MacArena:终于把 GUI Agent 拉到真实 macOS 竞技场里
解析 arXiv 2026 论文 MacArena:一个运行在 Apple Silicon 虚拟化环境上的 macOS computer-use agent 在线基准。文章从 GUIAgent 专家视角讨论它相对 OSWorld、macOSWorld、AndroidWorld、VisualWebArena 的位置、可信度、局限,以及对 APP 自动化测试和移动端 QA 的启发。
目录
- 为什么这篇论文值得 GUIAgent 领域关注
- 背景与问题定义
- MacArena 的核心设计
- 实验结果与可信度评估
- 专家点评:真正贡献、被高估部分、工程落地建议
- 对 APP 自动化测试 / 移动端 QA 的启发
- 局限性与未来方向
- 参考链接
1. 为什么这篇论文值得 GUIAgent 领域关注
MacArena: Benchmarking Computer Use Agents on an Online macOS Environment 是 MacPaw Research 在 2026 年 6 月发布、并被 ICML 2026 AIWILD workshop 接收的一篇 computer-use agent benchmark 论文。论文地址:https://arxiv.org/abs/2606.06560,项目代码:https://github.com/MacPaw/MacArena。
MacArena 值得关注的原因很明确:过去一年 GUIAgent / computer-use agent 研究经常把“桌面自动化”讲得很泛,但真正落到 macOS 这个生态时,公开、可运行、可复现的在线基准仍然稀缺。OSWorld 是重要锚点,但其主力任务和环境长期更偏 Linux / Windows;AndroidWorld、VisualWebArena、WebArena 分别覆盖移动端和 Web;macOSWorld 虽然把 macOS 拉进来了,但任务空间更偏内置应用,且论文指出它运行在 x86 VM 上,和现代 Apple Silicon 机器并不匹配。
MacArena 的核心价值不是又多了一个 benchmark 名字,而是把 GUI agent 的评测问题从“会不会点屏幕”推进到“能不能在真实平台生态里完成多应用、第三方软件、执行式验证任务”。 对移动端 QA 来说,这个启发同样关键:Android / iOS 自动化也不能只看单页点击,必须考虑平台特异性、系统组件、第三方 SDK、权限弹窗、真实设备状态和可执行验证。
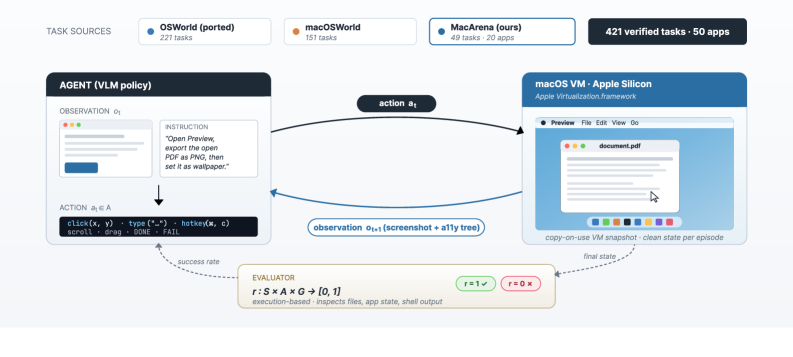
图 1:MacArena 的总体框架。任务来自 OSWorld port、macOSWorld 和 49 个新收集的 macOS-native tasks,总计 421 个经人工验证的任务,覆盖 50 个应用。每一步 agent 接收截图和可选 accessibility tree,在 Apple Silicon VM 中执行动作,最后由 execution-based evaluator 检查终态。这个闭环比静态 grounding 数据集更接近真实 computer-use agent。
站在 GUIAgent 领域专家视角,这篇论文真正值得讨论的是三个问题:
- 评测对象:它测的是在线、状态ful、执行式 GUI 自动化,而不是单帧 ScreenSpot 式定位。
- 平台迁移:它直接挑战“在 OSWorld / Linux 上表现好是否意味着能迁移到 macOS”的默认假设。
- 工程可复现性:它把 Apple Virtualization framework、UTM/VM 镜像、任务目录、代码仓库这些工程要素摆到台面上,让 macOS agent 评测变得更可落地。
2. 背景与问题定义
GUI Agent 的评测大致可以分成两条线。
第一条是 静态或半静态感知 / grounding:Mind2Web、AITW、ScreenSpot、ScreenSpot-V2/Pro、GUIrilla-Gold 等数据集主要考察模型能否理解页面、屏幕区域、控件描述或下一步动作。它们对训练视觉定位、动作预测很有价值,但不能充分回答长程任务里的状态追踪、错误恢复、UI 漂移和不可逆操作问题。
