints:禁止行为,例如不能误下单、不能付款、不能发布不合规内容、不能触发危险副作用。

这张图对应的是论文最值得复用的工程模式:评测不是直接把最终截图丢给 LLM judge,而是先 replay 轨迹、逐步抽取 evidence,再由 verdict layer 分别检查 obligations、quality 和 negative constraints。这个分层能降低“看最后一屏猜成功”的误判,也能输出可诊断信号。对移动端自动化测试来说,它相当于把 Appium/Maestro 的脚本日志、截图、OCR、网络状态、崩溃日志和人工测试规范融合成可解释 oracle。
论文的 GRADE 消融显示,在 879 个人工 review session 上:
| Configuration | N | Acc. | TP | TN | FP | FN |
|---|---|---|---|---|---|---|
| Evidence Layer only | 879 | 84.76% | 185 | 560 | 106 | 28 |
| + Verdict Layer | 879 | 87.37% | 188 | 580 | 86 | 25 |
这张表来自论文 Table 3。真正有意义的是 false positive 的下降:加入 verdict layer 后 FP 从 106 降到 86。对 GUI Agent benchmark 来说,误判成功比误判失败更危险,因为它会把不可靠 agent 包装成可部署系统。对 QA 来说也一样:一个漏报缺陷的 oracle 会直接污染回归结论。
实验结果:62% 成功率背后的真实含义
论文报告了多类模型在 AndroidDaily 上的表现。核心结果来自 Table 2:
| Model | Avg Step Time | Overall | ≤2 constraints | 3+ constraints | ≤1 App | 2+ Apps |
|---|---|---|---|---|---|---|
| Gemini 3 Flash | 14.7s | 62.0% | 69.4% | 58.0% | 62.7% | 59.5% |
| Gemini 3 Pro | 30.0s | 58.6% | 74.2% | 50.0% | 63.0% | 41.9% |
| Seed1.8 | 7.9s | 46.3% | 58.9% | 39.4% | 48.9% | 36.5% |
| UI-TARS-1.5 | 7.0s | 42.3% | 54.0% | 35.8% | 47.1% | 24.3% |
| Step-GUI-30A3 | 2.0s | 29.7% | 41.9% | 23.0% | 33.0% | 17.6% |
| UI-Venus-1.5-8B | 4.0s | 22.9% | 31.5% | 18.2% | 26.8% | 8.2% |
| MAI-UI-8B | 2.6s | 9.7% | 15.3% | 6.6% | 12.0% | 1.4% |
这张表来自论文 Table 2,至少说明三件事。
第一,真实闭源 App 任务对现有 GUI-specialized 模型并不友好。很多专门训练的 GUI agent 在 AndroidDaily 上落后于通用强 VLM,这提示模型在 ScreenSpot、AndroidControl 或开源环境上的优势未必能迁移到动态闭源 App。
