HiViG:GUI Agent 的 critic 不该只打分,还要看坐标和记住历史
解析 arXiv 2026 论文 A History-Aware Visually Grounded Critic for Computer Use Agents:它如何用宏动作历史与视觉落点校验提升 web、mobile、desktop computer-use agent 的测试时可靠性。
目录
- 为什么这篇论文值得 GUIAgent 领域关注
- 背景与问题定义
- HiViG 的核心方法拆解
- 训练数据与系统实现细节
- 实验结果与可信度评估
- 专家点评:真正贡献、被高估部分、工程落地建议
- 对 macOS 研发效率工具 / GUI 自动化的启发
- 局限性与未来方向
- 参考链接
1. 为什么这篇论文值得 GUIAgent 领域关注
今天选读的是 2026 年 6 月新挂出的 A History-Aware Visually Grounded Critic for Computer Use Agents。论文提出 HiViG,全称是 History-aware Visually Grounded test-time intervention framework。它不是再训练一个端到端 GUI agent,也不是再做一个静态 GUI grounding benchmark,而是把 critic 放到 computer-use agent 的执行环里,在动作真正执行前做两件事:
- 维护一份压缩后的 macro-action history,让 agent 知道“已经完成了什么、尝试过什么、哪里失败过”;
- 对即将执行的像素坐标做 visually grounded critique,即把真实落点标到当前截图上,判断点击、输入、滚动是否真的落在正确 UI 元素上。
论文地址:https://arxiv.org/abs/2606.11078
代码地址:https://github.com/G-JWLee/HiViG
站在 GUIAgent 领域专家视角,这篇论文值得关注的原因是:它抓住了当前 computer-use agent 一个非常工程化、但经常被论文轻描淡写的问题——GUI agent 的错误很多发生在执行前最后一厘米。策略模型的文本意图可能是对的,比如“点击 Sales 菜单”,但输出坐标可能偏到旁边的 Catalog;也可能它已经尝试过某条路径失败,却因为上下文窗口只保留最近几帧截图而反复回到同一个无效循环。HiViG 的价值不在于“critic 能说漂亮话”,而在于它把 critic 约束到 历史状态追踪 + 屏幕落点验证 + 执行前纠错 这三个更接近真实 GUI 自动化的环节。
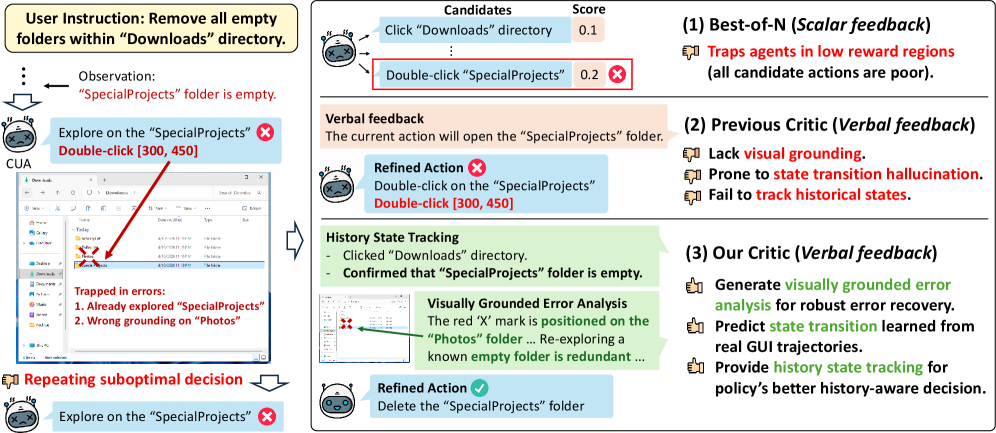
图 1:论文对 test-time intervention 的问题定位。标量 reward 只能给候选动作打分;普通 verbal critic 容易相信 policy 的文本意图;HiViG 则要求 critic 同时看历史进展和真实坐标落点。对 GUI agent 来说,这比“多采样几个动作再挑最高分”更贴近执行可靠性问题。
