Orchard:开源 GUI Agent 训练不缺 Harness,缺的是可扩展的环境层
解析 arXiv 2026 论文 Orchard:一个面向 SWE、GUI/browser navigation 和个人助理任务的开源 agentic modeling 框架,以及它对 GUI agent 训练基础设施的启发。
目录
- 为什么这篇论文值得 GUIAgent 领域关注
- 背景与问题定义:开源 agent 训练为什么卡在环境层
- Orchard 的核心方法拆解
- Orchard-GUI:从 29 万任务到 4B GUI agent
- 实验结果与可信度评估
- 专家点评:真正贡献、被高估部分、工程落地建议
- 对 macOS 研发效率工具 / GUI 自动化的启发
- 局限性与未来方向
- 参考链接
1. 为什么这篇论文值得 GUIAgent 领域关注
今天选读的是 2026 年 5 月 21 日 arXiv v2 版本的 Orchard: An Open-Source Agentic Modeling Framework。
- 论文地址:https://arxiv.org/abs/2605.15040
- HTML:https://arxiv.org/html/2605.15040v2
- GitHub:https://github.com/microsoft/Orchard
- Hugging Face Dataset:https://huggingface.co/datasets/microsoft/Orchard
- 作者:Baolin Peng、Wenlin Yao、Qianhui Wu、Hao Cheng、Xiao Yu、Rui Yang、Tao Ge、Alessandro Sordoni、Xingdi Yuan、Yelong Shen、Pengcheng He、Tong Zhang、Zhou Yu、Jianfeng Gao
