MementoGUI:长程 GUI Agent 的瓶颈,正在从视觉定位转向多模态记忆控制
从 GUIAgent / computer-use agent 专家视角解析 MementoGUI:它把长程 GUI 控制从 raw history replay 和 text-only memory 推向可学习的多模态工作记忆与情景记忆控制,但其 offline benchmark、VLM judge 与低轨迹成功率也提示工程落地仍需谨慎。
论文:MementoGUI: Learning Agentic Multimodal Memory Control for Long-Horizon GUI Agents
arXiv:2605.18652v1,2026-05-18
项目页:zzzmyyzeng.github.io/MementoGUI
作者:Ziyun Zeng, Hang Hua, Bocheng Zou, Mu Cai, Rogerio Feris, Jiebo Luo
一句话结论:MementoGUI 的真正价值不是“又给 GUI Agent 加了一个记忆模块”,而是把长程 GUI 控制明确建模为“多模态记忆写入、压缩、检索与选择”的可学习控制问题;但它目前更像一个强研究原型,离可直接支撑 macOS 桌面自动化的可靠工程系统还有明显距离。
过去一年,GUI Agent / computer-use agent 的论文很容易围绕两个指标打转:一是 GUI grounding 能不能把指令定位到正确控件,二是 Web / Mobile / Desktop benchmark 上端到端成功率能不能涨几个点。MementoGUI 选择切入另一个更贴近长程自动化的痛点:模型不是看不见当前屏幕,而是记不住、记不准、不会决定什么历史应该继续影响下一步动作。
站在 GUIAgent 领域专家视角,这篇论文推进的是:把长程 GUI Agent 的上下文管理从 prompt 工程与被动历史拼接,推进到一个可训练的多模态记忆控制层。 这个方向对 OSWorld、AndroidWorld、VisualWebArena、SaaS-Bench、WindowsWorld 这类长程任务都很关键,因为真实软件操作中大量失败并不来自单步点击错误,而来自跨页面状态遗失、局部视觉证据消失、子目标完成状态混乱和重复操作。
不过也要先把预期压低:论文中最核心的 GUI-Odyssey 结果里,UI-Venus-1.5-8B 从无历史的 54.58 AMS / 1.29 trajectory success 提升到工作记忆 + 情景记忆的 68.32 AMS / 3.57 trajectory success。动作匹配明显变好,但整条轨迹成功率仍然非常低。 这说明 MementoGUI 解决的是长程 Agent 的一个真实瓶颈,而不是把长程 GUI 自动化变成了已解决问题。
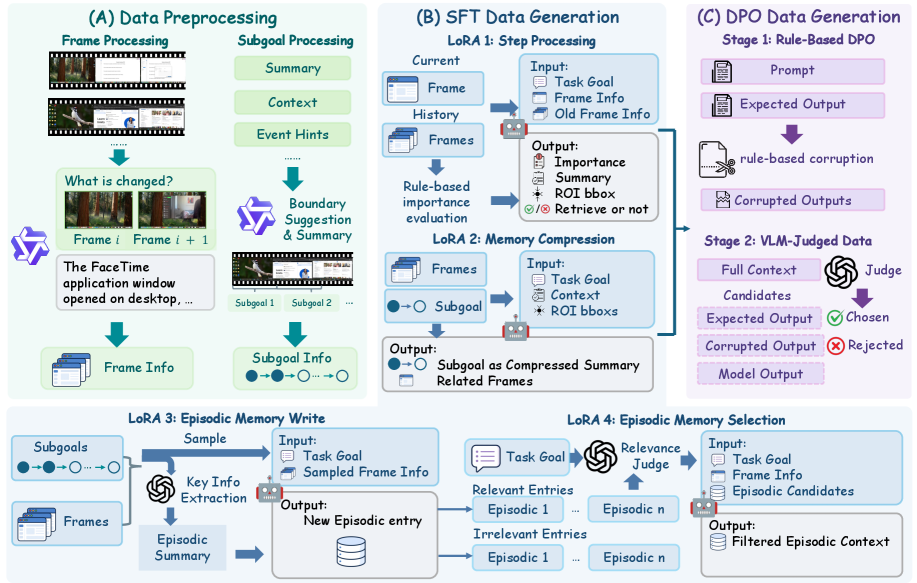
