SaaS-Bench:GUI Agent 从“会点网页”到“能完成真实 SaaS 工作流”还差多远?
从 GUIAgent / computer-use agent 专家视角解析 SaaS-Bench:23 个真实可部署 SaaS、106 个专业工作流、长程多应用任务和可验证 checkpoint 如何暴露当前 CUA 在规划、状态追踪、自验证与工程落地上的短板。
论文:SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?
arXiv:2605.15777v2,2026-05-24 更新,2026-05-15 首次提交
代码:UniPat-AI/SaaS-Bench
一句话结论:SaaS-Bench 的价值不在于又给 GUI Agent 做了一个排行榜,而是把评测从“页面导航能力”推到“真实业务状态是否被正确改变”——在这个尺度上,当前最强模型 checkpoint 只有 43.9%,端到端 resolved 低于 4%。
如果只看过去两年 GUI Agent 的 benchmark 数字,很容易产生一种错觉:模型已经能操作浏览器、手机和桌面,剩下只是把 grounding 做得更准、把动作空间封装得更好。但 SaaS-Bench 给出的结论非常冷:not yet。
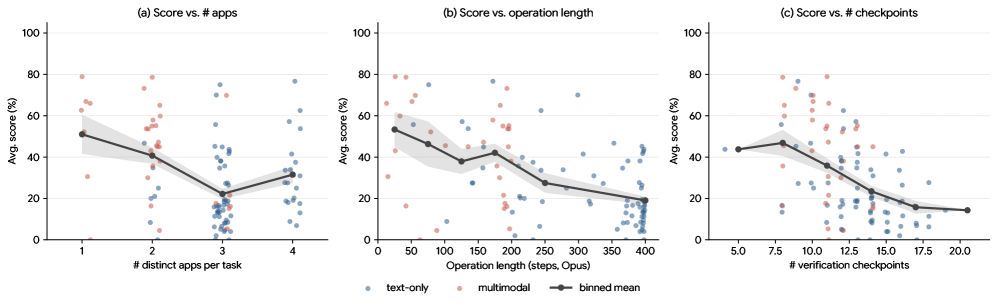
这篇论文构建了 23 个可本地部署的开源 SaaS 系统,覆盖 6 个专业领域、106 个真实工作流任务;99/106 个任务涉及至少两个应用,许多任务超过 100 个交互步骤。作者测试了多种前沿 CUA(Computer-Using Agent),最强的 Claude Opus 4.7 也只有 43.9% checkpoint score 和 3.8% resolved score。这意味着模型能完成不少中间步骤,但几乎不能稳定把整条业务链闭环。
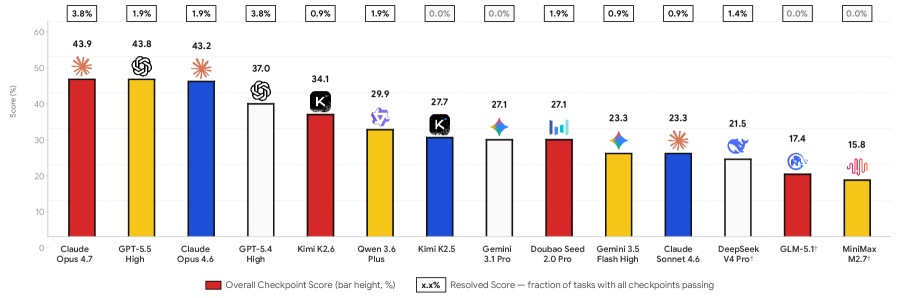
这张排行榜是整篇论文最有冲击力的图:强模型在 checkpoint score 上能做到 40% 左右,但 resolved score 低于 4%。它说明当前 CUA 不是“完全不会做”,而是经常能推进局部步骤,却无法稳定完成整条业务链。对 APP 自动化测试也是同一个教训:步骤命中率、点击准确率、页面覆盖率都不能替代端到端业务断言。
站在 GUIAgent 领域专家视角,SaaS-Bench 真正推进的是:它把 GUI Agent 的评价对象从“能否找到并点击正确控件”升级为“能否在真实软件系统里维护业务语义、跨应用状态和最终可验证结果”。 这比 ScreenSpot、VisualWebArena、OSWorld 一类 benchmark 更接近企业级 computer-use agent 的部署现实。
为什么这篇论文值得 GUIAgent 领域关注
GUI Agent 领域现在大致有几条主线:
- GUI grounding:把自然语言指令或元素描述定位到屏幕坐标,例如 SeeClick、UGround、ScreenSpot 系列。
- Web / Mobile / Desktop agent:在浏览器、Android、桌面 OS 中执行动作,例如 WebArena、VisualWebArena、AndroidWorld、OSWorld、WindowsWorld。
- 长程任务与过程监督:让 agent 不只会一步点击,而是能记忆、规划、纠错、完成多阶段目标。
- RL / environment feedback:利用真实环境奖励、过程 verifier、trajectory synthesis 提升执行能力。
- 安全、隐私与工程部署:控制真实软件时如何处理凭据、状态污染、数据泄露和不可逆操作。
SaaS-Bench 直接命中第 2、3、4、5 点。它不太关心单步 grounding 准确率,而是追问一个更工程化的问题:如果把 agent 放进 HR、CRM、会计、项目管理、医疗系统、文档协作、媒体管理这些 SaaS,它能否像一个初级运营人员一样把任务做完?
