LivingScreen:GUI Agent 不能再假装屏幕是静止的
解析 arXiv 2026 论文 Benchmarking Living-Screen-Native GUI Agents on Short-Video Platforms。文章从 GUIAgent 专家视角评估 LivingScreen 对动态屏幕、观察控制、短视频原生界面和 APP 自动化测试的启发。
目录
- 为什么这篇论文值得 GUIAgent 领域关注
- 背景与问题定义:静态屏幕假设正在失效
- Living-Screen-Native GUI Agent 的核心形式化
- LivingScreen benchmark:环境、任务与指标
- 实验结果:强模型输在“看多久、看什么”
- 专家点评:真正贡献、被高估部分、工程落地建议
- 对 APP 自动化测试 / 移动端 QA 的启发
- 局限性与未来方向
- 参考链接
1. 为什么这篇论文值得 GUIAgent 领域关注
Benchmarking Living-Screen-Native GUI Agents on Short-Video Platforms 是一篇值得认真读的 GUIAgent benchmark 论文。论文地址:https://arxiv.org/abs/2606.04701,项目地址:https://github.com/BITHLP/LivingScreen。它的价值不在于再做一个通用 GUI grounding 排行榜,而在于挑出了 GUI Agent 评测中长期被默认、但在真实 App 场景里经常失效的前提:屏幕并不总是在两次动作之间静止等待 agent。
从领域位置看,LivingScreen 的贡献比“又一个短视频任务集”更关键。它把 GUI Agent 的能力边界从 click / type / scroll / grounding 推到 observation control(观察控制):agent 不仅要决定下一步点哪里,还要决定是否继续看、看多长、看哪个区域、用截图还是视频片段、以及愿意为动态信息支付多少时间和 token 成本。这一点对短视频、直播、信息流、IM、地图导航、交易行情、风控审核等移动 App 测试场景尤其重要。
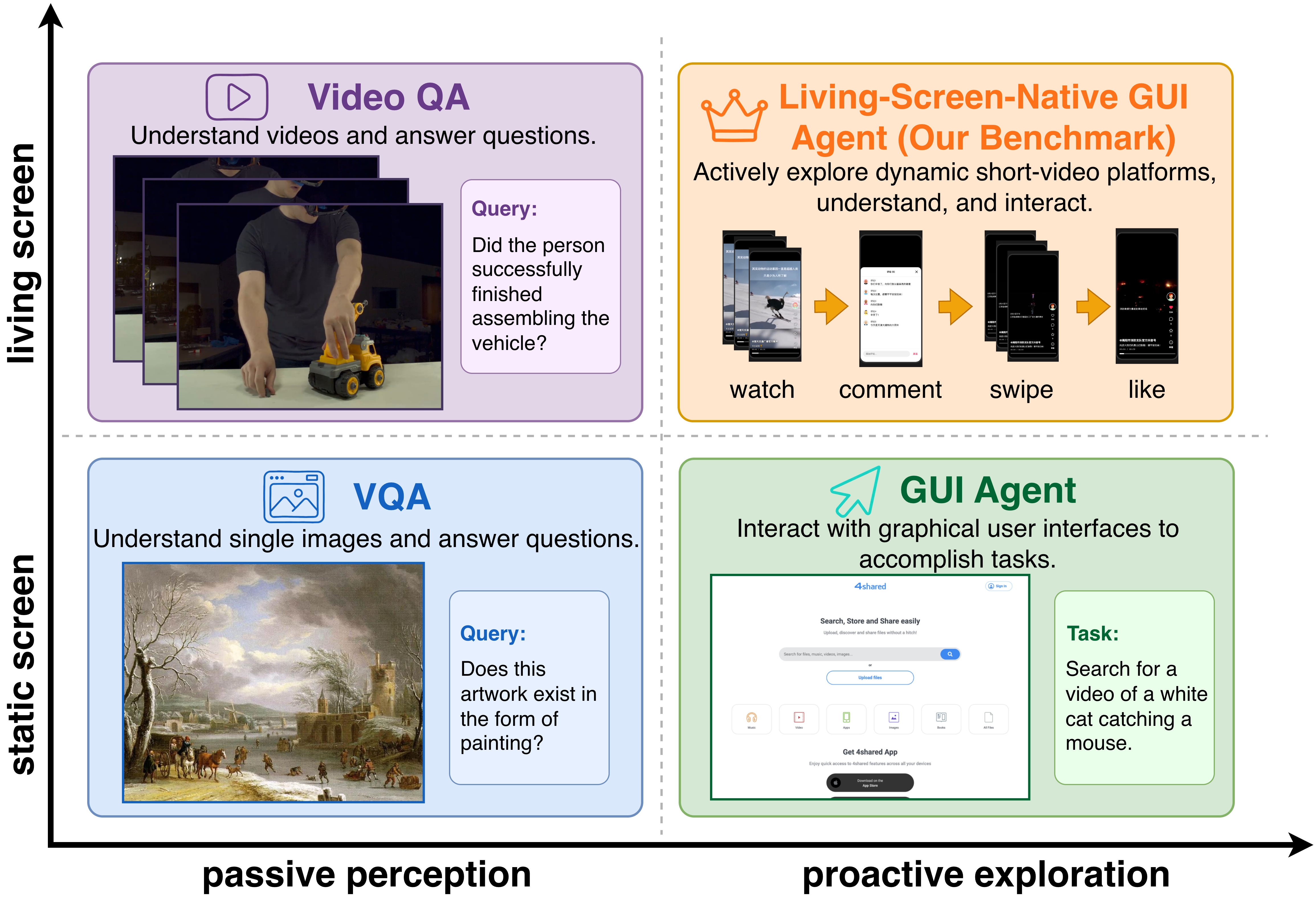
上图是论文最关键的定位图。传统 Video QA 有动态内容,但模型通常直接拿到视频文件,不需要在 GUI 中行动;传统 GUI benchmark 有点击和输入,但多数假设屏幕在 action 之间相对静止。短视频、直播、信息流、IM 消息流、地图导航、交易行情、运营监控和异常录屏都处在右上角:界面自己在变,agent 也要主动操作它。