这张图值得先看,因为它暴露了 MementoGUI 的一个关键前提:论文并不是只在推理时“加一段记忆提示词”,而是先把原始 GUI 操作视频解析成层级标注,再为 step processing、memory compression、episodic writing、episodic selection 四类记忆算子构造监督数据。也就是说,它把长程 GUI 控制中的“什么该被记住”变成了可训练对象。
为什么这篇论文值得 GUIAgent 领域关注
如果按 GUIAgent 专家框架审视候选论文,MementoGUI 击中的不是单纯 GUI grounding,而是以下几个关键问题:
- 屏幕理解与记忆耦合:不仅看当前截图,还保留过去步骤中的 ROI 视觉证据。
- 计划与动作执行:动作模型不 finetune,而是在动作输入前构造更有用的记忆上下文。
- 长程任务:明确针对几十步以上任务中状态遗失、约束遗忘、循环与停滞问题。
- 过程监督 / 偏好学习:用 PSAI computer-use 轨迹自动构造 SFT 数据,并对部分记忆算子做 DPO。
- benchmark 可信度:引入 MementoGUI-Bench 和 VLM-based 指标,但也带来 judge bias 与 offline evaluation 的问题。
- OS / Web / Mobile / Desktop 迁移:实验覆盖 GUI-Odyssey、MM-Mind2Web 和自建 benchmark,更偏移动与 Web,桌面 OS 原生场景仍需验证。
- 工程部署性:plug-in、冻结动作模型、不改 backbone 架构,这些设计对真实系统有吸引力;但多次 VLM 调用、ROI 管理、记忆污染和延迟成本也很现实。
- 安全与隐私:论文重点不在安全,但长期保存 GUI 轨迹、ROI crop 与跨 episode 经验,对隐私、凭据和敏感业务数据提出了更高要求。
这篇论文值得关注,是因为它和最近很多“更大 GUI foundation model”“更强 grounding benchmark”的方向形成互补:当模型已经能识别按钮和输入框后,下一阶段的瓶颈会越来越像状态管理问题。
背景与问题定义
GUI Agent 长程失败通常有几类典型模式:
- 临时 UI 状态消失:例如下拉菜单里选过某个选项,页面跳转后当前截图不再显示这个信息。
- 用户约束被遗忘:例如任务开头要求“只处理高优先级 issue”或“不要修改已完成项”,十几步后模型开始泛化执行。
- 子目标状态混乱:模型不知道自己已经完成了哪些步骤,于是重复创建、重复提交或漏掉最后确认。
- 历史截图太多反而干扰:把所有截图、动作、OCR 都塞进上下文,会引入大量无关噪声,还消耗 token 和推理时间。
- text-only summary 丢失视觉锚点:文字总结可能说“选择了第二个选项”,但未来再定位时缺少局部视觉证据,特别是在相似控件、相似列表项和动态 UI 中。