- 机构:Microsoft Research、Columbia University、UIUC
我选择这篇论文,不是因为它只做了一个新的 web agent benchmark 分数,而是因为它切中了 GUI agent / computer-use agent 的一个底层问题:开源社区不只缺模型,也缺能稳定支撑轨迹蒸馏、在线 rollouts、强化学习和评测复用的环境基础设施。
过去很多 GUI agent 工作把重点放在 harness:怎么让模型看截图、怎么组织 ReAct prompt、怎么定义 click / type / scroll 工具、怎么把浏览器或桌面暴露给模型。这当然重要,但如果目标是训练真正的 computer-use agent,harness 只是表层。更深的问题是:如何低成本启动成百上千个隔离环境?如何把同一批环境用于数据采集、SFT、RL 和评测?如何避免每个任务域都重新写一套 sandbox 生命周期管理?如何把 agent 训练从“一次 demo”变成可重复的工程系统?
Orchard 的回答是:把环境层做成一个薄的、Kubernetes-native 的服务,让 agent harness、训练 loop、任务域和推理后端解耦。在此之上,论文展示了三个 recipe:软件工程的 Orchard-SWE、浏览器/GUI navigation 的 Orchard-GUI,以及个人助理任务的 Orchard-Claw。对 GUIAgent 领域来说,最值得看的不是“又多了一个工具调用框架”,而是它把 trajectory distillation → curated SFT → on-policy RL → benchmark evaluation 这条链路开源成了一个可扩展范式。
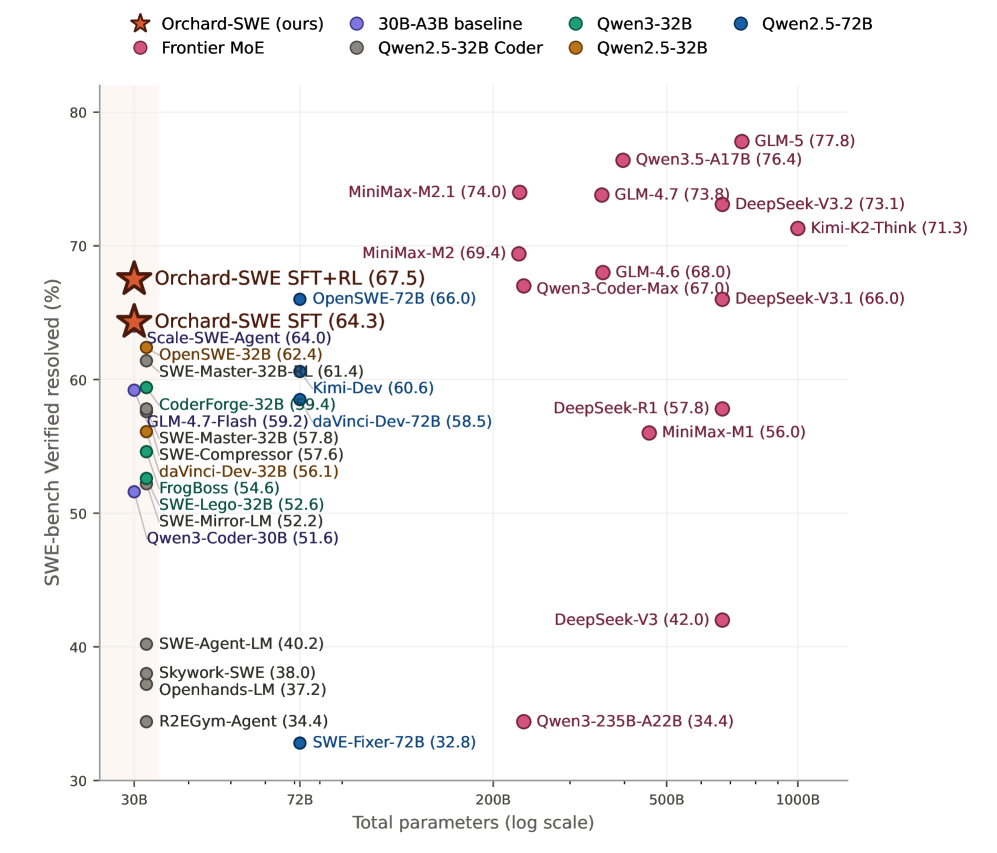