第二条是 在线交互式环境:OSWorld、WindowsAgentArena、AndroidWorld、WebArena、VisualWebArena、macOSWorld 等让 agent 在真实或模拟环境中逐步观察、行动、等待、失败或完成任务。这个方向更接近 GUI agent 的本质:一个部分可观测、闭环控制的 sequential decision-making 问题。
MacArena 的定位在第二条线上。论文把问题说得很清楚:现有 macOS 评测不足以代表真实 macOS computer-use agent 的难度,主要有几个缺口:
- 平台覆盖缺口:很多强基准集中在 Linux、Windows、Web 或 Android,macOS 长期被低估。
- 应用生态缺口:macOS 真实工作流大量依赖第三方软件,而不只是系统自带应用。
- 硬件 / 虚拟化缺口:Apple Silicon 已成为主流,基准若仍依赖 x86 VM,就无法反映当代 macOS 环境。
- 任务质量缺口:自动生成任务很多,但是否可执行、是否无歧义、是否能稳定验证,仍需要人工校验。
从 GUIAgent pipeline 来看,MacArena 主要推进的是 evaluation / environment / trace logging 层,而不是单点模型结构。它并不声称发明新的 GUI grounding 模型,也不主打 RL 训练算法;它更像是给后续模型训练、RL、自进化和 failure analysis 提供一个更真实的平台试验场。
3. MacArena 的核心设计
3.1 任务来源:421 个任务,50 个应用,三类任务池
MacArena 的任务由三部分组成:
- 221 个从 OSWorld port 到 macOS 的任务:用于观察同一类任务从 Ubuntu / Windows 迁移到 macOS 后,agent 能力是否保持。
- 151 个来自 macOSWorld 的任务:用于复用已有 macOS 任务资源。
- 49 个新收集的 MacArena-specific macOS-native tasks:用于补足第三方应用、复杂工作流和更贴近 macOS 生态的任务。
GitHub README 中的任务分布进一步说明:OSWorld 子集包含 multi_apps、LibreOffice Calc/Writer、Chrome、GIMP、VS Code、OS、Thunderbird 等;macOSWorld 子集包含 system apps、productivity、file management、system/interface、multi-app、media、advanced;MacArena 自建任务则覆盖 advanced apps、file management、productivity、system/interface、system apps。
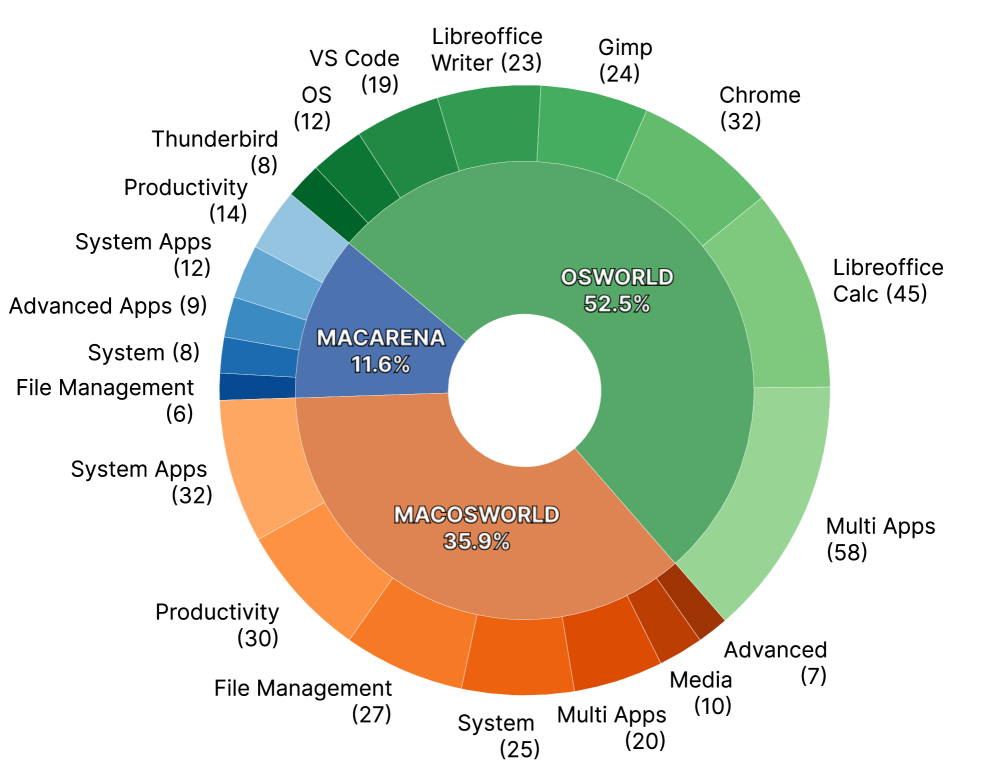
图 2:MacArena 的任务类别分布。对 GUI agent 来说,类别分布不是装饰信息,而是决定 benchmark 可信度的关键:如果任务过度集中在简单系统设置或单应用点击,模型排名很容易被 UI 模板记忆影响;多应用、文件管理、生产力、高级应用任务更能暴露长程状态追踪和恢复能力。
3.2 观测与动作:截图 + accessibility tree,动作仍以 GUI primitive 为主
论文把 MacArena 建模为 POMDP:agent 在每个 timestep 看到当前屏幕观测,然后输出动作,环境转移,最后由 evaluator 给出 ([0,1]) 的得分。观测包括:
- 当前 macOS desktop 的 screenshot;
- 可选的 macOS Accessibility tree,其中包含 labels、roles、bounding boxes 等结构化 UI metadata。
动作空间覆盖常见桌面 GUI 控制:
| 类别 | 动作示例 | 说明 |
|---|---|---|