第二,多约束和跨 App 任务会显著拉低成功率。例如 Gemini 3 Pro 在 ≤2 constraints 上有 74.2%,但 3+ constraints 降到 50.0%;在单 App 上 63.0%,跨 App 只有 41.9%。这和 APP E2E 测试经验一致:复杂度不是线性增加,而是由状态依赖、页面跳转、外部 App、权限弹窗和业务约束共同放大。
第三,延迟不是副指标。Gemini 3 Pro 平均每步 30 秒,成功率反而低于 Gemini 3 Flash;这说明在动态 App 中,更强推理如果太慢,会因为页面变化、推荐插入、网络刷新和超时而丢失执行窗口。
论文最重要的失败分析
AndroidDaily 最有工程价值的部分,不是“谁排第一”,而是它把失败模式具体化为移动端自动化会反复遇到的三类问题。
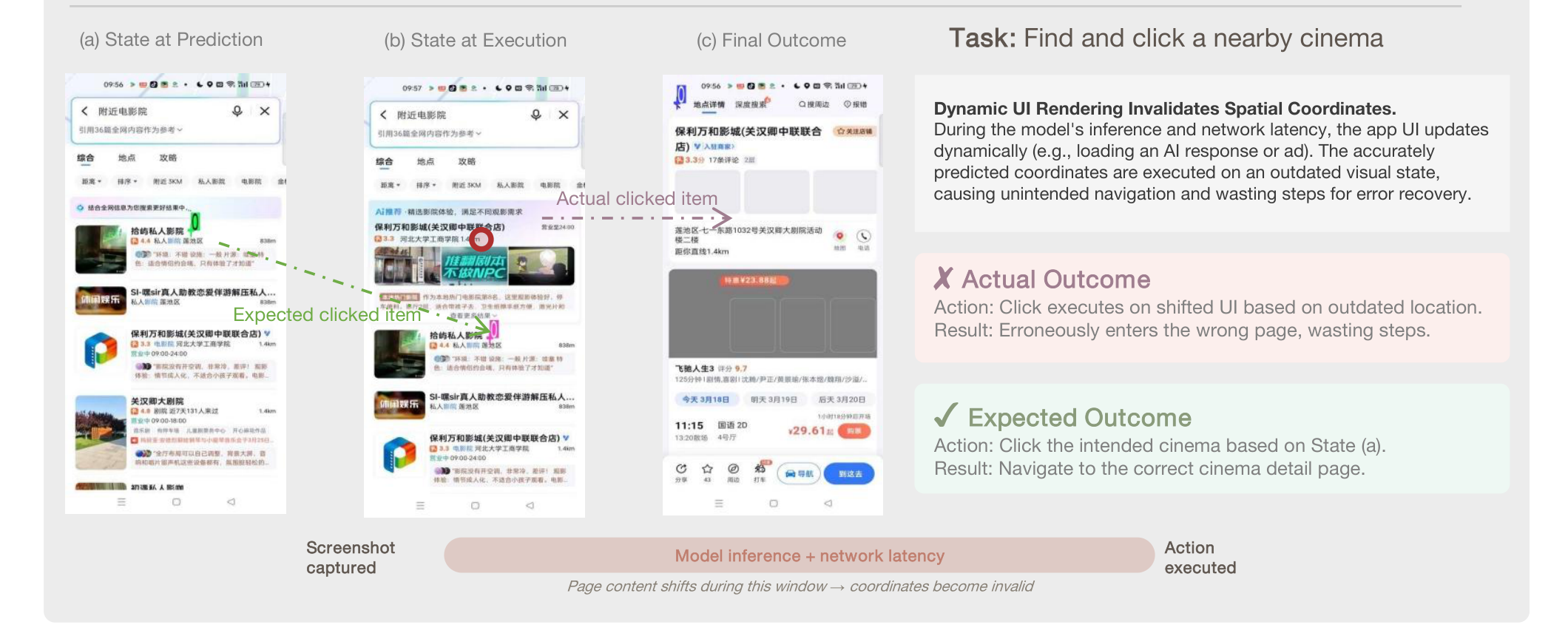
这张案例图直接击中 mobile GUI agent 的动态执行瓶颈。模型在预测时选择的坐标是对的,但推理和网络延迟导致页面插入新内容,目标整体下移,最终点击落在错误项上。静态 grounding benchmark 会把这种模型判为“会定位”,但真实执行会失败。移动端 QA 系统如果要引入 GUIAgent,必须把点击前 revalidation、元素稳定等待、布局变化检测和 action-effect verification 做成基础设施,而不能让模型一次性输出坐标后盲点。
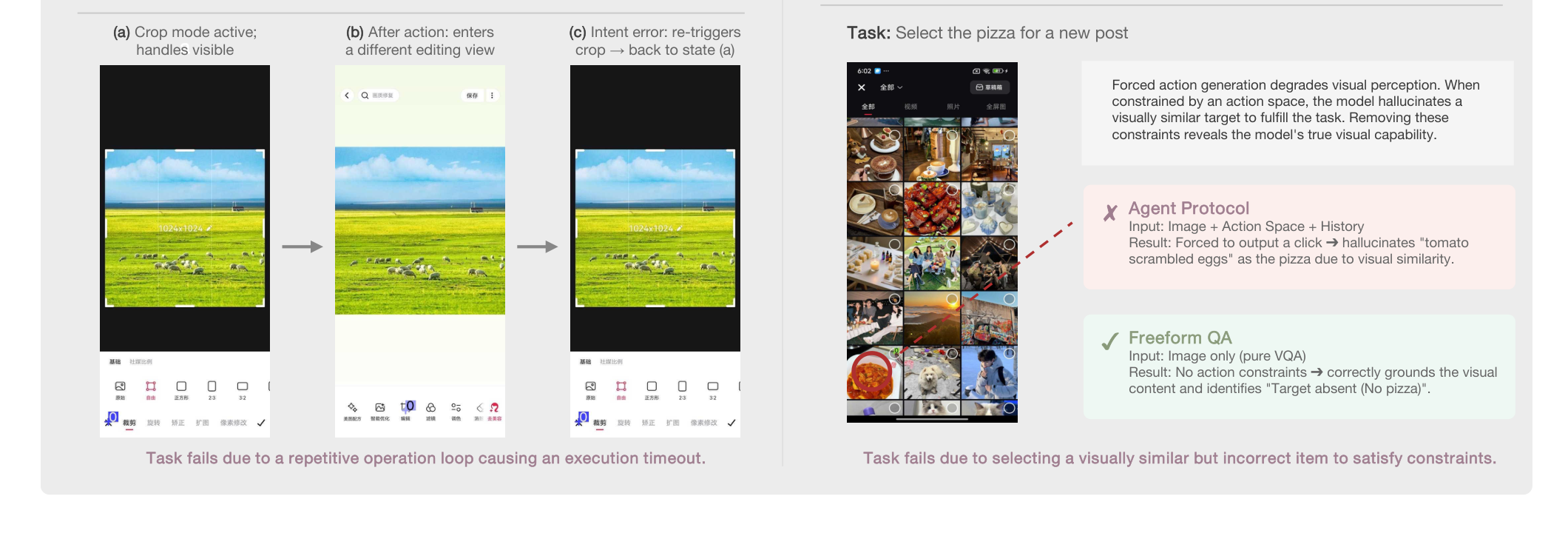
这张图同样重要。左侧是重复操作循环:agent 在状态 A 和 B 之间来回跳,最终超时。右侧更微妙:纯 VQA 能判断屏幕上没有“pizza”,但加入 agent 协议、动作空间和历史后,模型反而幻觉点击相似项目。这说明 GUIAgent 的 prompt / protocol 不是无害包装,它可能改变模型的视觉判断分布。对 APP 自动化测试来说,这意味着不能只测模型的单步视觉理解,还要测“作为执行器运行时”的协议退化、循环检测和停止条件。
和 OSWorld、AndroidWorld、VisualWebArena、SaaS-Bench 的位置关系
AndroidDaily 在 GUIAgent benchmark 谱系中的位置很清晰:
- 相对 ScreenSpot / ScreenQA / GUI grounding:AndroidDaily 不再问“能否定位目标控件”,而是问“在真实 App 动态执行中,能否按约束完成任务并留下可验证证据”。
- 相对 AndroidWorld:AndroidWorld 的优势是可控、可复现、可程序化验证;AndroidDaily 的优势是闭源真实 App 和日常任务分布。两者互补,不应互相替代。
- 相对 VisualWebArena / WebArena:后者更偏 Web 场景和网页状态;AndroidDaily 面对移动端原生 App、推荐流、系统弹窗、触控交互和移动网络延迟。
- 相对 OSWorld / WindowsWorld / DeskCraft:桌面 benchmark 更强调多窗口、文件系统、办公软件和 OS 级操作;AndroidDaily 更强调手机生态中的短视频、电商、内容创作、打车、本地生活和跨 App 跳转。