可以用一个 GUIAgent 专家框架来审视这篇论文:
| 维度 | LivingScreen 的覆盖 | 专家判断 |
|---|---|---|
| GUI grounding | 涉及点赞、收藏、评论、举报、进度条跳转等短视频控件 | grounding 不是难点核心,但动作仍要落到原生 UI |
| 屏幕理解 | 需要理解视频内容、作者信息、评论、字幕、标签、动态播放状态 | 把 GUI 理解从静态截图扩展到时间窗口 |
| 计划与动作执行 | browse → watch → decide → operate 的闭环 | 强调观察策略和动作策略耦合 |
| 长程任务 | L2/L3 任务需要跨多个视频整合证据 | 长程不一定是很多点击,也可以是持续观察和选择性采样 |
| RL / 过程监督 | 本文主要是 benchmark,但 watch ratio 可变成过程奖励 | 为“看得少但看得准”的训练目标打基础 |
| benchmark 可信度 | 浏览器复刻短视频平台、三层任务、SR/NS/WR 联合指标 | 方向重要,但平台与数据仍是简化版 |
| OS/Web/Mobile/Desktop 迁移 | 聚焦短视频移动式界面,但动态屏幕问题跨平台存在 | 对 APP 自动化测试中的信息流、直播、IM、地图、行情和监控页面同样有启发 |
| 工程可部署性 | Playwright/Flask/browser replica,可复现性较好 | 离真实 App、真实推荐流、账号态还有距离 |
| 安全与隐私 | 涉及内容审核、偏好模拟、短视频数据 | 需警惕自动化浏览、隐私数据和内容治理风险 |
2. 背景与问题定义:静态屏幕假设正在失效
过去 GUI Agent 的主流抽象大致是:给定 instruction、当前 screenshot / DOM / accessibility tree、历史动作,模型输出下一步 action。这个抽象默认一个隐含条件:agent 不动作,环境就基本不动。WebArena、OSWorld、AndroidWorld、VisualWebArena、MacArena、WindowsWorld 等在线 benchmark 已经把 agent 放进真实或半真实环境,但多数任务仍然以“状态由 agent 的点击/输入推动”为主。
LivingScreen 指出,短视频平台违反了这个条件。视频播放不会等 agent 思考;评论、进度条、画面、字幕会随时间变化;下一条内容可能自动加载;用户是否应继续看,取决于已经看到的信息和任务目标。这让 GUI Agent 问题从离散步控制扩展到连续时间控制。