2. 背景与问题定义
过去两年 GUIAgent / computer-use agent 的主线大致可以分成几类:
- GUI grounding:ScreenSpot、UI-AGILE、RegionFocus、GUI-G1 等强调从截图或元素描述定位 UI 控件;
- 交互式 agent benchmark:OSWorld、AndroidWorld、VisualWebArena、WindowsAgentArena、DeskCraft、MacArena 等强调多步闭环执行;
- 训练范式:从 imitation / SFT,到过程 reward、RL、self-evolution、trajectory distillation;
- 部署可靠性:安全边界、权限控制、隐私、可回放 trace、失败恢复、人类确认。
HiViG 所在的位置很清楚:它不是替代 policy model,而是一个 测试时干预层。这类方法的目标是:当底层 policy 已经能读屏、规划、输出 JSON tool call 时,如何在动作执行前减少明显错误。
论文批评了两类已有方案:
- 标量过程奖励模型(PRM / scalar feedback):它可以告诉你哪个候选动作分数高,但当所有候选动作都很差时,分数本身不给恢复路径。GUI 坐标空间又是连续的,错 20 个像素可能就是完全不同的控件。
- 普通 verbal critic:它能给自然语言建议,但常常过度相信 policy 的文本 intent,而不是检查真实坐标、截图和 UI 状态。因此它可能批准“语义正确、落点错误”的动作。
GUI agent 的难点在于很多动作不可逆或高成本:发送邮件、删除文件、提交表单、改配置、在 IDE 中运行脚本、移动文件。执行后再纠错在 benchmark 里可能只是扣分,在真实 macOS 研发效率工具里可能就是事故。因此,pre-execution verification 是一个比事后反思更值得工程化的方向。
3. HiViG 的核心方法拆解
HiViG 的整体框架由一个 multimodal critic 驱动,核心包含两个能力。
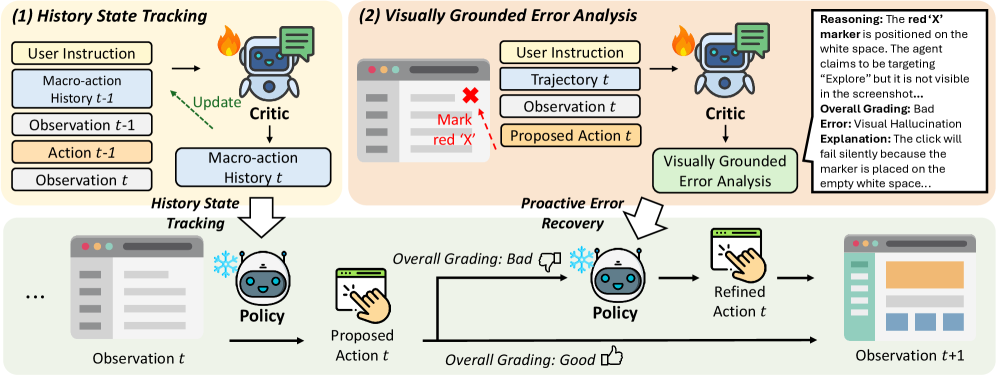
图 2:HiViG 的系统框架。左上角把连续微动作压缩成宏动作历史;右上角用视觉标记检查待执行坐标;下方把 history 和 critique 注入 policy 的下一次决策。这个结构很适合作为 GUI agent 的 middleware,而不是强绑定某个模型。
3.1 Macro-action history:把“最近几帧截图”升级成“已完成目标”
典型 computer-use agent 的历史上下文会保留完整动作序列,但视觉观察只能保留最近 W 帧。长程任务中,这会导致两类问题:
- agent 忘记早期已经完成的子目标;
- agent 忘记某个路径已经失败,于是重复点击、重复搜索、重复回退。