图 1:论文的总体结果。左侧是 Orchard-SWE 在 SWE-bench Verified 上达到 67.5%;右侧是 Orchard-GUI-4B 在 WebVoyager、Online-Mind2Web、DeepShop 三个开放网页任务上达到 68.4% 平均成功率。这里的重点不是单点分数,而是同一个环境层支撑了多个 agent 训练 recipe。
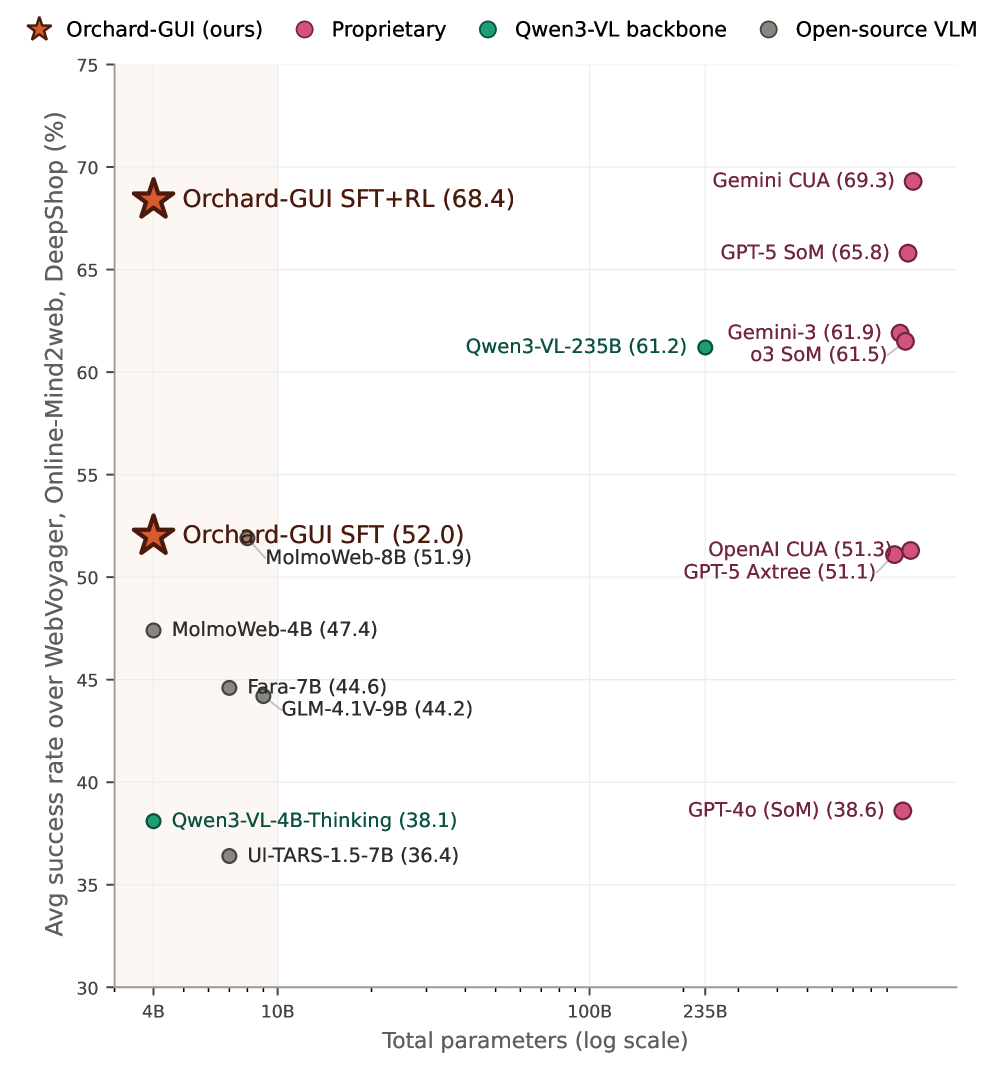
图 1 右半部分单独放大。可以看到 Orchard-GUI-4B 在 30-step setting 下平均成功率达到 68.4%,接近 Gemini computer-use-preview 的 69.3%。但这里也要注意横向比较的前提:不同系统的 step budget、观察格式和工具接口并不完全一致,不能简单理解成“4B 模型全面等价闭源桌面 agent”。
2. 背景与问题定义:开源 agent 训练为什么卡在环境层
GUI agent 和 computer-use agent 的训练比普通指令微调难很多,因为它不是静态输入输出映射,而是闭环交互问题。一个样本往往包含:初始任务、环境状态、截图或 DOM / accessibility 信息、动作、环境反馈、后续状态、终止判断、最终 reward。要把这些样本规模化,需要三件事同时成立。
第一,环境必须可重复、可隔离、可并行。浏览器任务会遇到登录态、缓存、网络、captcha、网站 A/B 测试;桌面任务会遇到文件系统状态、应用版本、窗口位置、权限弹窗。没有隔离和重置机制,训练数据很快就会被脏状态污染。
第二,轨迹采集必须和训练解耦。如果所有环境控制逻辑都写死在某个 harness 里,那么换一个模型、换一个训练算法、换一个任务域都要重写大量 glue code。结果是每篇论文都有自己的“私有 agent stack”,很难复现和比较。