这不是短视频场景的小众问题。真实 App 里同样存在大量 living screen:
- 短视频、直播、信息流页面持续刷新和自动播放;
- IM / 社区 / 评论区不断出现新消息、新回复和状态变更;
- 地图导航、外卖配送、打车进度、物流轨迹随时间变化;
- 交易行情、风控告警、运营监控页面持续滚动;
- H5 / Hybrid App 中的活动页、弹窗、倒计时、异步加载会改变可操作状态;
- 录屏回放、异常视频和崩溃前行为轨迹需要边看边判断。
在这些场景里,“截一张图然后决策”很容易失败。截得太早,关键信息还没出现;看得太久,成本和延迟爆炸;看错区域,拿到大量无关信息;只看最终帧,丢掉过程事件。LivingScreen 的价值在于,它把这些问题归纳为一个可评测的能力:agent-initiated observation(由 agent 主动发起和控制的观察)。
3. Living-Screen-Native GUI Agent 的核心形式化
论文把标准 GUI agent 的 POMDP 做了两个关键改动。
第一,环境状态不只在 agent 动作后跳变,还会在动作之间连续演化。论文用自主流 Φ 表示这一点:视频播放、进度条前进、画面变化、评论内容展示等状态变化,不需要 agent 点击也会发生。
第二,观察不再是固定的一帧 screenshot,而是由 action 诱导的时间窗口。也就是说,agent 可以决定执行 watch,并选择观察时长、采样方式或视频片段。观察本身也有成本。
这个形式化听起来抽象,但它直接改变了 agent runtime 的设计:
-
Observation 变成 action 的一部分
传统 GUI agent 里,观察通常由环境自动给出;LivingScreen 里,观察是 agent 主动买来的信息。watch 太少会漏证据,watch 太多会浪费预算。 -
信息获取和任务执行耦合
点赞、评论、举报这类动作是否正确,取决于 agent 之前是否观察到了足够证据。动作失败不一定因为按钮没点准,也可能因为观察策略错了。 -
评测必须同时看准确率和信息效率
如果一个 agent 把每个视频都从头看到尾,最终答对并不代表智能;如果它只截一帧就猜,成本低但不可靠。LivingScreen 因此把 watch ratio 作为一等指标。 -
长程任务的含义发生变化
长程不再只是 30 步点击链,也可以是跨多个动态内容片段的证据积累。agent 需要在“继续观察当前视频”和“切换到下一条”之间做探索-利用权衡。
4. LivingScreen benchmark:环境、任务与指标