MementoGUI 的问题定义是:给定任务目标 g 和一条 GUI episode 的截图序列,动作模型 π_B 是冻结的;系统需要通过一个外部 memory controller 来决定在每一步给动作模型注入什么上下文。论文的核心假设是:
长程 GUI control 不应该被看成“上下文窗口不够长”的问题,而应该被看成“多模态记忆控制”的问题。
这个判断非常符合 GUIAgent 领域的发展趋势。OSWorld、WebArena、VisualWebArena、AndroidWorld 等 benchmark 都说明:随着任务长度增加,成功率急剧下降;而失败经常不是单步视觉识别错误,而是上下文、状态与目标管理失控。
核心方法拆解
1. 冻结 GUI action backbone,把学习集中在 MementoCore
MementoGUI 的系统由四部分组成:
- 冻结的 GUI 动作骨干模型
π_B; - 当前 episode 内的 working memory;
- 跨 episode 的 episodic memory bank;
- 负责写入、压缩、检索、选择的 MementoCore。
这个设计的工程意义很大:它不要求重新训练 UI-Venus、GUI-Owl、MAI-UI 这类动作模型,也不需要给 backbone 加特殊 memory token 或 projection layer,而是通过普通多模态 chat interface 注入文本摘要和 ROI 图像。
换句话说,MementoGUI 更像一个 memory middleware:动作模型仍然负责“看屏幕并输出动作”,MementoCore 负责“把过去哪些东西带到现在”。
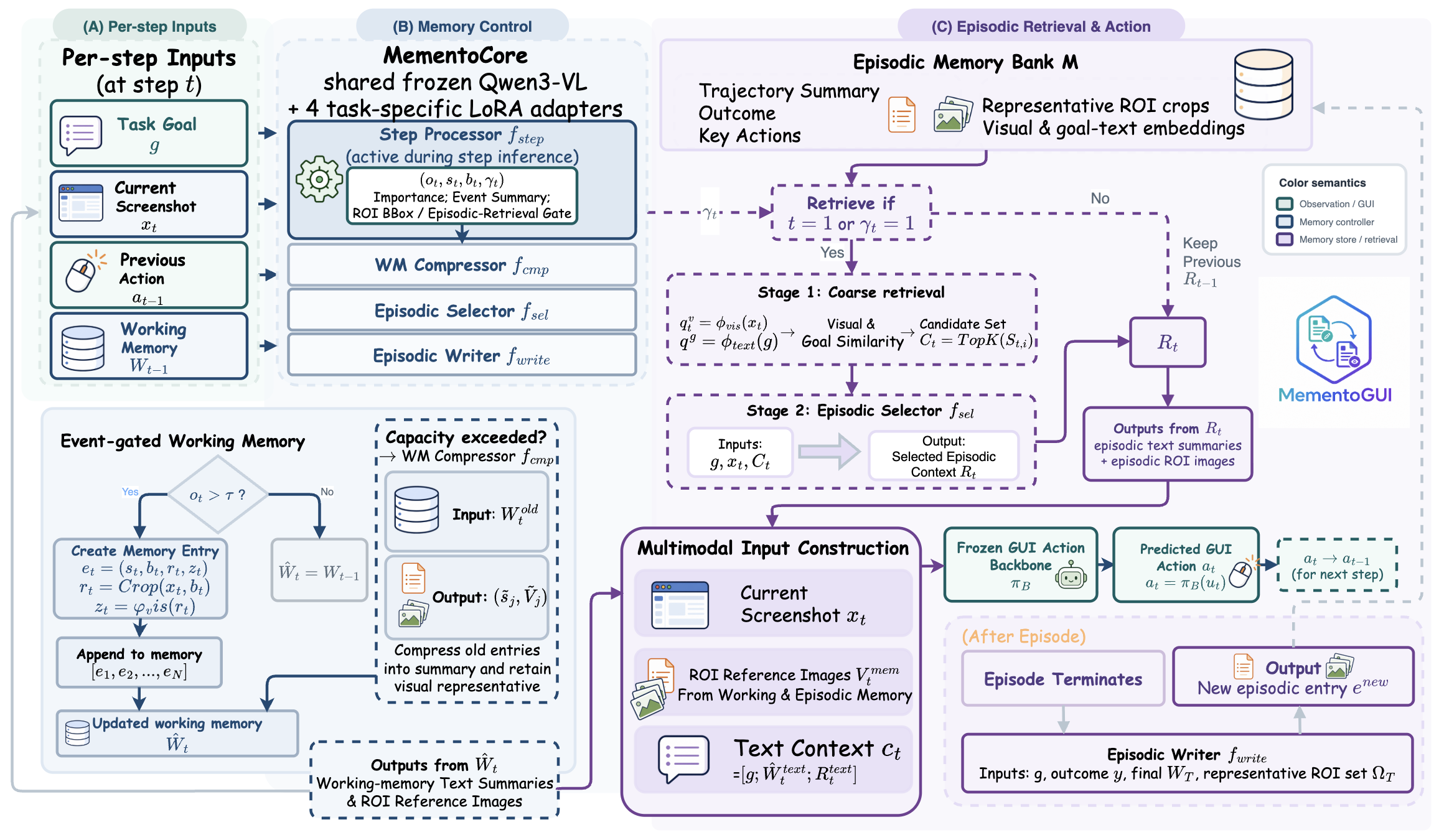
论文的系统图说明了它和普通 history replay 的根本差异:当前截图仍交给 frozen GUI action backbone 处理,但 MementoCore 会在每一步更新工作记忆、按需检索情景记忆,并把文本摘要与 ROI 图像一同序列化为动作模型的多模态上下文。对 APP 自动化测试来说,这对应的是“测试执行器不一定要重训,但必须有一层稳定的状态/证据管理中间件”。
2. Step Processor:决定当前屏幕是否值得写入记忆
每一步,Step Processor 输入任务目标、当前截图、上一动作和已有 working memory,输出:
o_t:写入显著性分数;s_t:事件摘要;b_t:任务相关 ROI box;γ_t:是否触发 episodic retrieval。
这一步非常关键。普通 history replay 默认“所有历史都重要”;MementoGUI 则让模型学习判断:哪些界面变化会影响未来决策。