第三,RL 需要大量在线 rollout。SFT 可以离线训练,但 GUI agent 真正的难点是长程执行、错误恢复和最终验收。这些能力需要在环境里反复试错。没有便宜、稳定、可观测的 sandbox 服务,所谓 online RL 往往只能停留在小规模实验。
这也是 Orchard 的问题定义:不是再发明一个单独的 browser-use harness,而是提供一个通用环境层,让不同任务域、不同 harness、不同训练阶段共享同一组 sandbox 生命周期管理能力。
3. Orchard 的核心方法拆解
Orchard 的核心是 Orchard Env。论文把它设计成一个薄的环境服务,而不是全家桶式 agent 平台。它主要提供几类原语:sandbox 生命周期、命令执行、文件 I/O、网络策略、REST API,以及轻量级 agent injection。
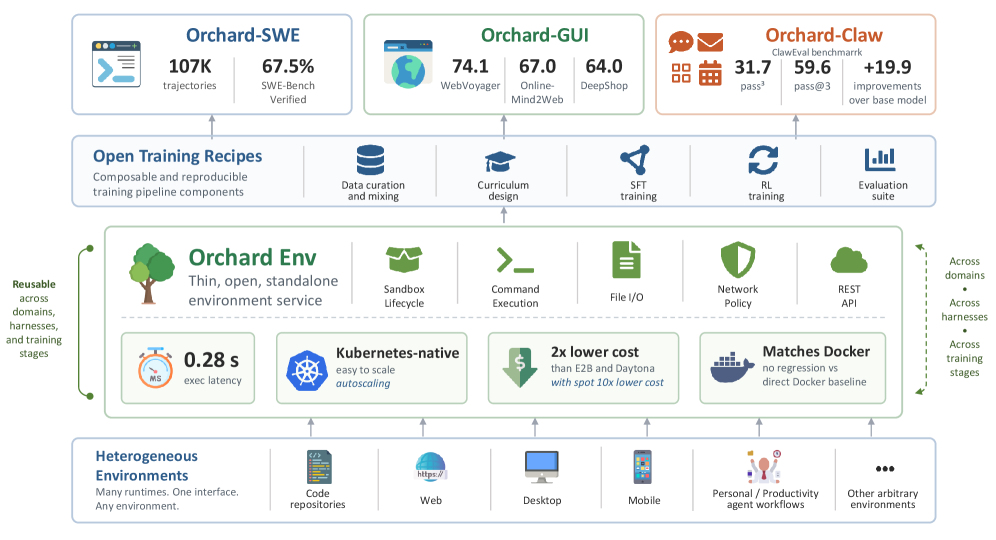
图 2:Orchard 的结构。中间的 Orchard Env 负责 sandbox lifecycle、command execution、file I/O、network policy 和 agent injection;上层 recipe 可以分别服务 SWE、GUI/browser navigation 和个人助理任务。对 GUI agent 工程来说,这种“薄环境层 + 可替换 harness + 可复用训练 recipe”比单个 prompt 框架更重要。
几个设计点值得注意。
首先是 agent injection via init containers。Orchard 不要求每个任务镜像都预装特定 agent runtime,而是通过 init container 把自包含 Python runtime 和 agent server 放进共享 volume。这样可以降低任务镜像改造成本,也更容易把同一个环境服务接到不同任务域。