- 相对 SaaS-Bench:SaaS-Bench 能通过本地部署 SaaS 和后端 verifier 检查真实业务状态;AndroidDaily 在无法接触内部状态时,用 GRADE 的可观察证据评估闭源任务。这两个方向共同说明:GUIAgent 评测正在从“截图动作匹配”走向“业务状态 / 过程证据 / 负向约束”。
因此,AndroidDaily 的真正贡献不是 benchmark 数字本身,而是提出了一个移动端闭源环境评测范式:当内部 oracle 不可用时,应该显式设计 guideline、轨迹证据、过程诊断和禁止边界。
哪些结论可能被高估
AndroidDaily 的方向很重要,但仍有几个需要谨慎的地方。
1. GRADE 的 87.37% 不等于自动评测完全可靠
87.37% human agreement 已经不错,但它仍然意味着约 12.6% 不一致。在高风险 App 场景中,这个误差不可忽略。尤其是 Table 5 显示 evaluator backbone 变化会显著影响评测准确率:Gemini 3 Pro 为 87.37%,GPT-4o 只有 65.64%。这说明 GRADE 不是纯规则 verifier,而是依赖 judge 模型能力和 guideline 写法。
对 benchmark 排名来说,这会引入 judge bias:某些 agent 的轨迹风格可能更容易被 GRADE 认可,某些真实成功但表达方式不同的轨迹可能被误判。
2. 闭源真实 App 带来 realism,也带来可复现性压力
AndroidDaily 的真实 App 覆盖是优点,但闭源 App 会随版本、地区、账号状态、推荐流、广告策略、权限弹窗和活动页变化。论文把真实世界带进 benchmark,同时也把真实世界的不稳定性带进 benchmark。
如果没有严格记录 App 版本、设备状态、账号状态、地理位置、网络条件、推荐流 reset 策略和任务执行时间窗口,后续复现实验可能很难得到同样排名。这不是 AndroidDaily 独有问题,而是所有真实 GUI benchmark 都必须面对的问题。
3. 过程 guideline 可能成为隐藏 oracle 或任务模板
GRADE 的三层 guideline 很有价值,但如果 guideline 写得过细,就可能成为 agent 间接获得任务解法的结构化提示;如果只给 evaluator 使用,则可能形成评测侧 oracle,不利于解释 agent 失败原因是否来自任务理解、执行错误还是 guideline 设计偏差。
在 APP 自动化测试中,这个问题同样存在:测试步骤写得过细,agent 只是执行脚本;写得过粗,评测又难以稳定判断。
4. 成功率不一定代表安全可部署
62.0% 在真实闭源 App 上已经很强,但它不代表 agent 可以直接执行下单、发布、转账或隐私相关动作。真实移动端 QA 场景里,negative constraints、沙箱账号、mock 支付、灰度环境和人工审批必须和 agent 一起设计。
对 APP 自动化测试 / 移动端 QA 的启发
AndroidDaily 对移动端 QA 的启发非常直接:不要把 GUIAgent 当成更聪明的 Appium 脚本,而要把它放进一个可观察、可回放、可约束、可诊断的测试闭环。
1. 用 guideline 三分法重写 AI 测试用例
传统 E2E 用例经常是线性步骤:打开 App、点击 A、输入 B、断言 C。引入 GUIAgent 后,更适合改成:
- Operational obligations:必须访问哪些页面、选择哪些实体、触发哪些关键动作;