LivingScreen 包含三个核心组件:高保真的浏览器短视频平台复刻、三层任务套件,以及同时衡量准确性和效率的指标。
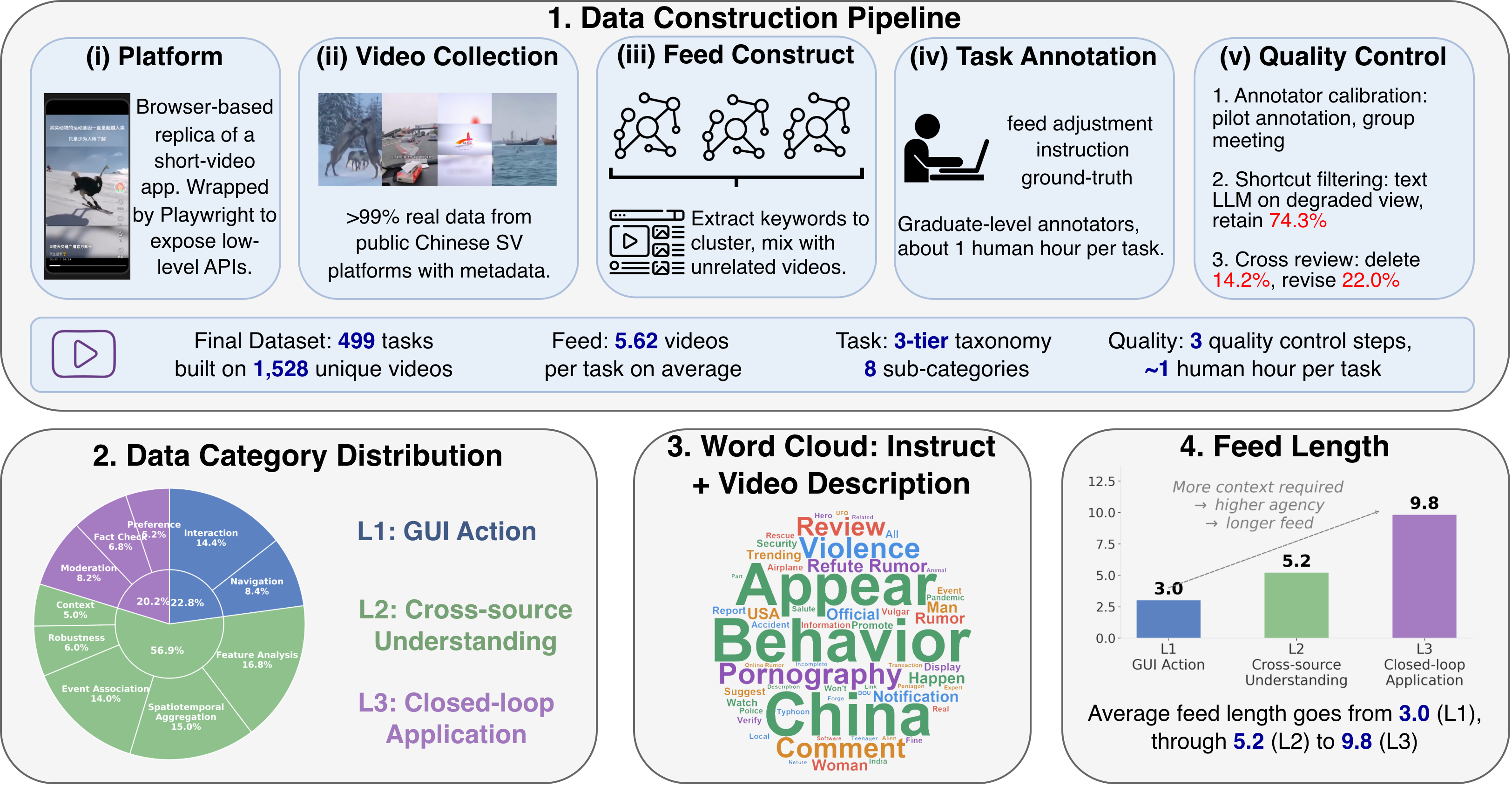
论文的任务分为三层:
| 层级 | 主要测试能力 | 例子 |
|---|---|---|
| L1 GUI action | 基础 GUI 原子动作 | like、collect、comment、report、swipe、seek |
| L2 Understanding | 跨 feed 的内容理解与证据整合 | 上下文关联、事件判断、特征分析、时空聚合 |
| L3 Application | 闭环浏览、判断和操作 | fact-checking、内容审核、偏好模拟 |
这里的设计比单纯“视频问答”更接近 GUI Agent。因为 agent 不是直接拿 mp4 文件做离线理解,而是在一个 native-like GUI 中通过 watch、swipe、seek、comment 等动作获取信息和完成任务。论文项目页还说明,环境以 Flask 后端和 Playwright/Chromium headless 运行,视频数据来自公开短视频相关数据集,包括 FakeSV、LiveBot、Video-SafetyBench 等。
评测指标有三个:
- SR(Success Rate):任务是否完成或回答是否正确;
- NS(Number of Steps):episode 中工具调用 / 动作步数,衡量操作成本;
- WR(Watch Ratio):agent 通过 watch 观看的 feed 时长占总 feed 时长比例,衡量观察成本。
这组指标是本文最值得借鉴的地方。很多 GUI benchmark 只看 final success,最多再看步数。但 LivingScreen 明确区分了“操作成本”和“观察成本”。对于动态界面,观察成本不只是 token 和延迟,还会影响任务时效:监控告警、直播内容审核、CI 日志排障都不允许 agent 无限制地看。
5. 实验结果:强模型输在“看多久、看什么”
论文的主表比较了视频输入 MLLM、多图输入 MLLM 和人类表现。核心结论很清楚:没有被测 frontier model 达到人类的 cost-accuracy trade-off。
| Model | Average SR | Average NS | Average WR | L1 Action SR | L2 Understanding SR | L3 Application SR |