论文的核心设定是:
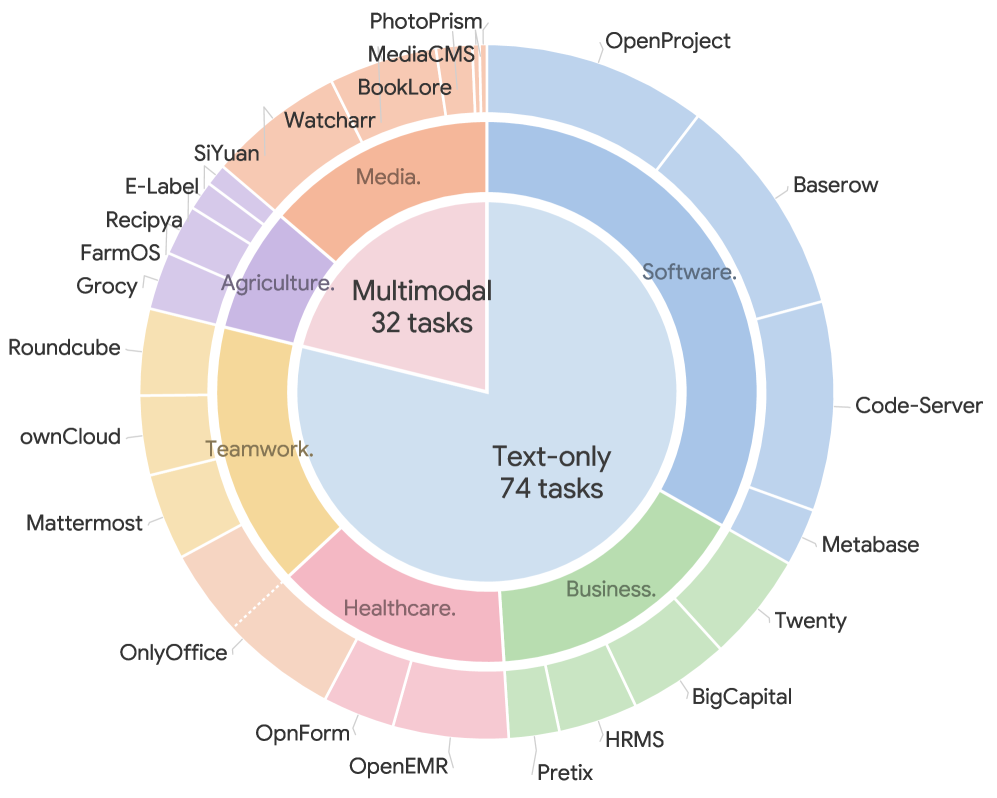
- 23 个真实开源 SaaS 系统,而不是 mock 网站;
- 6 个专业领域:软件工程与项目管理、商业运营与财务、医疗行政、团队协作与文档流、农业食品供应链、独立媒体创作;
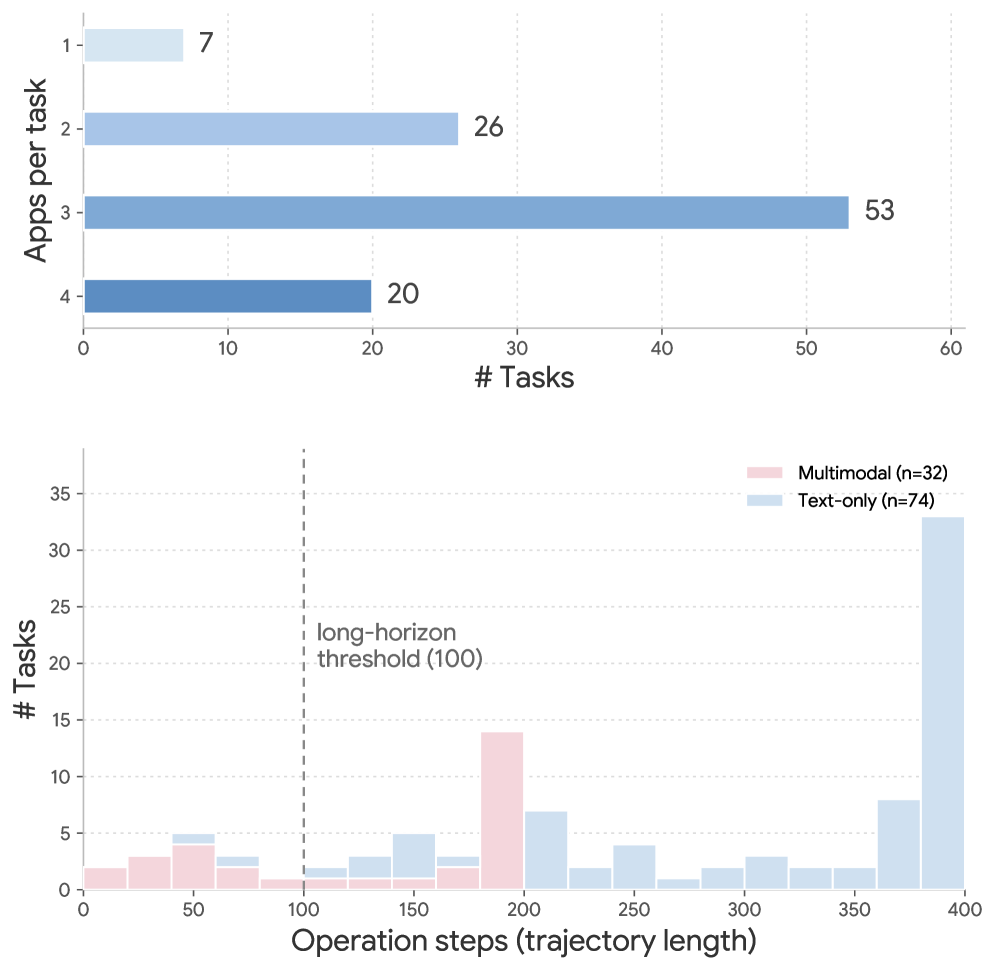
- 106 个任务,其中 74 个 text-only、32 个 multimodal;
- 93.4% 的任务需要跨 2 个以上应用,三应用任务最多;
- text-only 任务中 72/74 超过 100 步;
- 每个任务用最终应用状态的 verifier 检查,而不是只看 agent 自己说“done”。
这张图体现了 SaaS-Bench 相比传统 Web benchmark 的关键差异:它不是围绕单页面导航采样任务,而是围绕真实专业角色和跨系统业务流程组织任务。GUI Agent 在这里面对的是持久化业务对象、权限、表单校验、异步状态和跨应用实体一致性。
这套设定的领域意义在于,它把 CUA 从“浏览网页”推进到“操作数据库背后的业务系统”。真实 SaaS 有身份认证、后端状态、表单校验、异步刷新、业务实体关系、跨系统 ID 映射、文档和邮件等副作用。对于 GUI Agent 来说,这些才是部署时真正会把成功率打穿的东西。
背景与问题定义
已有 benchmark 各自解决了 GUI Agent 的一部分问题:
- Mind2Web / WebArena 更偏 web navigation 和网页任务;
- VisualWebArena 增加视觉线索,强调视觉-网页交互;
- AndroidWorld 关注移动端真实 App 任务和 adb 可验证状态;
- OSWorld 把任务扩展到真实桌面系统,强调开放式 OS 操作;
- WindowsWorld / macOS 相关 benchmark 进一步把任务推向专业桌面软件和跨应用流程。
SaaS-Bench 的位置比较特殊:它不是纯桌面 benchmark,也不是单网站 benchmark,而是基于浏览器入口的真实 SaaS 工作流 benchmark。换句话说,它的界面载体是 web,但任务语义是企业软件流程。
这点很重要。很多 Web Agent benchmark 测的是“找到网页上的信息”“提交一个表单”“完成一次购物 / 订票模拟”。SaaS-Bench 则要求 agent 修改持久化系统状态。例如:
- 在 HRMS 中审批报销;
- 到会计系统创建 vendor、bill、payment;
- 再到 CRM 里记录完成任务;
- 最后 verifier 检查数据库、页面状态、文件或字符串结果是否满足要求。
这里的难点不是某个按钮太小,而是业务状态必须在多个系统间一致。一个日期错一天、一个客户类型建错、一个状态没有从 draft 变成 approved,都会导致端到端失败。
核心方法拆解
1. 用真实可部署 SaaS,而不是 toy environment
SaaS-Bench 选择了 OpenProject、Baserow、Code-Server、Metabase、Twenty、BigCapital、HRMS、Pretix、PhotoPrism、MediaCMS、BookLore、Watcharr、SiYuan、E-Label、Recipya、FarmOS、Grocy、Roundcube、ownCloud、Mattermost、OnlyOffice、OpnForm、OpenEMR 等系统。
这些系统的共同点是:
- 有真实前后端逻辑;
- 有数据库持久化状态;
- 可以 Docker 化部署和 reset;
- 任务完成与否能通过 verifier 检查。
这比只给一个静态网页或轻量 mock server 更接近生产环境。GUI Agent 在这些系统中不能依赖“页面看起来像完成了”,因为最终判定来自应用状态。
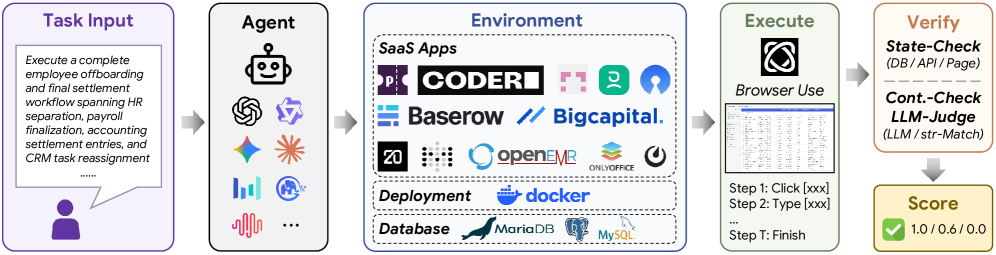
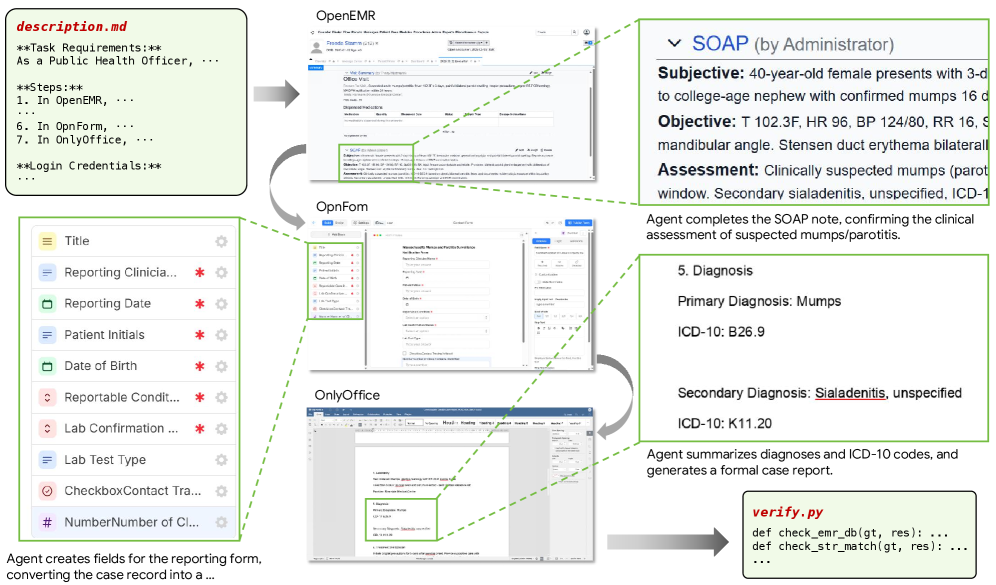
评测闭环图强调了一个非常工程化的设计:agent 只能通过浏览器入口操作软件,不能直接拿 verifier、数据库 schema 或 reference solution;但评估时又不相信 agent 的自述,而是用外部验证工具检查最终状态。这种“UI 执行 + 状态验证”的组合,比只看轨迹是否像人类操作更适合衡量真实可用性。
2. 任务是跨应用专业工作流
SaaS-Bench 的任务不是随机采样 UI 功能,而是从角色和工作流出发:财务、医疗行政、项目管理、团队协作、媒体管理等。论文中一个典型案例是员工报销流程:
- 在 HRMS 中核查并审批 expense claim;