对于 GUI 自动化,这比简单日志更接近人类操作习惯。一个熟练用户不会记住每一次滚动,但会记住“刚才选的是 Production 环境”“这个弹窗里警告了权限不可逆”“这个 issue 已经被分配给 Alice”。
3. Event-gated working memory:保存文本摘要 + ROI 视觉证据
当写入分数超过阈值,系统把一个 memory item 写入 working memory:
- 事件文本摘要;
- ROI box;
- ROI crop;
- 用于组织和检索的视觉 embedding。
论文中特别强调:动作 backbone 不接收自定义 embedding token,而是接收普通 ROI 图像。这点很重要,因为 GUI 决策中很多信息是局部视觉证据,例如:
- 选中的 tab 是蓝色还是灰色;
- 某个 checkbox 是否勾选;
- 列表中的目标行是否被高亮;
- 弹窗里具体的 warning 文案;
- 表单字段旁边的错误提示。
text-only memory 可以总结“用户选择了选项 A”,但当未来页面出现多个类似选项时,ROI crop 能提供更稳的视觉锚点。
4. WM Compressor:记忆不是无限增长,而要压缩旧状态
长程 GUI 任务如果持续几十到上百步,即使只写入显著事件,working memory 也会膨胀。MementoGUI 用 WM Compressor 把旧 memory entries 合并为更紧凑的摘要,同时保留代表性的视觉引用。
这对应真实工程中的一个核心问题:GUI Agent 的上下文预算应该被状态压缩机制管理,而不是靠固定截断。
固定截断会丢掉任务开头的关键约束;全量保留会让模型淹没在无关细节中。可学习压缩的价值在于,它可以把“操作流水账”变成“仍影响未来动作的状态摘要”。
5. On-demand episodic memory:从过去 episode 中检索可复用经验
除了当前任务内的 working memory,MementoGUI 还维护跨 episode 的 episodic memory。每个 episode 结束后,Episodic Writer 把轨迹写成可复用条目,包括:
- trajectory summary;
- outcome metadata;
- key actions;
- representative ROI crops;
- retrieval embeddings。
检索时先做向量召回,再由 Episodic Selector 做多模态相关性过滤。论文的 ablation 显示,随机 episodic context 会伤害性能,单阶段 embedding retrieval 也不如两阶段 learned relevance selection。这说明在 GUI 任务里,“相似经验”不是简单语义相似:两个页面长得像、任务描述像,不代表可复用动作完全一致。