HiViG 的 history state tracking 不只是复述动作,而是比较 o_t 和 o_{t+1} 的视觉变化,把微动作压缩成“已经达成的宏状态”。例如,不是记录“点击、等待、输入、点击”,而是记录“已打开目标页面并完成筛选条件输入,但尚未提交”。这比原始日志更适合放进上下文,也更容易帮助 policy 避免短视循环。
3.2 Visually grounded error analysis:不要相信文本意图,要看真实坐标
GUI agent 常见错误不是“完全不知道要干什么”,而是最后输出的动作参数错了:坐标偏移、滚动幅度太小、输入框未聚焦、弹窗阻挡、按钮未加载完成等。HiViG 在训练和推理时都强调 raw execution coordinates:它把待执行坐标用红色 X 标到截图上,让 critic 判断落点下方到底是什么 UI 元素,并预测动作会导致什么状态变化。
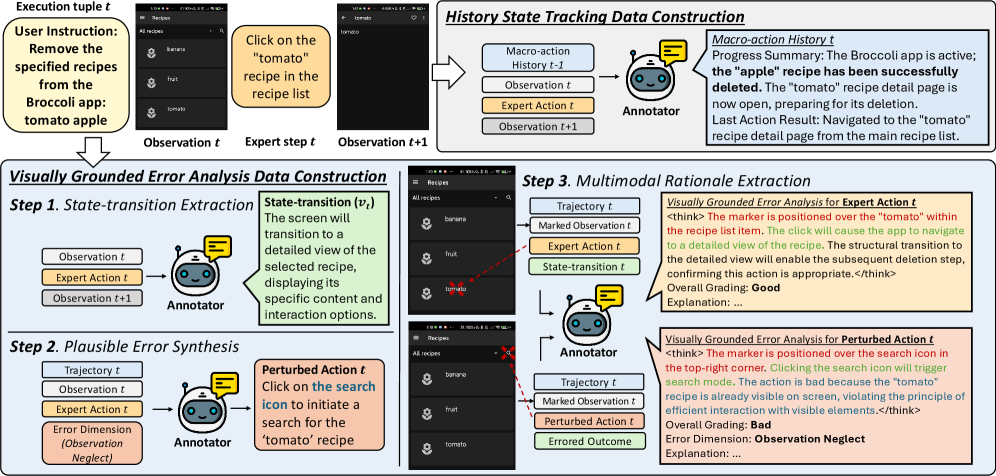
图 3:训练数据构造。上半部分用于历史状态追踪;下半部分用于视觉 grounded 错误分析。关键点是错误不是随便扰动,而是围绕 GUI agent 常见失败模式合成,并用真实状态转移约束 annotator。
这点和很多 GUI grounding 工作不同。ScreenSpot 类任务主要问“给定指令能不能点到元素”;HiViG 问的是“policy 已经提出一个动作,这个动作在当前真实界面上会不会做错,如果错了该如何改”。它更接近 OSWorld / AndroidWorld / WindowsAgentArena 里的闭环执行可靠性,而不是单步定位准确率。
4. 训练数据与系统实现细节
论文使用 ScaleCUA 的多域 GUI 轨迹作为源数据,覆盖 web、mobile、desktop。训练 HiViG-critic 的数据共 52k mixed SFT samples:
- 20k history state tracking 样本;
- 32k visually grounded error analysis 样本,其中 16k expert actions、16k perturbed actions。
标注器使用 Qwen3-VL-32B-Thinking。目标 critic 初始化自 Qwen3-VL-8B-Thinking,用 LlamaFactory 训练 1 个 epoch;论文报告训练使用 8 张 H100 80GB,约 4 小时。测试时框架最多会让 policy 重新生成一次动作,因此和 Best-of-N 标量 reward 的计算预算做了对齐。
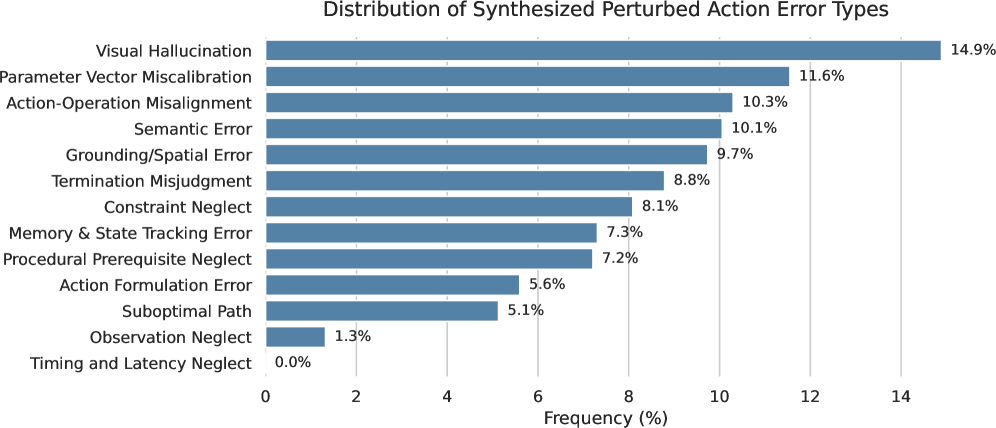
图 4:错误类型分布。论文把 failure modes 分成视觉/空间 grounding 与认知执行两大类,共 12 种错误。这比简单随机坐标扰动更有价值,因为真实 GUI agent 往往错在弹窗、时序、约束、终止判断、动作参数这些工程细节上。