- 在 BigCapital 中创建 vendor、items、bill 和 payment;
- 确认 A/P aging summary 中余额归零;
- 在 Twenty CRM 中创建并完成一条记录。
这两张图说明 SaaS-Bench 的难点不是“网页按钮难点”,而是任务结构天然嵌套、多应用依赖重、步骤链条长。对移动端 QA 来说,类似场景就是跨 App / H5 / 小程序 / 后台系统的业务闭环测试:一个前置实体没建对,后续所有断言都会级联失败。
这类任务同时考察:
- 指令理解;
- 多系统导航;
- 屏幕理解和表单填写;
- 业务实体映射;
- 长程记忆;
- 自我校验;
- 错误恢复。
3. 用 checkpoint score 和 resolved score 双指标
论文使用两个指标:
- Resolved Score:只有任务所有 checkpoint 都通过才记 1,否则 0;
- Checkpoint Score:按权重统计通过的 checkpoint,用于衡量长程任务中的部分进展。
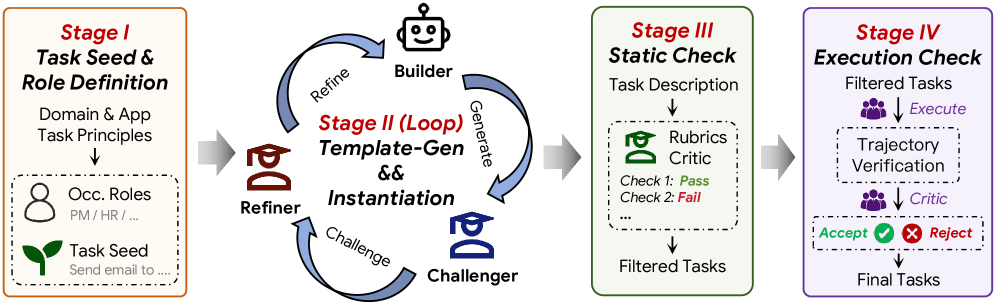
任务合成图值得注意:论文不是简单手写 106 条任务,而是从领域 seed 和职业角色出发,经由 Builder–Challenger–Refiner 循环生成候选任务,再做静态规则过滤和执行检查。它给测试生成一个很直接的启发:高质量 GUI 测试任务不是只靠随机探索,而要从业务角色、实体关系和可验证 checkpoint 反向生成。
这个设计是合理的。长程 GUI 任务如果只看最终成败,会丢失“失败在哪里”的信息;但如果只看 checkpoint,又会高估工程可用性。SaaS-Bench 同时报告二者,恰好揭示了当前 agent 的核心问题:中间进展不少,端到端闭环极差。
4. 评测不暴露 verifier、数据库 schema 或 reference solution
论文说明 agent 只拿到任务描述、应用入口 URL、登录凭据和一般规则;不会拿到参考解法、verifier、数据库 schema 或后端 API。多模态任务提供图片、PDF 等路径,但不提供预解析注释。
这降低了 hidden oracle 的风险,也更接近真实部署:agent 必须通过 UI 观察和操作,而不是直接查询数据库作弊。
实验结果与可信度评估
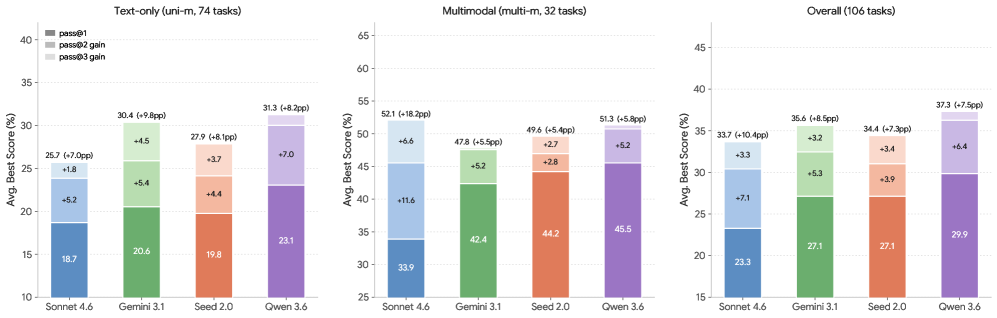