其次是 hot path 绕开 Kubernetes API server。Pod 创建和删除走 Kubernetes API 是合理的冷路径;但每一步动作执行、文件读写、健康检查如果都通过 API server 或 kubectl exec,大规模 rollout 时控制面会成为瓶颈。Orchard 选择让 orchestrator 直接通过 Pod IP 访问 sandbox 内部 agent,把高频执行请求从控制面移开。
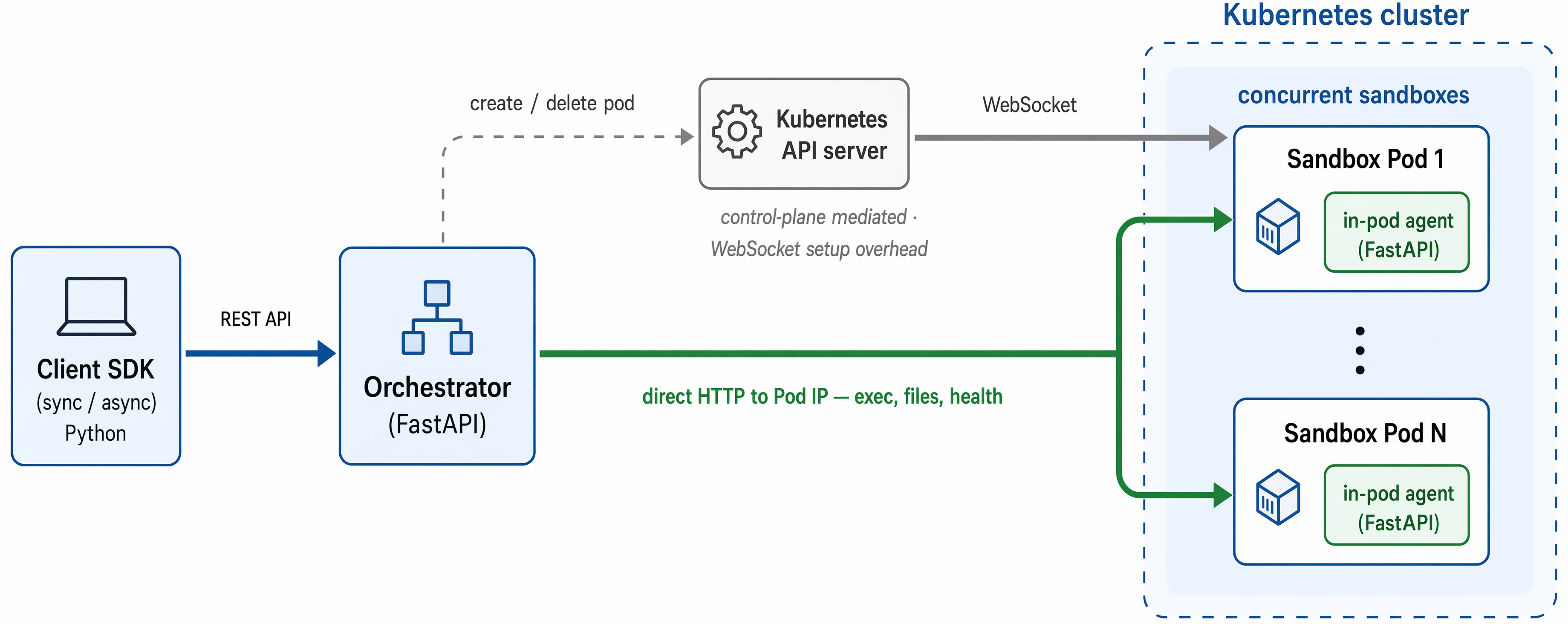
图 3:Orchard Env 的系统架构。客户端通过 REST API 找 orchestrator 管理 sandbox 生命周期;创建/删除 pod 是冷路径,仍走 Kubernetes API server;执行命令、文件读写、健康检查等高频动作则直连 sandbox pod 内的 agent。对 GUI agent 训练来说,这张图解释了为什么环境层不是“脚本启动浏览器”那么简单,而是直接影响 rollout 成本、延迟和稳定性。
第三是 网络隔离和生命周期清理。论文强调 default-deny egress、按需 NetworkPolicy、异步生命周期、heartbeat cleanup 和 watch-based readiness。这些听起来像 DevOps 细节,但对 computer-use agent 特别关键:agent 能操作浏览器、文件和工具,一旦没有网络和权限边界,训练环境既不安全,也不可复现。
第四是成本。论文给了一个 128 个并行 sandbox、每个 2 vCPU / 8 GiB、运行 240 小时的估算:Orchard on-demand 约 $3,362,E2B / Daytona 各约 $7,078,Modal 约 $10,305;如果用 spot instance,Orchard 相对 Daytona 的成本可到约 0.10×。这些数字不一定能直接迁移到每个团队的云账号,但说明一个趋势:GUI agent 的训练竞争正在从“会不会写 harness”转向“能不能负担大规模、可控的环境采样”。