一个很重要的设计是 intent masking + visual marker:训练中有 30% 样本会遮蔽 policy 的 verbal intent,避免 critic 只读文本不看图;同时在截图上画出落点标记,让模型把数字坐标转成视觉锚点。论文的 ablation 显示,去掉 visual marker 会让 WebArenaLitev2 表现从 25.3 降到 20.8;去掉 intent masking 会让 AndroidLab 从 51.5 降到 47.1。这说明 GUI critic 也会走捷径:只要给它文本 intent,它就可能忽略真实 UI。
5. 实验结果与可信度评估
论文在三类交互式 GUI benchmark 上评测:
- WebArenaLitev2:web 环境,154 个任务,覆盖 shopping、CMS、map、GitLab、Reddit 等;
- AndroidLab:mobile 环境,138 个任务,9 个原生应用;
- WindowsAgentArena:desktop 环境,145 个 Windows 11 任务,覆盖 Office、Web Browsing、Windows System、Code、Media、Windows Utilities。
底层 policy 包括 Qwen3-VL-32B-Thinking 和 Gemini-3-Flash。对比对象包括 base agent、OpenCUA / SE-WSM 风格 scalar feedback、CGI 风格 zero-shot verbal critic,以及 GUI-Critic-R1。
核心结果如下:
| 方法 | Qwen3 WebArenaLitev2 | Qwen3 AndroidLab | Qwen3 WindowsAgentArena | Qwen3 Avg. | Gemini WebArenaLitev2 | Gemini AndroidLab | Gemini WindowsAgentArena | Gemini Avg. |
|---|---|---|---|---|---|---|---|---|
| Base agent | 13.0 | 44.2 | 35.7 | 31.0 | 30.5 | 58.0 | 35.8 | 41.4 |
| 最强非 HiViG baseline | 16.9 | 49.3 | 35.2/37.9 | 32.5 | 30.5 | 57.2 | 37.9 | 41.2 |
| HiViG | 25.3 | 51.5 | 38.0 | 38.3 | 45.5 | 61.6 | 44.2 | 50.4 |
论文声称 HiViG 相比最强 baseline 平均提升:Qwen3-VL-32B-Thinking +5.8%,Gemini-3-Flash +9.0%。其中最显著的是 Gemini-3-Flash 在 WebArenaLitev2 上从 30.5% 提升到 45.5%,绝对提升 15.0%;Qwen3 在 WebArenaLitev2 Map 类任务上从 3.9% 提升到 23.1%;Gemini 在 WindowsAgentArena Office 类任务上从 4.7% 提升到 23.3%。