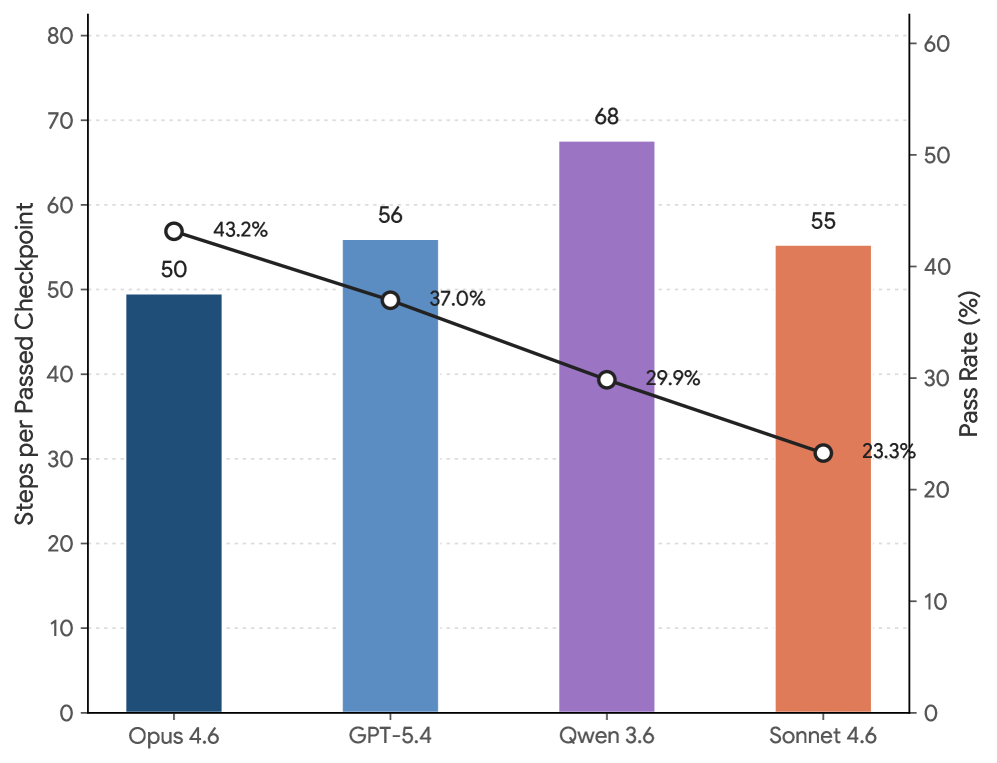
Pass@k 图说明同一个任务多跑几次确实可能提高最好结果,但这不是生产可用性的充分条件。真实企业流程和 APP 自动化回归通常不能靠“多试几次碰碰运气”,因为每一次失败都可能污染状态、重复创建数据或触发不可逆动作。
最关键结果是:当前强模型在 SaaS-Bench 上仍然远不能用。
论文报告:
- Claude Opus 4.7:43.9% overall checkpoint score,3.8% resolved score;
- GPT-5.5 High:43.8% checkpoint,1.9% resolved;
- top models 大多聚集在 43–44% checkpoint;
- 其他模型多数低于 40%;
- 最强模型端到端完成率也低于 4%。
从专家角度看,最有价值的不是排行榜,而是论文对失败模式的拆解。
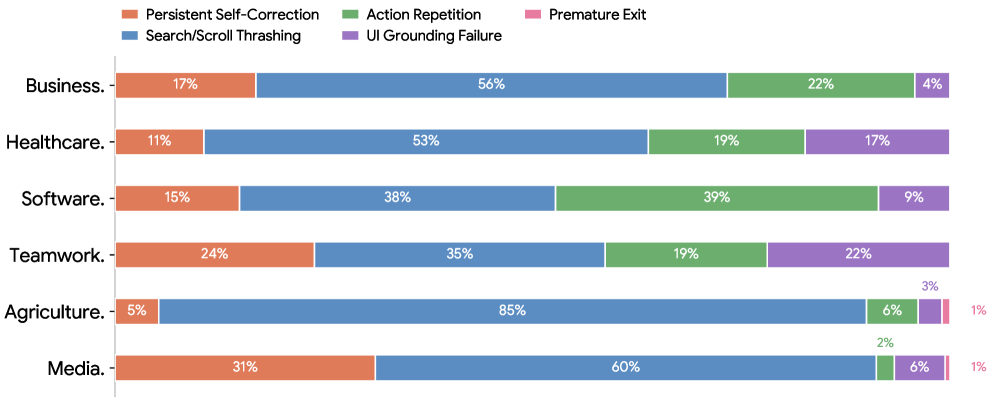
失败模式一:Entity Missing 多于 Value Mismatch
论文发现失败 checkpoint 中占主导的是 Entity Missing:预期的记录、文件、ticket 或 artifact 根本没有创建。相比之下,数值填错、状态不对等 value-level error 更少。
这说明主要瓶颈不是“已经走到正确步骤但填错一个字段”,而是 agent 经常没有抵达或没有真正执行关键业务操作。换成 GUIAgent 术语:这不是单步 grounding 小误差,而是任务级 planning / navigation / state tracking 失败。
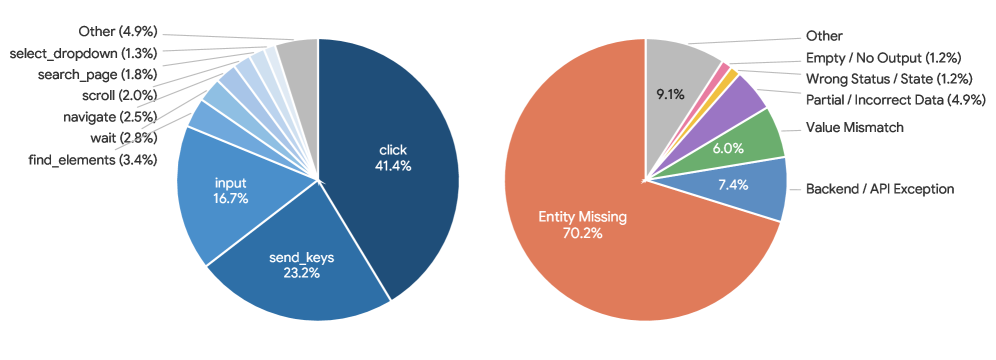
这张失败分析图对测试工程很关键:多数失败不是“字段值差一点”,而是目标实体根本没创建、文件没生成、ticket 没出现。换到 APP 自动化测试中,这意味着不能只检查最后页面有没有某段文案,还要验证订单、审批单、消息、库存、账务等业务实体是否真实存在且状态正确。
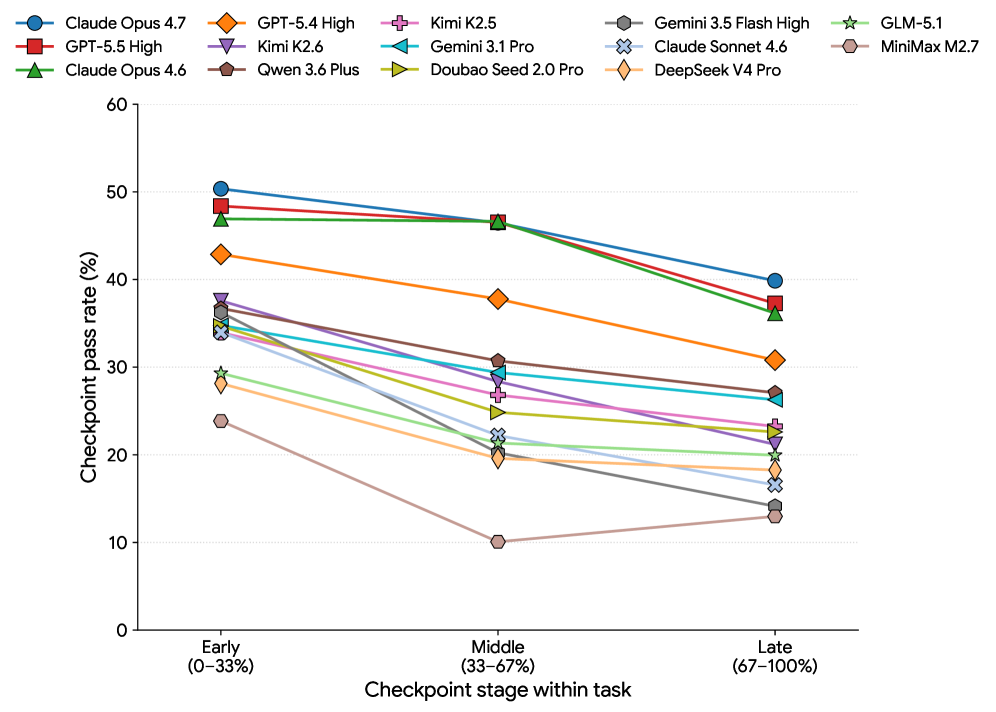
失败模式二:长程 checkpoint 衰减
论文按任务阶段分析 checkpoint,通过率从早期到中后期单调下降。强模型每个阶段绝对分更高,但相对衰减类似。