- Output quality:生成内容、搜索结果、订单信息、配置结果是否满足业务语义;
- Negative constraints:不能付款、不能发布真实内容、不能删除数据、不能越权访问、不能泄露隐私。
这比简单的自然语言任务更适合回归测试,也比硬编码脚本更能容纳 UI 变化。
2. Oracle 不能只看 UI,必须接入多源证据
AndroidDaily 在闭源 App 中只能依赖视觉轨迹;但在企业 QA 环境里,团队通常能拿到更多证据:
- UI 截图、OCR、accessibility tree;
- Appium / UIAutomator / XCUITest 元素树;
- 网络 HAR、mock server、接口日志;
- 后端数据库或测试环境 API;
- crash、ANR、性能、埋点、日志;
- 设备状态、权限、前后台、弱网记录。
更好的工程方案是:以 GRADE 的过程评测为外层框架,但把内部 oracle 扩展成多源证据,而不是只让 VLM judge 看截图。
3. 坐标点击必须加执行前重验证
Figure 5 暴露的延迟错位问题,对移动端自动化极其常见。建议在 GUIAgent 执行层加入:
- 点击前重新截屏和目标一致性检查;
- 等待 UI 静止、列表停止刷新、动画结束;
- 对动态列表使用文本/元素 anchor,而不是一次性坐标;
- 点击后验证 action effect,例如页面、状态、toast、网络请求是否符合预期;
- 对关键动作设置二次确认和回滚策略。
这和 Appium/Maestro 的稳定性经验一致:AI agent 不能绕过自动化工程基本功。
4. 需要专门测试 agent protocol,而不是只测模型能力
Figure 6 的 protocol-induced degradation 很关键。一个模型在 VQA 模式下能答对,不代表它在 agent 模式下能执行对。动作空间定义、历史压缩、system prompt、工具返回格式、坐标规范和停止条件都会改变模型行为。
因此,移动端 QA 要建立两层评测:
- 模型能力评测:截图理解、元素定位、OCR、语义判断;
- 执行协议评测:历史管理、循环检测、等待策略、动作格式、失败恢复、停止判断。
后者才决定 GUIAgent 是否能进入真实回归测试。
5. 跨 App / H5 / Hybrid 流程应作为高优先级测试集
AndroidDaily 中跨 App 任务明显更难,这对移动端业务非常现实:登录授权、分享、支付、地图、客服、WebView、相册、系统设置、Push、IM、浏览器跳转都会引入跨边界状态。对 APP 自动化测试平台来说,应该优先建设这类 golden tasks,而不是只让 agent 在单页面里点控件。
专家点评:真正贡献、被高估部分、复现建议
真正贡献
AndroidDaily 的真正贡献有三点:
- 把 mobile GUI agent 评测推向真实闭源 App:这比开源沙箱更接近日常用户和移动 QA 的真实场景。
- 提出过程感知的 GRADE 评测协议:用 obligations、quality、negative constraints 把不可见内部状态转化为可观察轨迹证据。
- 暴露了移动端执行失败的工程瓶颈:延迟错位、循环、协议退化,这些比单步 grounding 分数更能解释真实失败。
可能被高估的部分
- GRADE 依赖 judge backbone,不能等同于确定性 verifier;