| Mouse | MOVE_TO、CLICK、RIGHT_CLICK、DOUBLE_CLICK、DRAG_TO、SCROLL、MOUSE_DOWN、MOUSE_UP | 坐标级鼠标操作 |
| Keyboard | TYPING、PRESS、KEY_DOWN、KEY_UP、HOTKEY | 文本输入和快捷键 |
| Terminal / control | WAIT、FAIL、DONE | 等待、声明失败、声明完成 |
这个设计有两个含义。
第一,它没有把 agent 限制成纯 screenshot-only 模型。accessibility tree 在 macOS 自动化里非常实际:很多工程工具如果只靠截图,会在高 DPI、小控件、浮动窗口、菜单栏、弹窗上出现大量 grounding error;而 accessibility metadata 可以作为更稳定的 UI 结构信号。
第二,它仍然保留了 GUI primitive 的难度。即使有 accessibility tree,agent 仍需要做长程规划、动作选择、窗口焦点管理、快捷键使用、状态验证和错误恢复。相比 API-only 或 CLI-only benchmark,它更接近普通用户桌面上的 agent 行为。
3.3 人工验证与执行式评估:比“看起来像任务”更重要
MacArena 强调所有任务经过人工验证:可执行、无歧义、规格正确。这个点容易被忽略,但它是 GUI agent benchmark 的生命线。
很多自动生成 GUI 任务的问题不是“数量不够”,而是:
- 初始状态不稳定,任务有时根本跑不通;
- 指令歧义,多个终态都可能被认为正确;
- evaluator 只检查表面状态,隐藏了 oracle 或 reward leakage;
- UI 版本变更后任务失效;
- 任务过度模板化,模型靠分布记忆就能拿高分。
MacArena 没有完全解决这些问题,但至少把 human verification + execution-based evaluation 作为核心卖点。对于 computer-use agent 来说,终态验证比 step accuracy 更重要:一个 agent 可能每一步看起来合理,但最终文件没有保存、邮件没有发送、设置没有生效,那就是失败。
4. 实验结果与可信度评估
论文评测了 UI-TARS-1.5 7B、Qwen3-VL 2B、Qwen3-VL 4B 和 OpenAI CUA 等 baseline。几个数字很值得细看。
4.1 总体成功率:OpenAI CUA 领先,但没有到“可托管桌面”的程度
在 MacArena 全量任务上,论文表 3 给出的总体成功率为:
| 模型 | Overall success rate |
|---|---|
| UI-TARS-1.5 7B | 21.14% |
| Qwen3-VL 2B | 11.40% |
| Qwen3-VL 4B | 24.23% |
| OpenAI CUA | 31.83% |
OpenAI CUA 最高,但 31.83% 仍说明当前 GUI agent 离“稳定接管真实操作系统环境”很远。对 APP 自动化测试而言,这个数值意味着:可以让 agent 做探索式测试、辅助生成用例、定位低风险重复路径;但若让它直接处理支付、发布、删除、账号权限或隐私数据,就必须有权限边界、确认机制和可回放日志。
4.2 子集差异:macOSWorld 容易得多,MacArena-specific 任务更能拉开差距
按子集看,OpenAI CUA 在 macOSWorld subset 达到 52.32%,但在 OSWorld ported subset 只有 16.74%,在 MacArena-specific subset 为 36.73%。UI-TARS-1.5 7B 在 OSWorld subset 为 21.27%,macOSWorld subset 为 24.50%,MacArena subset 降到 10.20%。
这说明“macOS benchmark”内部也不能一概而论。macOSWorld 任务如果更简单、更偏系统内置应用,就会给 agent 一个偏乐观的估计;而 MacArena-specific 任务虽然只有 49 个,但更可能暴露真实 macOS 生态里的第三方应用、复杂窗口和长链路问题。