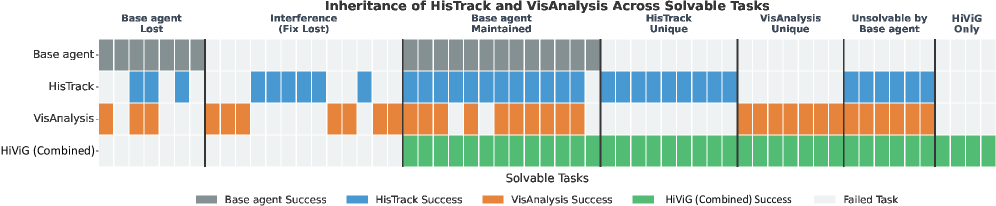
图 5:任务级成功集合重叠。HisTrack 和 VisAnalysis 解决的是不同错误子集,组合后还有额外 synergy。这支持了论文的核心判断:长程记忆和视觉落点校验是正交能力,不应二选一。
从可信度看,优点是评测覆盖 web / mobile / desktop 三域,且和强闭源 policy 做了组合测试;缺点也明显:论文承认由于长程 GUI 任务成本高,实验结果来自 single run。GUI benchmark 本身存在 UI 漂移、任务随机性、网站状态变化和环境版本差异,因此这些数字更适合理解为“强趋势”,不应理解为精确可复现实验常数。
6. 专家点评:真正贡献、被高估部分、工程落地建议
6.1 真正贡献
第一,HiViG 把 critic 从“评价器”推进成了“执行前安全阀”。 过去很多 PRM 或 critic 方案本质上是在轨迹后处理或候选排序。HiViG 的不同点是:它要求 critic 在动作执行前验证坐标、预测状态变化、提供可操作修正。这对真实 GUI 自动化更关键。
第二,它明确指出 verbal intent 不是 ground truth。 很多 agent trace 里会保存“我将点击 X”这类 reasoning,但真正改变系统状态的是坐标、按键、输入内容和时序。HiViG 用 visual marker 和 intent masking 迫使 critic 看图,这个设计对所有 screenshot-only GUI agent 都有借鉴价值。
第三,它把长程历史压缩做成了独立能力。 这和简单 RAG 或完整 trace 拼接不同。macro-action history 关注“完成进度”而非“日志完整性”,适合长程任务上下文预算有限的场景。
6.2 可能被高估的部分
第一,跨平台泛化不能等同于真实 macOS 泛化。 论文覆盖 web、Android 和 WindowsAgentArena,但没有直接评测 macOS 原生应用。WindowsAgentArena 的桌面场景很有价值,但 macOS 的菜单栏、权限弹窗、AppleScript / Accessibility API、窗口管理、Finder / Xcode / Terminal 组合工作流仍然不同。
第二,critic 自身可能引入新延迟和新错误。 完整 HiViG 每步可能需要 history tracking 和 visual analysis 两次 critic inference,再触发 policy 改写动作。对本地研发效率工具来说,这会直接影响交互延迟和成本。论文证明了成功率收益,但没有充分展开端到端 latency / dollar cost / 用户等待体验。