4. Orchard-GUI:从 29 万任务到 4B GUI agent
和 GUIAgent 领域最相关的是 Orchard-GUI。它不是桌面 OSWorld 式 agent,而是浏览器/网页 GUI navigation agent;动作空间包括 13 个原子工具:click、hover、drag、write、press_keys、scroll、goto_url、go_back、wait、new_tab、switch_tab、close_tab、done(response)。
这套动作空间说明 Orchard-GUI 仍然是 browser-centric 的 computer-use agent,不等同于真实 macOS 桌面 agent。但它依然有代表性,因为浏览器任务具备 GUI agent 的几个核心难点:视觉观察、多步动作、动态页面、长程状态、外部网站不稳定性、captcha 和最终结果验证。
论文的数据管线很值得拆开看。
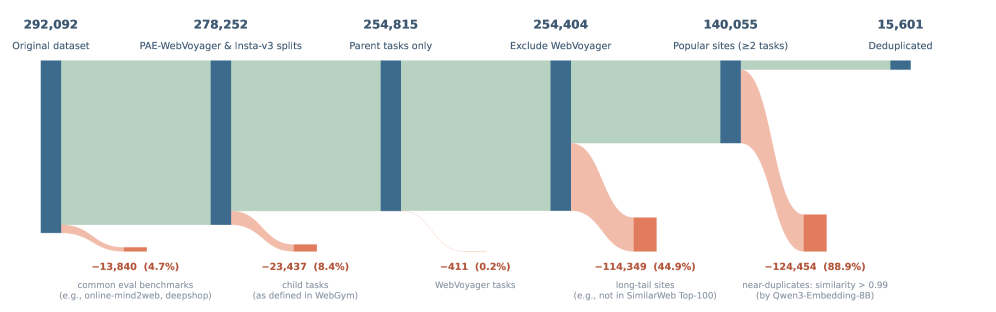
图 4:Orchard-GUI 的 task-filtering pipeline。它从 WebGym 的 292,092 个 raw tasks 出发,依次去掉评测重叠、child tasks、WebVoyager contamination、长尾网站和近重复 intent,最后得到 15,601 个 seed tasks。这张图很关键,因为 GUI agent 的训练质量很大程度取决于“任务池是否干净、是否泄漏 benchmark、是否覆盖真实网站”。