4.3 Ubuntu vs macOS:同一类任务迁移后明显掉分
论文表 4 比较了原始 OSWorld Ubuntu 任务和 MacArena 中 port 到 macOS 的 OSWorld subset。在 15-step 设置下:
| 模型 | Ubuntu | macOS | Δ |
|---|---|---|---|
| UI-TARS-1.5 7B | 24.5 | 21.27 | -3.23 |
| OpenAI CUA | 26.0 | 16.74 | -9.26 |
| Qwen3-VL 2B | 17.0 | 9.95 | -7.05 |
| Qwen3-VL 4B | 26.2 | 16.36 | -9.84 |
这组结果是论文最有价值的证据之一:跨平台 GUI 能力不是自然迁移的。很多模型在 Linux / Windows / Web 上形成的视觉模式、快捷键习惯、窗口管理假设,在 macOS 上会失效。比如菜单栏位置、应用设置入口、窗口焦点、权限弹窗、Finder 行为、快捷键组合和第三方 app 的 UI convention,都可能改变 action trajectory。
4.4 多应用任务仍是硬骨头
表 3 中 multi-app 任务普遍很低。在 OSWorld subset 的 Multi-App 行,UI-TARS-1.5 为 0.00%,Qwen3-VL 2B 为 1.72%,Qwen3-VL 4B 为 3.45%,OpenAI CUA 为 1.72%。macOSWorld subset 的 Multi-App 也只有 5.00% 到 15.00%。
这和 GUI agent 的核心难点一致:真正难的不是单次点击或单应用表单,而是跨应用、跨页面、跨系统组件的状态传递——从通知进入 App,从 Native 跳到 WebView,从登录页跳到权限弹窗,从地图组件回到订单页,从支付 SDK 回流到业务页。这类任务要求 agent 同时解决:
- 任务级记忆:当前子目标完成到哪一步;
- 状态一致性:不同应用中的对象是否对应;
- 窗口 / 焦点管理:当前输入到底进了哪个应用;
- 错误恢复:复制失败、弹窗遮挡、文件重名、权限提示如何处理;
- 可验证终态:最终结果如何检查。
4.5 步数消耗:MacArena-specific 任务更长、更难
论文表 5 报告 OpenAI CUA 的平均步数:
| 子集 | Avg. Steps (All) | Avg. Steps (Done) |
|---|---|---|
| macOSWorld | 10.92 | 8.05 |
| OSWorld | 13.88 | 11.08 |
| MacArena | 13.96 | 12.69 |
MacArena-specific subset 无论所有任务还是完成任务,平均步数都最高。这意味着它不仅是“换了平台”,还更接近长程任务。对 agent 研究来说,步数越长,越容易暴露历史压缩、planning、recovery、grounding drift 和上下文污染问题。
5. 专家点评:真正贡献、被高估部分、工程落地建议
5.1 真正贡献
第一,MacArena 把 macOS 作为一等公民拉进了在线 GUI agent 评测。 这件事对领域很重要。macOS 不是 Linux 的皮肤,也不是 Web 的容器;它有自己的菜单栏、权限模型、应用生态、快捷键习惯、窗口行为和 Apple Silicon 虚拟化约束。
第二,它提供了跨平台泛化的反证。 Ubuntu 到 macOS 的掉分,以及模型在不同子集上的排名差异,说明当前 benchmark 分数可能包含大量任务分布熟悉度。一个模型在 OSWorld 上强,不等于它真的学会了“使用电脑”。
第三,它强调任务质量和执行式评估。 421 个任务不算最大,但全部人工验证、覆盖 50 个应用、包含第三方软件,比单纯堆自动生成任务更有评测价值。
第四,它为 macOS agent 的工程复现提供了入口。 代码仓库、任务目录、VM 镜像、Apple Silicon 环境,使它不只是论文里的 benchmark,而是可以被工程团队拿来构建本地 golden task suite 的基础。