这说明长程失败不是某个模型的偶然 bug,而是当前 CUA 架构的结构性问题:
- 早期上下文没有可靠压缩进可执行记忆;
- 中间结果没有被稳定验证和持久记录;
- 后续步骤依赖前面实体时容易语义漂移;
- agent 终止时常把“计划中应该完成”误当成“观察到已经完成”。
失败模式三:单点小错会级联成整条业务失败
论文讨论了一个 BigCapital 中 customer entity type 建错的案例。任务需要创建公司客户 Arcturus Digital,但 agent 因为同时填写了联系人名和公司名,实际创建成个人客户 Elena Vasquez,公司名只是附属字段。界面上显示类似 “Elena Vasquez (Arcturus Digital)”,agent 误以为正确,继续创建发票、付款和 journal entry。最终 verifier 按公司客户查询时找不到实体,导致一串下游 checkpoint 失败。
这个案例非常典型:真实软件中的 UI 字段不是纯文本槽位,而是背后有数据模型。GUI Agent 如果没有显式理解“任务实体—应用实体—数据库关系”的映射,就会被表面 label 迷惑。
失败模式四:agent 不知道自己失败了
报销案例中,agent 曾经观察到 bill date 是 2026-03-19,而任务要求是 2026-03-20;它计划修复,但后续没有重新验证修复是否生效,最后却在 done summary 中声称 bill 日期正确。
这暴露了一个部署级危险:当前 agent 的自评估 trace 并不可信。它会把 intention 写进 summary,而不是把 observed state 写进 summary。
对于 macOS 或企业桌面自动化,这一点尤其关键。如果 agent 修改 Xcode 配置、提交 PR、操作财务后台、删除文件或发邮件,不能依赖模型自称“我已经完成”。必须有外部 verifier 或至少闭环观察。
失败模式五:pass@1 不稳定
论文指出,同一模型在同一任务多次运行会有很大方差。某些 run 接近成功,另一些 run 几乎失败。这来自长程路径依赖:早期一个导航选择、字段解释或失败重试策略,会改变之后几十到几百步。
因此 SaaS-Bench 对 GUIAgent 评测提出了一个重要提醒:只报 single-run pass@1 很容易误导。 对长程 GUI task,更应该报告 pass@k、score variance、关键分叉点、平均动作成本、恢复能力等指标。