|---|---|---|---|---|---|---|
| Human | 94.0 | - | 9.7 | 100.0 | 88.0 | 94.1 |
| Gemini-3.5 | 69.3 | 8.0 | 11.9 | 90.4 | 60.2 | 57.4 |
| Gemini-3.1 | 66.2 | 7.6 | 11.6 | 87.7 | 64.2 | 46.8 |
| Seed-2.0 | 64.8 | 8.1 | 15.5 | 88.6 | 68.3 | 37.6 |
| Seed-1.8 | 65.6 | 9.5 | 25.1 | 86.8 | 64.4 | 45.5 |
| Claude-Opus | 45.6 | 9.7 | 8.5 | 64.0 | 45.1 | 27.7 |
| GPT-5.5 | 29.8 | 10.1 | 14.4 | 50.9 | 38.4 | 0.0 |
从 GUIAgent 专家视角,这张表说明三件事。
第一,L1 基础动作不是最大瓶颈。强模型在 Action 层能到 80%–90% 左右,说明短视频 UI 的基础按钮操作并非不可学。真正的坍塌发生在 L2/L3:需要理解内容、跨视频整合证据、再执行判断时,成功率大幅下降。
第二,WR 暴露了模型策略的不稳定。人类平均 WR 约 9.7,说明人类会选择性观察;Seed-1.8 平均 WR 达 25.1,L3 WR 甚至到 53.1,表示它经常过度观看;另一些模型 WR 较低但 SR 也低,说明可能欠观察。
第三,强模型的视觉/语言能力不能自动转化为 observation control。视频理解模型可以回答视频问题,GUI agent 可以点按钮,但 living-screen-native 任务要求模型把两者合并成一个预算受限的闭环策略。
论文进一步统计了 observation behavior:
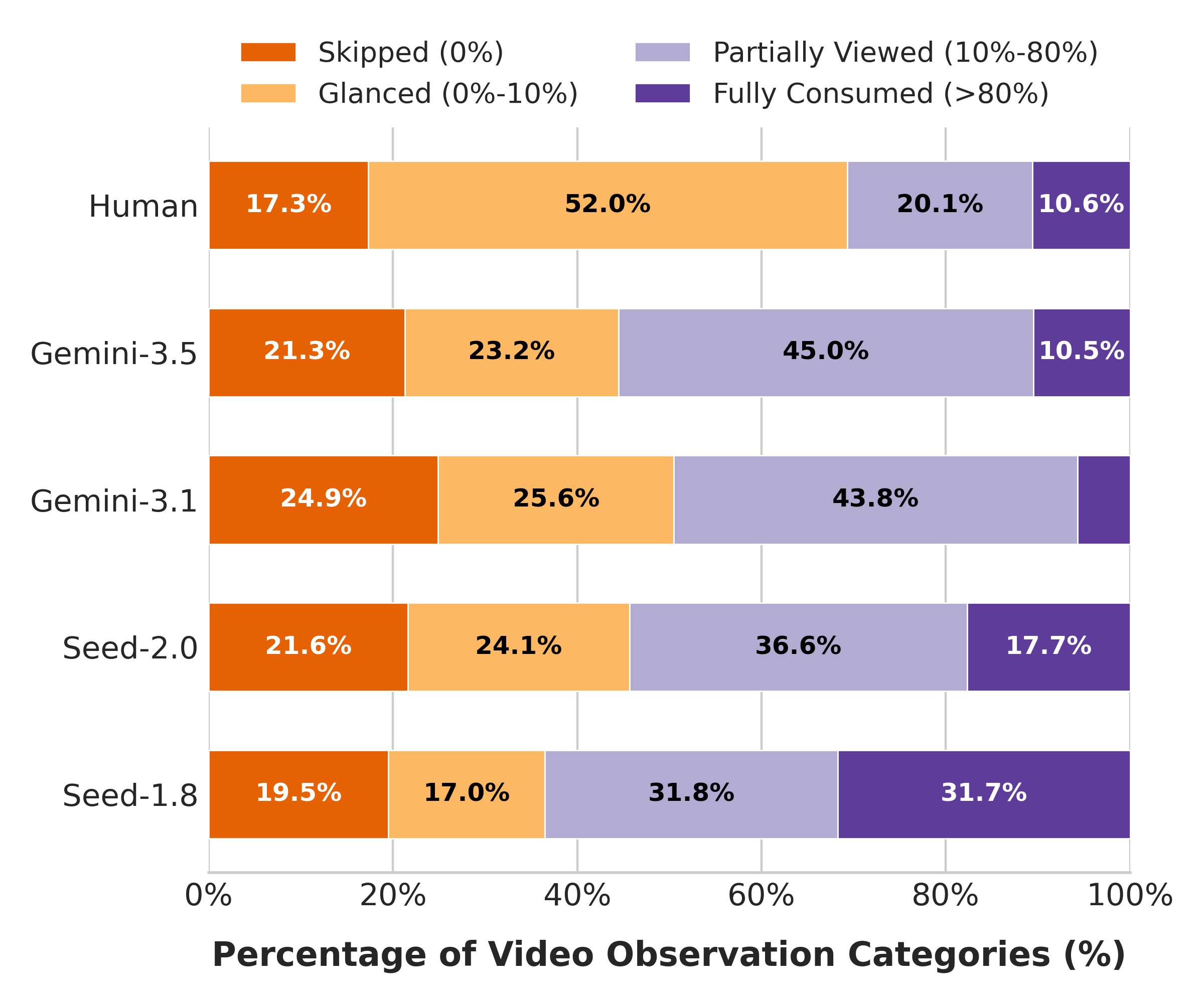
过度观察 / 不足观察的轨迹级统计也很有意思:
| Agent | Under ↓ | Over ↓ | Both ↓ |
|---|---|---|---|
| Gemini-3.5 | 51 | 29 | 13 |
| Gemini-3.1 | 39 | 25 | 9 |
| Seed-2.0 | 61 | 27 | 20 |
| Seed-1.8 | 48 | 43 | 24 |