5.2 可能被高估的部分
第一,MacArena-specific 任务只有 49 个。 这些任务很重要,但数量仍偏少。论文中“macOS 更难”的结论方向可信,但如果要细分到具体 app 类别、任务类型或模型排名,样本规模还不足以支撑过强结论。
第二,accessibility tree 既是现实优势,也可能是隐含 oracle。 macOS Accessibility API 在工程上很合理,但如果 benchmark 中 accessibility metadata 过于完整,agent 可能绕过一部分视觉理解难题。真实部署时,不同 app 的可访问性支持差异很大,Electron、原生 AppKit、SwiftUI、WebView、游戏/设计工具的结构信息质量并不一致。
第三,VM 环境不等于真实用户桌面。 Apple Silicon Virtualization framework 是巨大进步,但真实用户环境里还有登录态、隐私数据、公司安全软件、复杂文件目录、多显示器、外设、网络波动、通知弹窗、权限请求、不同 app 版本等问题。benchmark 仍然只是一个可控切片。
第四,模型成功率低,不代表任务都等价困难。 31.83% 的总体成功率说明 agent 仍弱,但要判断论文结论,需要进一步看失败模式:是视觉 grounding 错、规划错、权限问题、evaluator 严格、任务本身不清楚,还是步数上限导致未完成?论文给出总体和类别数字,但后续如果能公开更细粒度 failure taxonomy,会更有价值。
第五,benchmark 也可能被训练化。 OSWorld 已经成为训练环境和 RL playground;MacArena 如果被广泛采用,也会面临 benchmark overfitting。未来需要隐藏测试集、版本化任务、UI drift 测试和任务生成/验证协议,而不是只看排行榜。
5.3 可复现 / 可落地建议
如果把这篇论文迁移到 APP 自动化测试,不应先追求“训练一个全能 GUI agent”,而应先复现三件事:
- 先复现 benchmark harness,而不是模型。 在真实或仿真的 Android / iOS 环境中跑通设备 reset、账号态 reset、动作执行、日志记录、终态验证。没有稳定 harness,后续模型改进都不可评估。
- 建立移动端 QA golden tasks。 例如:登录、权限授权、Push 跳转、WebView 回流、支付前校验、弱网重试、IM 消息同步、地图定位变化、直播间状态验证。这些任务比通用点击任务更能代表真实 APP 测试需求。
- 把 accessibility hierarchy + screenshot + test framework / API 混合起来。 GUI primitive 用于观察和不可替代操作;控件树用于稳定定位;Appium、UIAutomator、XCUITest、Maestro、deeplink、mock API 用于确定性控制;最后用 UI 状态、业务数据、日志、网络请求和崩溃信息做 verification。
6. 对 APP 自动化测试 / 移动端 QA 的启发
6.1 不要用 WebAgent 思维低估移动端平台差异
Web automation 往往有 DOM、URL、网络请求和明确表单结构;移动端 App 则有 Activity / ViewController 生命周期、权限弹窗、系统相册、通知、键盘、WebView、第三方 SDK、前后台切换和设备状态。MacArena 的跨平台掉分提醒我们:GUI agent 需要针对真实平台单独适配和评测,不能假设 Web / Linux / 桌面能力自然迁移到 Android 或 iOS。
6.2 APP 自动化测试应采用“混合动作”而不是纯点按
对移动端 QA 来说,最可靠架构不是 screenshot-only,也不是 API-only,而是按风险和确定性选择动作通道:
- 页面跳转、账号态、服务端状态:优先 deeplink、mock API、测试接口;
- Native 控件和系统弹窗:UIAutomator / XCUITest / Appium / Maestro + accessibility hierarchy;