第三,训练数据依赖 ScaleCUA 与强 annotator。 52k 样本来自已有轨迹和 Qwen3-VL-32B-Thinking 标注。虽然作者用真实状态转移约束 annotator,降低了纯幻觉风险,但对于私有企业软件、IDE 插件、内部网页、权限弹窗等分布,仍需要重新收集轨迹并验证 error taxonomy 是否覆盖。
第四,single-run 结果要谨慎。 GUI benchmark 的环境随机性很高。尤其 WebArenaLitev2、真实网页与桌面 VM 都可能受加载、网络、UI drift 影响。若要工程采用,至少要复测多随机种子、多环境快照、多 step budget,以及 failure replay。
6.3 可复现/可落地建议
如果我要复现这篇论文的价值,不建议一开始训练 8B critic。更务实的路线是:
- 先做 visual marker pre-check:在 agent 执行动作前,把坐标标在截图上,要求一个轻量 VLM 判断落点元素、动作类型、是否被弹窗/加载态阻挡。
- 维护 macro-action summary:每步执行后用小模型生成“已完成/已失败/下一步约束”,不要把完整截图历史无限塞进上下文。
- 建立 failure taxonomy:把失败归类为坐标偏移、控件不可交互、前置条件缺失、时序过早、终止过早、参数错误、权限阻挡等,并把类别写入 trace。
- 用 deterministic replay 评估 critic:不要只看成功率,要看 critic 是否误杀正确动作、是否放过危险动作、是否导致循环。
7. 对 macOS 研发效率工具 / GUI 自动化的启发
对 macOS 研发效率工具来说,HiViG 最值得借鉴的不是模型参数,而是执行架构:policy 负责提出动作,critic 负责执行前审计,runtime 负责权限边界与可回放。
可以落到几个具体设计:
- Xcode / IDE 自动化:执行“点击 Run”“修改 Scheme”“删除 DerivedData”前,critic 必须检查当前窗口、按钮状态、目标项目名、是否有未保存文件。
- Terminal + GUI 混合工作流:当 agent 准备点击 GUI 按钮或运行 destructive command 时,macro-history 应记录已执行命令、当前 git branch、工作区 dirty 状态。
- 桌面自动化 trace:每一步保存 screenshot、accessibility tree、action JSON、critic verdict、落点截图 crop、状态变化摘要,便于失败复盘。
- 权限与安全:对发送邮件、删除文件、提交 PR、发布构建等动作设定更高等级的 pre-execution critic + human approval,而不是所有动作同权。
- 抗 UI 漂移:不要把坐标当长期知识。坐标只应是当前截图上的一次性执行参数;长期记忆应记录语义目标、窗口状态和验证条件。

图 10:非常典型的桌面 agent 失败:文本意图正确,但坐标落在相邻控件。对 macOS 自动化尤其危险,因为菜单、工具栏、侧边栏密集且会随窗口大小变化。