这说明 failure mode 不是单一的“模型太懒,不愿意看”,也不是单一的“模型太啰嗦,看太多”。同一个 agent 可能在某些任务里还没看到关键证据就行动,在另一些任务里又把无关内容看很久。论文还做了 prompt-level intervention:让 Seed-1.8 “少看”“多看”或“模仿人类”。结果 Default 的 SR 是 65.6;Watch-Less 降到 56.3,Watch-More 降到 57.1,Mimic-Human 降到 59.4。这说明 observation control 不是靠一句 prompt 就能解决的,需要训练、策略建模或显式预算控制。
6. 专家点评:真正贡献、被高估部分、工程落地建议
6.1 这篇论文真正推进了什么?
LivingScreen 的真正贡献有三点。
第一,它把 GUI Agent 的环境模型从“动作驱动状态变化”扩展到“环境自主连续变化”。 这是一个很基础但重要的抽象修正。很多 desktop / mobile / web benchmark 默认 agent 的 action 是状态变化主因,但真实数字世界里,时间本身就是状态转移函数的一部分。
第二,它把观察控制变成可度量能力。 过去我们常说 agent 需要更好的 screen understanding,但很少问:agent 应该什么时候截图、什么时候录屏、什么时候等待、什么时候停止观察?LivingScreen 用 WR 把这个能力量化出来。
第三,它提醒 GUI Agent benchmark 不应只覆盖办公和网页表单。 短视频平台代表一种高动态、多模态、原生 GUI 与内容流交织的应用形态。未来 agent 会越来越多处理动态媒体、监控流、会议流和实时协作流,LivingScreen 是一个早期切片。
6.2 它和已有方向相比,位置在哪里?
如果按“静态/动态”和“是否 native GUI action”来放置:
- ScreenSpot、静态 GUI grounding:主要测单帧定位;
- WebArena / VisualWebArena:在线网页任务,有 GUI action,但页面通常不会自主连续变化;
- OSWorld / WindowsWorld / MacArena:桌面任务,更强调多应用和状态变更,但大部分仍是 agent action 驱动;
- Video QA:动态内容强,但通常没有 native GUI action;
- LivingScreen:动态内容 + GUI 原生动作 + 观察成本。
所以它不是替代 OSWorld 或 AndroidWorld,而是补了一个被漏掉的象限。它也和近期 DynamicGUIBench 一类工作相邻,但 LivingScreen 的特殊性在于短视频内容流让“观察多久”本身成为主要决策。
6.3 哪些结论可能被高估?