这点对桌面自动化尤其重要。比如两个 Xcode 项目、两个 GitHub PR、两个 Jira issue 页面可能结构相同,但权限、分支、状态、目标文件不同。盲目复用过去轨迹会带来严重误操作。
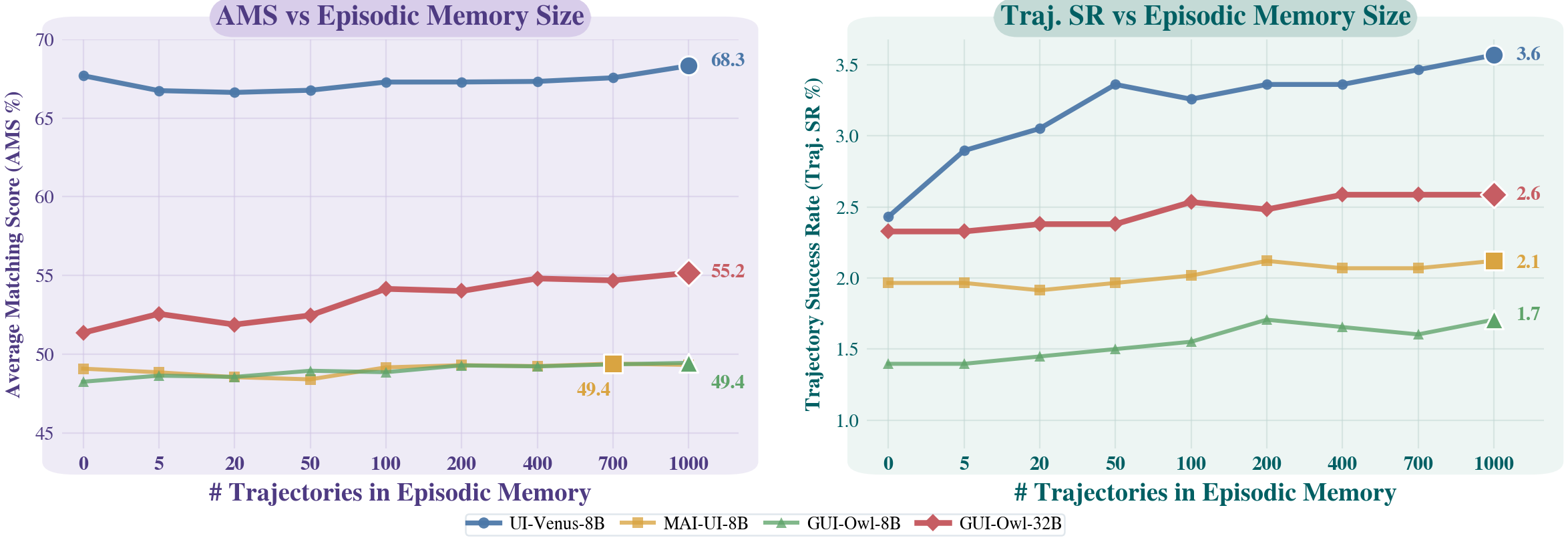
这张消融图对工程落地尤其重要:episodic memory bank 不是“越大越强”的无限外挂。记忆库变大后,检索噪声、过期经验、跨任务错配都会上升,因此必须把检索、过滤、过期和权限隔离作为一等设计对象,而不是把长期记忆当成普通向量库。
实验结果与可信度评估
论文在 GUI-Odyssey、MM-Mind2Web 和 MementoGUI-Bench 上评估。核心结果包括:
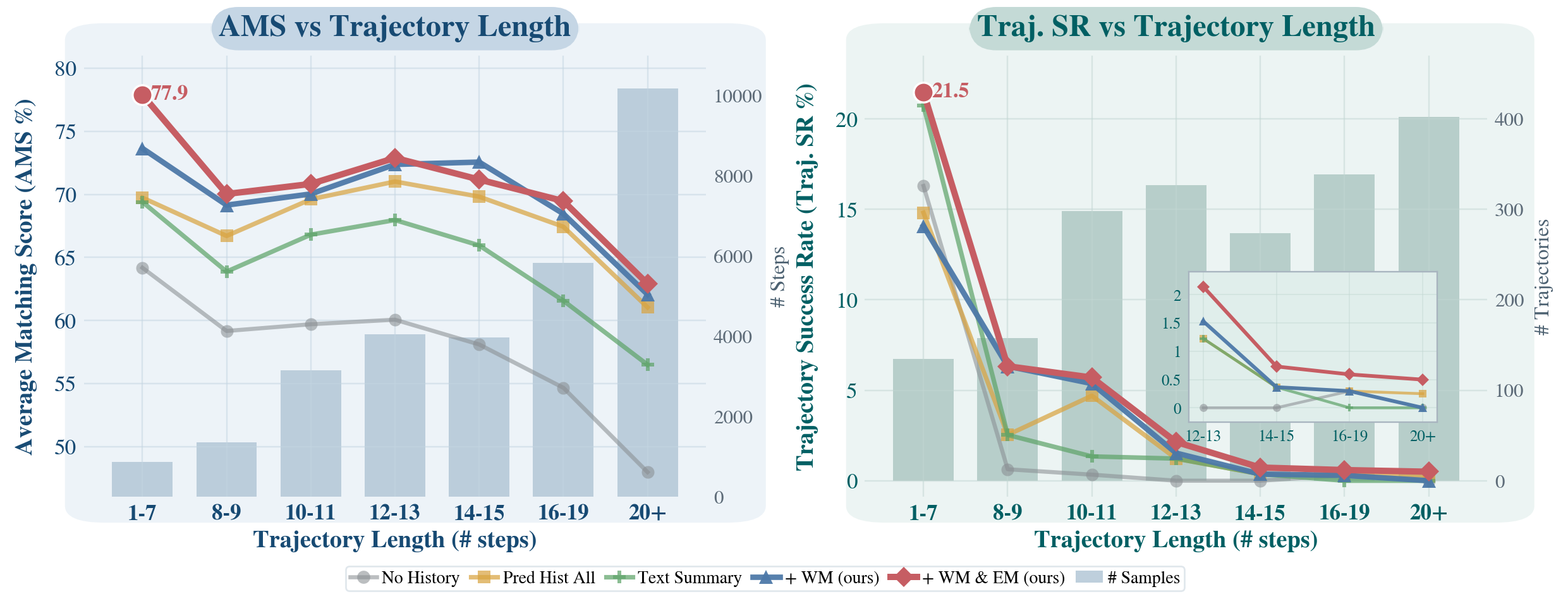
主结果表最重要的信息不是“某个单点数字最好”,而是三类对照同时成立:no history 明显不足,predicted history all / text summary memory 并非越多越好,多模态 working memory + episodic memory 才在多个 frozen backbone 上稳定提升。这支持了论文的核心论点:长程 GUI Agent 的上下文问题不能只靠堆历史 token 解决。
论文在 GUI-Odyssey、MM-Mind2Web 和 MementoGUI-Bench 上评估。核心结果包括:
- 在 GUI-Odyssey 上,UI-Venus-1.5-8B 无历史 baseline 为 54.58 AMS / 1.29 Traj. SR;加入 working memory 后为 67.69 / 2.69;加入 working + episodic memory 后为 68.32 / 3.57。
- 在同一 backbone 上,Predicted History All 为 66.31 / 2.33,Text Summary Memory 为 62.18 / 2.12,说明“全历史”和“纯文本摘要”都不如多模态受控记忆。
- 对 MAI-UI-8B、GUI-Owl-1.5-8B、GUI-Owl-1.5-32B 也有类似趋势,说明方法不是只对单一 backbone 有效。
- 在 MM-Mind2Web 上,MementoGUI 也提升 step success,但幅度和意义要结合 web benchmark 的离线动作匹配特性谨慎看待。
- 在 MementoGUI-Bench 上,论文引入 VAM、TPS、MCS 三个 VLM-based 指标,分别评估语义动作匹配、任务进展和记忆一致性。
可信的部分
最可信的贡献在 ablation:
- 去掉 ROI visual memory 会下降:说明收益不只是更好的文字摘要。
- 随机 episodic context 会下降:说明检索记忆有噪声风险,不是“上下文越多越好”。