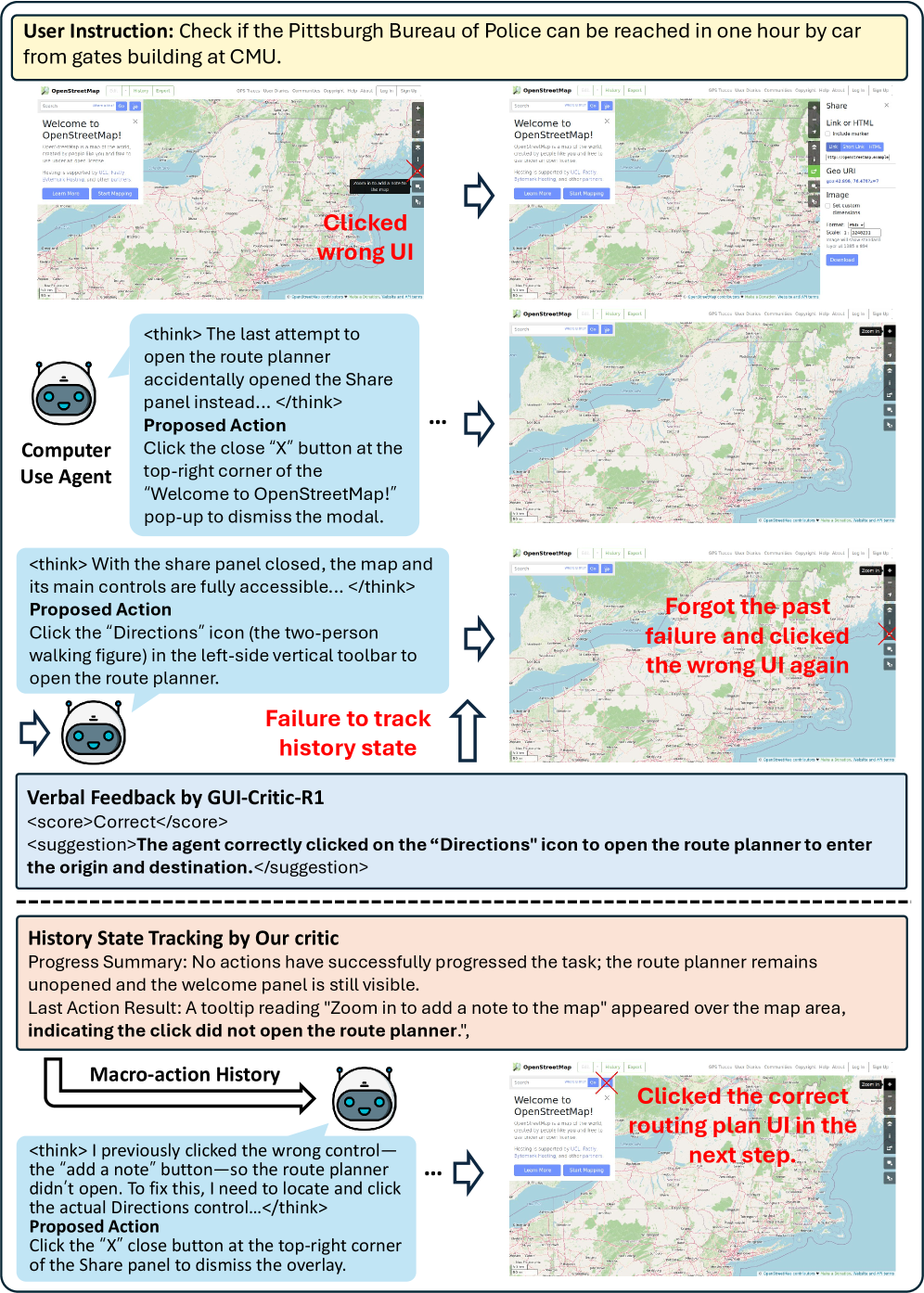
图 11:长程任务中,历史不是“上一步动作列表”,而是“哪些尝试已经失败”。这对调试、构建、网页表单、IDE 配置都非常关键。
8. 局限性与未来方向
HiViG 给出了一个很强的方向,但还没有解决全部 GUIAgent 可靠性问题。
首先,它仍然依赖截图级视觉理解。在高 DPI、复杂表格、虚拟列表、动态 canvas、远程桌面压缩画面中,视觉 marker 可能帮助定位,但不能替代 accessibility tree / DOM / app API。真实生产系统更可能采用 screenshot + AX tree + DOM + CLI/API 的混合 grounding。
其次,critic 的拒绝策略需要产品化。如果 critic 判断动作有风险,应该让 policy 改写,还是让用户确认,还是回滚到上一个安全状态?论文侧重 benchmark 成功率,没有展开审批流、权限分级、审计日志这些部署问题。
第三,错误合成与真实失败之间仍有差距。论文的 12 类错误 taxonomy 很实用,但企业软件里的失败还包括账号权限、缓存状态、网络代理、版本差异、插件冲突、跨应用剪贴板污染等。这些需要在本地 trace 中持续扩充。
最后,test-time scaling 的成本需要被显式纳入 benchmark。未来 GUI agent benchmark 不应只报告 success rate,还应报告平均 step、critic 调用次数、token/图像成本、端到端延迟、误拦截率和危险动作漏检率。
9. 参考链接
- 论文:A History-Aware Visually Grounded Critic for Computer Use Agents
- HTML:https://arxiv.org/html/2606.11078
- 代码:https://github.com/G-JWLee/HiViG
- 相关基准:WebArena / VisualWebArena / WebArenaLitev2、AndroidLab / AndroidWorld、WindowsAgentArena、OSWorld、DeskCraft、MacArena
- 相关方向:GUI grounding、process reward model、verbal critic、test-time intervention、trajectory replay、desktop automation safety
一句话总结:HiViG 真正推进的是 GUI agent 的执行前可靠性:让 critic 既记得长程进度,又检查真实屏幕落点。它不是通用桌面 agent 的终局答案,但对构建可审计、可恢复、低事故率的 macOS computer-use agent,非常值得复现其中的 visual marker、macro-history 和 failure taxonomy 三个设计。