短视频平台复刻不等于真实平台。 浏览器 replica 有助于可复现,但真实抖音、TikTok、小红书、B 站等平台有账号态、推荐算法、反自动化机制、网络波动、权限弹窗、广告、直播、多语言和社区治理规则。benchmark 成绩不应直接外推到真实平台自动化。
WR 不是全部观察成本。 watch ratio 很有启发,但真实系统还要考虑视频分辨率、帧率、模型 token/视觉编码成本、延迟、API 价格、缓存复用,以及用户等待时间。一个低 WR agent 也可能因为高帧率或高分辨率消耗巨大。
任务分布仍然偏媒体内容理解。 LivingScreen 对 GUI action 的要求相对有限,主要难点是动态内容观察与理解。它对复杂桌面工作流、跨应用文件状态、权限和不可逆操作的覆盖不足。
模型榜单可能受 action space 和 prompt 设计影响。 watch、swipe、seek 等工具抽象如何暴露,会显著影响模型表现。不同 agent runtime 的等待、截图、历史保留策略也会改变结果。因此模型排名不应被过度解读。
6.4 工程落地建议
如果要把 LivingScreen 的思想迁移到生产 GUI agent,我建议复现的不是短视频任务,而是这套 观察预算 + 动态状态验证 机制:
- 把 observation 显式建模为工具调用,而不是 runtime 自动无限截图;
- 每次观察记录窗口、时长、分辨率、来源区域、token/延迟成本;
- 为动态任务设置 stop condition:看到足够证据就停止,而不是固定等待;
- 把 over-observation 和 under-observation 纳入失败诊断;
- 对动态 UI 保存时间轴 trace,而不是只保存最后一帧。
这对训练也很重要。未来 GUI Agent 的过程监督不应只奖励“点对了”,还要奖励“在合适时间以合适成本观察到了必要证据”。
7. 对 APP 自动化测试 / 移动端 QA 的启发
对 APP 自动化测试来说,LivingScreen 的启发非常直接:许多移动端测试失败并不是因为 selector 找不到,而是因为测试系统没有正确处理“界面正在变化”这件事。
7.1 动态 APP 页面不能只用截图 + 点击建模
Appium、UIAutomator、XCUITest、Maestro 这类工具通常擅长描述“找到元素、点击、输入、断言”。但在短视频、直播、IM、地图、交易行情、外卖配送、活动倒计时这类页面里,关键状态并不一定稳定停在某一帧。传统脚本容易出现三类问题:
- 截图太早,关键内容还没出现,导致误判;
- 等待太久,测试时长膨胀,回归套件不可用;
- 只断言最终页面,漏掉中间过程中的闪退、卡顿、错误 toast、短暂异常状态。
更合理的测试 runtime 应该提供:
observe_static(region)
observe_stream(region, duration, fps, stop_when)
wait_for(pattern | ui_state | timeout)
assert_timeline(events, oracle)
summarize_trace(video, ui_events, logs)也就是说,动态观察要成为自动化测试工具协议的一等公民,而不是在脚本里用 sleep(5) 勉强模拟。
7.2 Oracle 不应只判断最终状态,还要判断时间窗口
LivingScreen 的 WR 指标提醒我们:动态 App 测试里的 oracle 也需要时间维度。例如:
- 直播间进场后,评论区是否在合理时间内出现新消息;
- 地图导航中,定位点是否持续刷新,而不是停在旧位置;
- 支付后,成功页是否在 3 秒内出现,且中间没有错误 toast;
- 视频流播放时,加载 spinner 是否超过阈值;
- IM 收到消息后,会话列表、未读数、通知栏是否按顺序更新。
这些 oracle 不是“最后一张截图是否正确”,而是“某个事件是否在正确时间窗口内出现,并且没有伴随不应出现的异常事件”。
7.3 测试平台需要区分 over-observation 和 under-observation
移动端回归测试经常被两类成本拖垮:一类是等待不足导致 flaky,另一类是等待过度导致执行时间不可控。LivingScreen 把 under-observation / over-observation 单独统计出来,对测试平台很有借鉴价值。
对应到 APP 自动化测试,可以把失败归因拆得更细:
- selector failure:元素定位失败;
- action failure:点击、滑动、输入没有生效;
- under-observation:断言太早,证据不足;
- over-observation:等待策略保守,浪费执行时间;
- oracle failure:动态事件出现了,但测试断言无法表达;
- environment drift:网络、账号态、推荐流或系统权限导致轨迹偏移。
这比简单记录“case failed”更有助于自动修复测试脚本和优化等待策略。
7.4 对移动端 GUIAgent benchmark 的建议
如果为 APP 测试场景设计下一代 GUIAgent benchmark,LivingScreen 提供了一个很好的方向,但任务应进一步贴近真实 QA 闭环:
- 在短视频 App 中判断视频是否卡顿、黑屏、音画不同步,并自动采集证据;
- 在 IM App 中等待新消息、撤回、已读、未读数变化,并验证多端同步;
- 在地图 / 外卖 / 打车 App 中验证位置、ETA、状态流是否持续更新;
- 在电商直播间验证弹幕、购物袋、库存、优惠券倒计时和下单链路;
- 在 H5 / Hybrid 活动页验证倒计时、异步加载、弹窗和跳转链路;
- 在异常录屏中定位导致失败的关键 UI 事件,并生成可复现测试步骤。
这些任务比“点击按钮是否成功”更能区分一个 GUIAgent 是否真的能服务移动端 QA。
8. 局限性与未来方向
LivingScreen 还有几个明显局限。
第一,它主要聚焦短视频平台,GUI 动作空间相对窄。短视频是动态屏幕的典型代表,但不是所有动态 GUI。APP 信息流、直播、地图、IM、交易行情、H5 活动页和异常录屏各有不同动态结构。
第二,它对真实平台复杂性的建模仍有限。浏览器 replica 可以保证可复现,但真实移动 App 的触控、系统权限、推荐流、网络状态、账号态和反爬机制都会带来额外问题。
第三,评测仍以模型调用为主,还没有给出解决 observation control 的训练算法。论文证明了问题存在,但如何训练 agent 学会预算化观察,仍需要后续工作。
第四,安全和治理不是本文主线。短视频任务里的内容审核、举报、偏好模拟都有潜在双重用途;一旦 agent 能大规模浏览和操作真实内容平台,就必须考虑平台规则、用户授权、审计和限速。
后续最值得做的方向有三类:
- Observation policy learning:把 watch / wait / screenshot / clip 当成可学习动作,用成本约束训练观察策略;
- Dynamic trace verifier:把动态界面转成时间轴事件,支持 step-level 诊断、过程奖励和测试失败归因;
- Mobile QA-oriented dynamic GUI benchmarks:从短视频扩展到直播、IM、地图、交易行情、H5 / Hybrid 页面和异常录屏分析。
9. 总结
LivingScreen 的核心价值不是告诉我们哪个大模型最会刷短视频,而是提醒 GUI Agent 领域:computer-use agent 的世界不是静态截图序列,而是会自己流动的时间系统。一旦环境会自主变化,agent 的关键能力就不只是 grounding、planning、clicking,还包括观察控制、等待策略、证据足够性判断和信息成本优化。
对 APP 自动化测试来说,这个视角尤其重要。真正可用的移动端 GUIAgent 不仅要会点按钮、滑动页面、填写表单,还要会观察动态内容流、等待异步状态、判断证据是否足够、控制观察成本,并把观察过程转化为可审计的测试 trace。LivingScreen 把这个问题做成了一个清晰 benchmark,值得作为未来移动端 QA agent 评测设计的一个新锚点。
参考链接
- 论文:Benchmarking Living-Screen-Native GUI Agents on Short-Video Platforms,arXiv:2606.04701
- 项目:BITHLP/LivingScreen,https://github.com/BITHLP/LivingScreen
- 对比锚点:OSWorld、AndroidWorld、VisualWebArena、WindowsWorld、MacArena
- 相关方向:Dynamic GUI benchmark、Video QA、GUI grounding、process reward / observation policy learning