- 两阶段 retrieval 优于单阶段 retrieval:说明 GUI 经验复用需要 learned filtering。
- 多个 backbone 都有提升:支持 plug-in memory layer 的泛化主张。
这些实验共同支撑一个判断:多模态记忆控制确实比 raw history replay 更适合长程 GUI Agent。
需要警惕的部分
但论文的结论也有几处容易被高估。
第一,trajectory success 仍然低。GUI-Odyssey 上从 1.29 提升到 3.57 是相对提升很大,但绝对成功率仍不足以说明系统能可靠完成长程任务。对生产级 CUA 来说,这种成功率只能证明研究方向有效,不能证明可部署。
第二,MementoGUI-Bench 的 VLM judge 指标有偏差风险。VAM、TPS、MCS 用 Gemini-3.1-Pro 作为 judge 能缓解 reference-based evaluation 太死板的问题,但也引入另一个问题:judge 可能偏好更“像解释”的输出,或对某些 GUI 语义判断过宽。尤其 MCS 这类记忆一致性指标,容易和生成式评审模型的表面一致性混在一起。
第三,offline benchmark 不能完全代表真实环境闭环。GUI-Odyssey、MM-Mind2Web 这类离线动作预测或轨迹匹配任务,和真实 OSWorld / AndroidWorld / SaaS-Bench 的在线环境执行不同。真实执行中会遇到 UI 漂移、点击副作用、加载延迟、权限弹窗、焦点错误、网络异常和不可逆操作。
第四,数据 curation pipeline 可能携带隐性 oracle。论文用 PSAI computer-use 轨迹自动构造 frame-level、subgoal-level annotation,并生成 memory control supervision。这很有规模化价值,但也要审视:如果标注过程利用了完整未来轨迹、强 VLM 后验判断或高质量元数据,那么训练出的 memory controller 在真实在线执行时可能比 benchmark 中更难获得同等质量的写入信号。
第五,任务分布仍偏 mobile / web,桌面 OS 迁移未充分证明。论文提到跨 mobile 和 web environments 的结果,但 macOS / Windows 原生桌面软件有更多非 DOM 控件、窗口管理、系统权限、菜单栏、快捷键、文件系统副作用和后台进程状态。MementoGUI 的思想可迁移,但结果不能直接外推到 macOS 自动化。
第六,记忆本身会成为攻击面。如果 episodic memory 保存了屏幕 ROI、用户输入、文件名、token、客户数据或内部系统页面,那么长期记忆就会变成隐私与安全风险。论文没有把这作为核心议题,但 computer-use agent 工程部署必须处理。
专家点评:真正贡献、被高估部分、工程落地建议
这篇论文真正推进了什么?