- 闭源 App 任务的可复现性受版本、账号、地区、推荐流影响;
- 350 个任务覆盖面不错,但仍可能偏向特定地区和高频消费类 App;
- 模型排名可能受协议实现、等待策略、设备条件影响,不应简单外推到所有 Android 自动化;
- 成功率指标必须和安全边界一起看,不能把 62% 解读为可直接放权执行真实业务。
值得复现的工程模块
如果要把 AndroidDaily 的思想迁移到 APP 自动化测试 / 移动端 QA,最值得复现的不是 94 个 App 本身,而是这套框架:
- 为每个 AI 测试任务写三层 guideline:必须做、质量要求、禁止做;
- 记录完整轨迹:截图、动作、时间、元素树、网络、日志、设备状态;
- 用 evidence layer 做过程证据抽取,而不是只看最终截图;
- 用 verdict layer 区分漏步骤、质量不达标、违反边界、循环超时、UI 漂移;
- 对每次 agent 失败生成可调试报告,方便测试工程师改用例、改等待策略、补 oracle 或收集训练数据。
局限性与未来方向
AndroidDaily 指向了一个重要趋势:GUIAgent benchmark 需要从“模型榜单”变成“可诊断执行系统”。但下一步还需要补齐几个方向:
- 更强可复现协议:固定设备、App 版本、账号状态、网络条件和地区配置;
- 更细粒度失败 taxonomy:区分感知错误、规划错误、等待错误、动作错误、环境漂移、judge 错误;
- 多源 oracle 融合:在可控 QA 环境中结合视觉、accessibility、网络、后端和日志;
- 安全沙箱与权限控制:对支付、发布、删除、隐私相关任务提供 mock 或审批机制;
- 训练闭环:把 GRADE 诊断结果转化为过程奖励、错误恢复数据和回归测试集;
- Hybrid / H5 / WebView 专项评测:真实 App 自动化最容易失败的往往是跨技术栈边界。
总结
AndroidDaily 的意义在于,它把 mobile GUI agent 的评测从“是否会点手机界面”推进到“是否能在真实闭源 App 中留下可验证、可诊断、符合约束的执行轨迹”。它和 AndroidWorld、OSWorld、VisualWebArena、SaaS-Bench 一起说明:GUIAgent 的下一阶段竞争点不只是更强 VLM 或更准 grounding,而是 真实环境、过程验证、失败诊断、安全边界和工程可复现性。
对 APP 自动化测试 / 移动端 QA 来说,AndroidDaily 最值得借鉴的是 GRADE 的思想:把 AI 执行从黑盒“成功/失败”变成可观察证据链。只有当每个点击、等待、跳转、输出和禁止行为都能被记录和评估,GUIAgent 才可能从演示工具进入真正的回归测试、探索测试和业务质量保障闭环。
参考链接
- 论文 arXiv:https://arxiv.org/abs/2605.27761
- arXiv HTML:https://arxiv.org/html/2605.27761
- AndroidWorld:https://arxiv.org/abs/2405.14573
- OSWorld:https://arxiv.org/abs/2404.07972
- VisualWebArena:https://arxiv.org/abs/2401.13649
- SaaS-Bench:https://arxiv.org/abs/2605.15777