这组图共同说明:长程 GUI Agent 的失败不是某个孤立按钮识别错误,而是复杂度、任务阶段、领域语义和动作成本叠加后的系统性衰减。越到后期,agent 越容易把“计划中要做的事”误认为“已经观察到完成的事实”。
专家点评:真正贡献、被高估部分、工程落地建议
这篇论文真正推进了什么?
SaaS-Bench 的真正贡献有三点:
第一,把 GUI Agent benchmark 的单位从“页面任务”提升到“业务工作流”。 这会逼迫模型处理跨应用实体、业务约束、持久化状态和最终 artifact,而不是只优化点击路径。
第二,把可验证性放在中心。 每个任务有 weighted checkpoint,verifier 检查最终应用状态。这比人工看轨迹、模型自报完成、或简单网页状态判断更可靠。
第三,揭示 checkpoint score 与 resolved score 的巨大鸿沟。 43.9% checkpoint 看起来还能接受,但 3.8% resolved 说明生产可用性几乎不存在。这个差距对行业非常重要,因为用户关心的是“报销真的处理完了吗”,不是“agent 完成了 16/20 个中间点”。
它和 OSWorld / AndroidWorld / VisualWebArena 的位置在哪里?
如果做一个坐标系:
- ScreenSpot / UGround 更偏 grounding 原子能力;
- VisualWebArena 更偏 视觉网页交互;
- AndroidWorld 更偏 移动端真实 App + 可验证任务;
- OSWorld 更偏 桌面 OS 开放任务;
- SaaS-Bench 更偏 浏览器承载的企业 SaaS 长程专业工作流。
SaaS-Bench 不替代 OSWorld,因为它主要通过浏览器操作 SaaS,不覆盖文件系统、IDE、终端、原生桌面 app、系统设置等广义 desktop affordance;它也不替代 AndroidWorld,因为没有移动端传感器、通知、系统权限和 App 生命周期问题。
但它补上了 OSWorld / WebArena 之间一个很关键的空白:真实企业软件里的多应用业务链路。对于 computer-use agent 商业化,这个空白非常重要。
哪些实验或结论可能被高估?