MementoGUI 真正推进了三点:
- 把长程 GUI Agent 的记忆管理显式模块化:step processing、working memory compression、episodic writing、episodic selection 分工清晰,比“把历史塞进 prompt”更系统。
- 把视觉证据纳入记忆,而不只是文本摘要:ROI-level visual memory 是 GUI 场景区别于普通 LLM agent memory 的关键。
- 证明 memory controller 可以作为 frozen action model 的 plug-in 层:这对工程集成非常重要,因为企业或个人工具往往无法重新训练底层 VLM / GUI action model。
它在 GUI grounding、Web/Mobile/Desktop agent 方向中的位置
如果把 GUIAgent 技术栈分层:
- GUI grounding 层:SeeClick、UGround、ScreenSpot、DRS-GUI 等解决“看见并定位控件”。
- Action model 层:CogAgent、ShowUI、UI-Venus、GUI-Owl、MAI-UI 等解决“根据屏幕和目标输出动作”。
- Environment benchmark 层:WebArena、VisualWebArena、AndroidWorld、OSWorld、WindowsWorld、SaaS-Bench 等解决“能否在真实任务中闭环”。
- Long-horizon cognition 层:记忆、计划、反思、过程监督、自验证、技能库等解决“能否跨很多步稳定执行”。
MementoGUI 位于第四层,并且和第一、第二层互补。它不试图替代 grounding 模型,也不主要提出新的动作空间,而是让已有 GUI backbone 在长程任务中获得更好的状态输入。
和 OSWorld / AndroidWorld / VisualWebArena 相比,MementoGUI 不是一个更真实的在线环境 benchmark;它更像是为这些 benchmark 暴露出的长程失败提供一个 memory control 解决方案。和 SaaS-Bench 这类强调真实业务状态验证的 benchmark 相比,MementoGUI 的任务闭环真实性较弱,但方法层面的启发更直接。
哪些实验或结论可能被高估?
我会重点警惕四类高估:
- benchmark overfitting:如果 memory controller 的训练轨迹和评测任务分布高度接近,提升可能部分来自对任务格式的适配。
- 隐藏 oracle:自动标注和 VLM filtering 是否利用了离线完整轨迹信息,需要在真实在线执行中重新验证。
- 任务分布过窄:mobile / web 任务不能覆盖桌面 IDE、终端、文件系统、多窗口、多显示器、系统设置等复杂场景。
- 复现不足:项目页提供资源入口,但若完整数据、训练脚本、评测环境和 judge prompt 不充分开放,独立复现实验会很难。
另外,VLM-based metrics 虽然比硬 reference 更灵活,但如果没有人工审计、跨 judge 对照和在线环境验证,很容易让系统在“看起来更合理”的指标上提升,而不一定在真实任务成功率上同等提升。
对 APP 自动化测试 / 移动端 QA / GUI 自动化的启发
面向 APP 自动化测试、移动端 QA 或跨端 GUI 自动化,MementoGUI 值得吸收的是以下设计,而不是照搬整套系统。
应该采用什么
- 事件门控的工作记忆
APP 自动化测试不应该记录所有截图和动作,而应该只记录会影响后续决策与断言的事件,例如:
- 当前 App、账号状态、测试数据 ID、业务对象 ID;
- 当前页面路径、选中的 tab、筛选条件、排序状态、表单草稿;
- 弹窗、toast、权限请求、验证码/风控提示、不可逆操作确认;
- 上一步 action 后的 UI diff、接口/日志中的关键错误;
- 已完成的测试步骤、待验证断言、失败截图与复现路径。
- 文本状态 + 局部视觉证据双轨记忆
对于移动端 App,很多 UI 不是标准 Web DOM,Hybrid/H5/Native 页面还会混合出现。仅靠 OCR、accessibility tree 或控件 ID 可能不够,应该保存小区域截图作为视觉锚点,例如按钮状态、列表目标行、tab 选中态、toast、权限弹窗、表单错误提示。
- 记忆压缩而不是上下文截断
端到端 App 测试任务常常很长:登录、构造数据、跨页面操作、提交表单、等待异步状态、校验结果、清理数据。测试 Agent 应该持续维护结构化状态:
任务目标:完成退款流程回归测试
当前阶段:已创建订单,正在进入售后页
关键约束:只使用测试账号;不得操作真实支付
已完成:登录、下单、支付 mock、进入订单详情
待验证:退款按钮、退款状态、通知消息、后端状态
风险:列表页缓存导致状态未刷新,toast 消失过快这种状态比原始聊天记录更适合 GUI / CLI 混合自动化。
- 跨任务 episodic memory 要做强过滤
过去经验确实有用,例如“这个项目的构建命令是什么”“Xcode scheme 怎么选”“公司内部工具登录后入口在哪”。但必须做强过滤,避免把另一个项目、另一个账号、另一个环境的经验错误套用。
- 把记忆和权限边界绑定
移动端 QA 工具应该按 App、环境、账号、设备、测试数据隔离 memory。涉及密码、token、手机号、订单号、客户数据、内部页面的 ROI crop 必须默认不入长期记忆,或者进入加密、可审计、可删除的本地 vault。