- 视觉内容、直播、短视频、地图:screenshot / video trace + 视觉模型;
- 高风险操作:人类确认 + policy gate;
- 每一步:记录 screenshot、控件树、action、client log、network log、crash log,形成可回放 trace。
MacArena 的动作空间仍偏 GUI primitive,但它提示评测时要保留真实平台闭环;工程落地时则应引入更多确定性通道。
6.3 要把“验证”放到 agent loop 内,而不是只放到 benchmark 末尾
论文中的 execution-based evaluator 用于最终打分。APP 测试系统里,类似 evaluator 应该前移到每个关键步骤之后:
- 点击按钮后验证页面、控件、toast 或 loading 是否变化;
- 发送消息后检查会话列表、未读数、服务端状态和多端同步;
- 支付前后验证订单状态、金额、回调和异常兜底;
- 切前后台后检查生命周期、推送、定位和恢复状态;
- 删除、支付、发布等不可逆动作前要求策略确认。
这也是 GUIAgent 从 demo 走向 QA 工具的关键:不是让模型“更自信”,而是让系统“更可观察、更可回滚、更少不可逆”。
6.4 本地化和安全会成为移动端 QA agent 的核心问题
macOSWorld 和 MacArena 都强调语言、平台和真实环境差异。移动端更是如此:系统语言、输入法、地区、厂商 ROM、权限弹窗、隐私合规、账号体系、灰度实验和推荐流都会影响 agent。未来移动端 GUIAgent benchmark 如果只测英文、干净模拟器和固定账号态,会系统性低估真实 APP 测试难度。
7. 局限性与未来方向
MacArena 后续最值得扩展的方向有五个:
- 扩大 MacArena-native 任务数量:49 个新任务还不够,尤其需要更多 IDE、Terminal、浏览器、文档、设计工具、会议软件、云盘、开发者工具任务。
- 加入 UI drift 和版本漂移测试:同一任务在不同 macOS 版本、应用版本、语言设置、屏幕分辨率下是否仍可完成。
- 强化失败模式标注:把失败分成 grounding、planning、memory、permission、focus、evaluator、timeout、irreversible action 等类别。
- 支持 hybrid action benchmark:除了 GUI primitive,也评测 CLI、AppleScript、Shortcuts、MCP、app-specific API 的合理使用。GUI-only 并不总是最安全或最高效。
- 加入安全和隐私约束:限制敏感文件访问、检测越权截图、记录凭据处理、要求高风险操作确认,这些对真实 macOS agent 比排行榜更重要。
一句话总结:MacArena 不会直接让 GUI agent 变强,但它让我们更难继续假装“跨平台 GUI agent 已经可用”。 它把平台差异、第三方应用、执行式验证和真实运行环境摆到了研究者面前。对 APP 自动化测试来说,这篇论文最大的启发是:先建设可复现评测场,再谈自动化能力;先做 trace、verification、permission 和 device-state control,再谈 autonomy。
8. 参考链接
- 论文:MacArena: Benchmarking Computer Use Agents on an Online macOS Environment — https://arxiv.org/abs/2606.06560
- arXiv HTML: https://arxiv.org/html/2606.06560v1
- 代码仓库: https://github.com/MacPaw/MacArena
- 项目介绍: https://research.macpaw.com/publications/macarena
- OSWorld: https://os-world.github.io
- macOSWorld: https://macos-world.github.io