尽管 SaaS-Bench 很有价值,我会谨慎看待以下几点。
1. “真实 SaaS”不等于真实企业生产环境。 论文使用的是可部署开源 SaaS,这保证可复现,但企业内部真实系统往往有定制字段、权限策略、SSO、审计、网络限制、脏数据和历史包袱。SaaS-Bench 比 toy benchmark 真实很多,但仍是可控实验环境。
2. 任务分布可能仍然窄。 106 个任务覆盖 6 个领域已经不小,但 professional workflow 的空间极大。当前任务可能更偏表单、记录、文档和后台管理;对实时协作、复杂权限、异常工单、灰色业务规则、长时间等待、人机确认等覆盖有限。
3. UI 漂移和版本漂移风险。 开源 SaaS 一旦版本升级,UI、字段、默认配置、数据库 schema 都可能改变。论文通过 Docker 固定环境缓解复现问题,但这也意味着 benchmark 可能逐渐变成“固定版本游戏”。未来如果 leaderboard 被长期优化,仍可能出现 benchmark overfitting。
4. verifier 本身也是 oracle,但不是隐藏给 agent 的 oracle。 verifier 通过数据库 / 状态检查任务是否完成,这对评测合理;但 verifier 的设计决定了什么算完成。若 checkpoint 漏掉关键副作用,agent 可能通过 verifier 但不满足真实业务质量。若 checkpoint 过细或权重不合理,也可能放大某些小错。
5. 模型对比受执行框架影响。 Browser agent 的动作空间、max steps、prompt、浏览器自动化栈、等待策略、文件上传方式都会影响结果。论文尽力统一环境,但不同模型与 agent scaffold 的匹配程度仍可能影响排名。
工程落地建议
如果要把 SaaS-Bench 的结论转成 GUIAgent 系统设计,我会给四条建议:
- 不要把“动作成功”当“业务成功”。 点击、输入、提交都只是 action execution,必须重新观察或通过外部 API / DB / 文件系统验证 action effect。
- 显式建模业务实体。 任务中的“客户、供应商、报销单、发票、项目、患者、文件”应该有结构化 memory,而不是只存在自然语言 scratchpad 里。
- 引入 checkpoint-based recovery。 长程任务要能在中间保存状态、发现错误、回滚或重试,而不是一次性跑到 done。
- 评测必须多运行。 对生产 agent,单次成功率不够,应测方差、失败恢复、幂等性和副作用控制。
对 APP 自动化测试 / 移动端 QA / GUI 自动化的启发
面向 APP 自动化测试、移动端 QA 或跨端 GUI 自动化,SaaS-Bench 给出的启发比很多 web benchmark 更直接。
应该采用什么?
1. 采用“最终状态 verifier”思路。 例如让 agent 操作电商、金融、内容、IM、企业协同类 App,不能只看 agent 是否点了按钮,而要检查:
- 订单、支付、退款、审批、消息、文件等业务实体是否真实创建;
- 前端 UI 状态、后端接口/DB 状态、消息队列或日志是否一致;
- Appium / Maestro / UIAutomator / XCUITest 的断言是否通过;
- 关键截图、toast、push、弹窗是否在预期时间窗出现;
- 测试数据是否被正确清理,避免污染后续用例。
2. 采用 checkpoint 分解。 移动端端到端任务也可以拆成 checkpoint:登录、造数、进入目标页面、执行业务动作、等待异步状态、验证 UI 与后端、清理数据。每个 checkpoint 都要有可观察证据。
3. 采用跨应用实体记忆。 移动端质量保障工作流常跨 App、H5、后台管理系统、接口平台、日志平台、数据库和缺陷系统。agent 需要把“这个用户、订单、设备、环境、测试数据、缺陷单”作为结构化实体贯穿全程。
4. 采用闭环修复。 每次修改后必须重新读取结果。例如改了 Info.plist 后重新读取;点击 Xcode setting 后重新检查;执行 git commit 前检查 diff;发出邮件或消息前显示确认。
应该警惕什么?
1. 警惕模型自信 summary。 SaaS-Bench 的案例说明 agent 会把目标状态写成已完成状态。macOS 工具里不能让模型最后一句“已完成”作为可信证据。
2. 警惕 UI 表面语义。 移动端 App 里也有很多类似陷阱:按钮 label 和实际状态不一致、toast 太快消失、列表缓存未刷新、WebView 与 Native 状态不同步、弱网重试造成重复提交。必须观察真实状态。
3. 警惕长程任务预算耗尽。 复杂 App 回归很容易超过 100 步:登录、切换环境、造数、跨页面操作、等待异步任务、处理权限弹窗、做后端核验。需要分段执行和恢复,而不是单 trajectory 硬跑。
4. 警惕不可逆副作用。 SaaS-Bench 是评测环境,可以 reset;真实 macOS 上删除文件、推送代码、改系统设置、发送消息都需要权限边界、dry-run 和确认机制。
值得复现什么?
如果要做一个 APP 自动化测试 / 移动端 QA benchmark,我会复现 SaaS-Bench 的三件事:
- 可部署 / 可重置环境:用固定 App 版本、固定设备状态、固定测试账号、固定后端数据;
- weighted verifier:用 UI 截图、accessibility tree、接口、数据库、日志、消息队列共同检查结果;
- 长程跨系统任务:例如“从测试用例理解目标 → 在 App 完成业务 → 到后台核验状态 → 记录缺陷与复现证据”。
这比只测“点击某个按钮”更能反映 APP 测试 Agent 的真实价值。
局限性与未来方向
SaaS-Bench 的局限也很清楚:
- 它主要覆盖浏览器中的 SaaS,不是完整 OS / desktop agent;
- Docker 固定版本提高复现性,但降低了 UI 漂移覆盖;
- 106 个任务仍不足以代表所有专业工作流;
- verifier 的覆盖度和权重会影响结论;
- 高资源需求明显,GitHub README 建议并行评测机器具备很高内存,这会限制社区复现;
- 评测强调最终状态,但对过程安全、隐私泄漏、权限越界和用户确认机制涉及还不够。
未来我希望看到几类扩展:
- 动态 SaaS-Bench:定期升级应用版本,测试 UI 漂移鲁棒性;
- 过程监督版 SaaS-Bench:不仅检查最终状态,还检查关键中间状态和危险动作;
- human-in-the-loop 版本:在高风险步骤要求用户确认,评估 agent 如何请求澄清;
- 桌面混合版:把 SaaS 与本地文件、IDE、终端、邮件客户端结合,接近真实知识工作;
- 安全与隐私轨道:检查凭据处理、敏感字段暴露、越权访问和 prompt injection。