应该警惕什么
- 不要让 memory 成为 prompt injection 的长期载体:网页、邮件、README、issue 评论里的恶意指令如果被写入 episodic memory,后续任务会被污染。
- 不要把 GUI 操作记忆当成事实来源:UI 可能漂移,按钮位置、菜单结构、项目配置会变。记忆只能作为建议,不能替代实时观测。
- 不要过度依赖 VLM judge:APP 自动化测试最终要看 UI 状态、后端状态、日志、网络请求、数据库或业务 verifier,而不是模型评价“任务似乎完成”。
- 不要忽略延迟:MementoGUI 这类 controller 会增加推理时间。移动端测试 Agent 如果每一步都额外跑大 VLM,执行成本和稳定性都会受到影响。
我会优先复现什么
如果要把这篇论文的思想落到 APP 自动化测试 / 移动端 QA,我建议优先做三个小型复现:
-
长程 App 回归用例的 working memory ablation
比较 no history、raw history、text summary、text + ROI memory 对跨页面下单、售后、审批、资料修改等任务的影响。 -
事件写入判别器
不必一开始训练大模型,可以先用规则 + 小模型判断哪些事件值得写入:页面跳转、toast 出现、权限弹窗、表单错误、列表项状态变化、接口错误、断言失败等。 -
安全过滤器
在写入 memory 前检测 secret、token、邮箱、私有路径、客户名、业务数据敏感性;默认只存摘要,不存完整截图。
这些复现比直接训练一个完整 MementoCore 更实际,也更符合个人或团队做 macOS 研发工具的迭代路径。
局限性与未来方向
MementoGUI 打开了一个重要方向,但未来还需要补齐几件事。
1. 从 offline action matching 走向 online task completion
真正的 GUI Agent 价值最终要在在线环境中验证,例如 OSWorld、AndroidWorld、SaaS-Bench 或 macOS 原生任务环境。动作匹配提升不等于真实任务完成提升,尤其是存在多路径、UI 延迟和副作用时。
2. 加入状态 verifier,而不仅是 VLM judge
长程任务需要外部 verifier:文件是否生成、设置是否生效、测试是否通过、数据库是否更新、邮件是否发送、PR 是否创建。MementoGUI 的 memory consistency 指标有启发,但不能替代环境状态验证。
3. 记忆污染与安全隔离需要系统化
长期 episodic memory 很容易被错误经验、恶意页面、过期 UI 和敏感数据污染。未来的 GUI memory system 应该支持:
- memory provenance;
- TTL / 过期机制;
- app / workspace / identity 隔离;
- 人工审计和删除;
- secret redaction;
- 对抗 prompt injection 的写入策略。
4. 和过程奖励 / RL 结合
MementoGUI 目前更偏 SFT + DPO 的 memory controller。未来可以把 memory write / retrieve 当成 agent action 的一部分,用过程奖励优化:写入是否帮助后续成功、检索是否减少错误、压缩是否保留必要状态。
5. 桌面 OS 原生场景仍需专门适配
Android / iOS 的 GUI 自动化不仅是截图动作问题,还涉及 accessibility tree、WebView DOM、系统权限、通知、软键盘、设备状态、网络环境、测试数据与后端状态。MementoGUI 的 ROI memory 思路很有用,但需要和 Appium、Maestro、UIAutomator、XCUITest、接口日志、数据库校验和视觉回归工具结合。
参考链接
- 论文:https://arxiv.org/abs/2605.18652
- HTML 版本:https://arxiv.org/html/2605.18652v1
- 项目页:https://zzzmyyzeng.github.io/MementoGUI
- GUI-Odyssey:论文中用于长程 GUI 评估的主要 benchmark 之一
- MM-Mind2Web / Mind2Web:Web agent 离线动作预测评估方向
- OSWorld、AndroidWorld、VisualWebArena、SaaS-Bench:可用于理解长程 GUI / computer-use agent 在线评测位置的相关方向
总结
MementoGUI 对 GUIAgent 领域的核心提醒是:更强的视觉定位和更长的上下文窗口,并不会自动解决长程 GUI 自动化。Agent 必须学会管理自己的多模态记忆。
它把工作记忆、情景记忆、ROI 视觉证据和 learned memory control 组合成一个可插拔层,证明了 frozen GUI backbone 也能通过更好的记忆输入获得明显提升。与此同时,低绝对轨迹成功率、offline evaluation、VLM judge、潜在 hidden oracle 和桌面迁移不足,都说明这还不是终局方案。
对 APP 自动化测试 / 移动端 QA 而言,最值得带走的不是具体模型,而是一套工程原则:只记关键事件,保留必要视觉证据,持续压缩任务状态,强过滤跨任务经验,用真实环境 verifier 判断完成,并把隐私与安全作为 memory layer 的一等公民。