它从 WebGym 的 292,092 个任务开始,经过 5 阶段过滤:去掉评测 benchmark overlap、去掉 child tasks、去掉 WebVoyager contamination、去掉长尾网站、去掉近重复 intent。最后得到 15,601 个去重 seed tasks,覆盖 13,063 个 host,覆盖 85.0% 的 MOZ Top-500 和 57.0% 的 SimilarWeb Top-100。
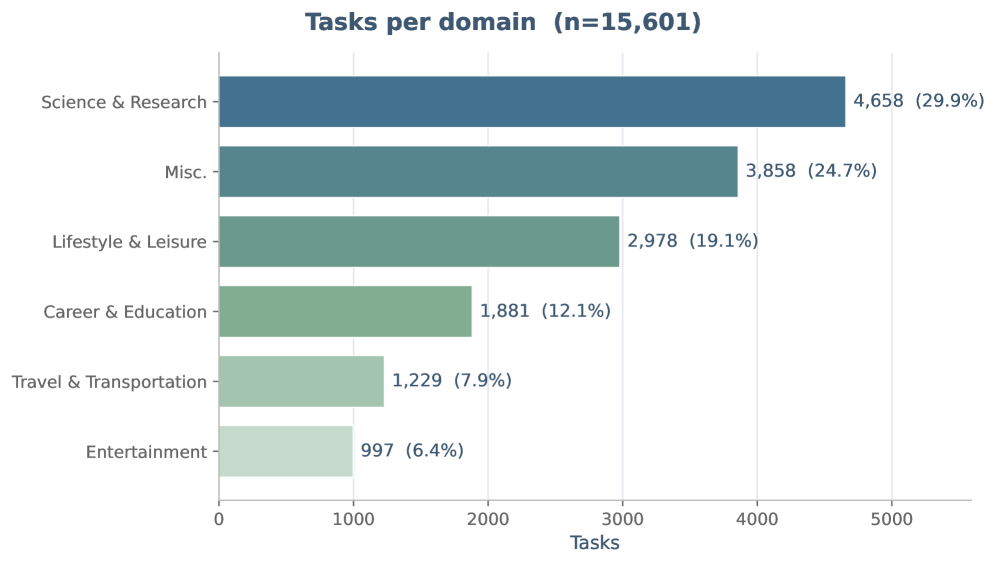
图 5:过滤后 15,601 个任务的领域分布。Science & Research、Misc、Lifestyle & Leisure、Career & Education 等类别占比较高,说明 Orchard-GUI 不只是少数购物/搜索模板任务,而是试图覆盖更广的开放网页使用场景。
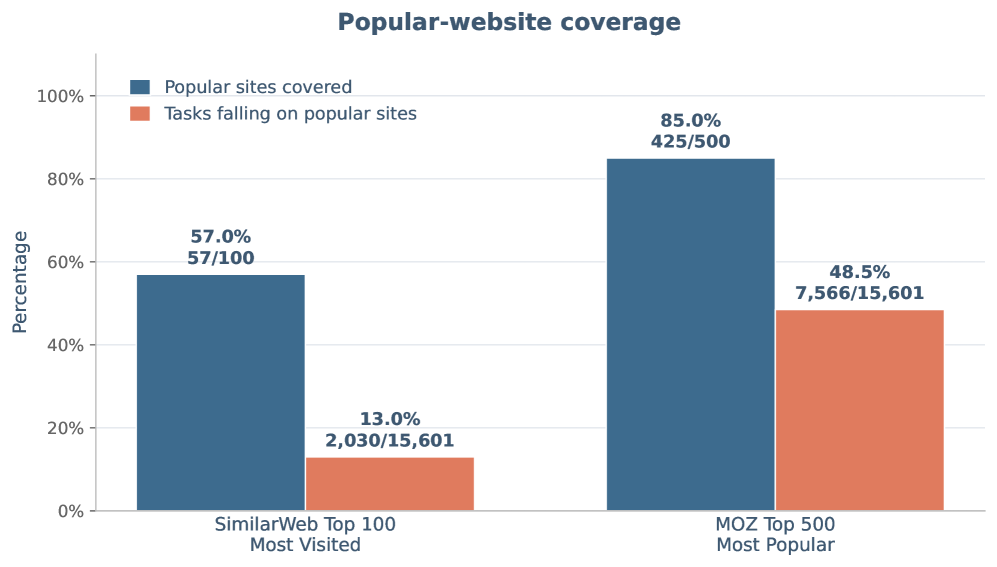
图 6:热门网站覆盖率。任务池覆盖 SimilarWeb Top-100 中的 57.0% 和 MOZ Top-500 中的 85.0%,但落在这些热门网站上的任务占比分别是 13.0% 和 48.5%。这说明它既覆盖头部网站,也保留了大量长尾网页任务;这是开放 web agent 泛化能力评估中很重要的分布信息。
接着用 Qwen3-VL-235B-A22B-Thinking 做 teacher,每个任务 4 次 rollout,得到 62,395 条 raw rollouts,再用 GPT-4.1 做 judge。结果本身就暴露了真实 web GUI 的复杂度:
- 68.4% 的任务至少有一次通过;
- 26.3% 的任务四次都通过;
- 31.6% 的任务四次都失败;
- 在 4,934 个 all-fail tasks 里,2,026 个(41.1%) 是四次都被 captcha 阻断,占全量任务 13.0%。
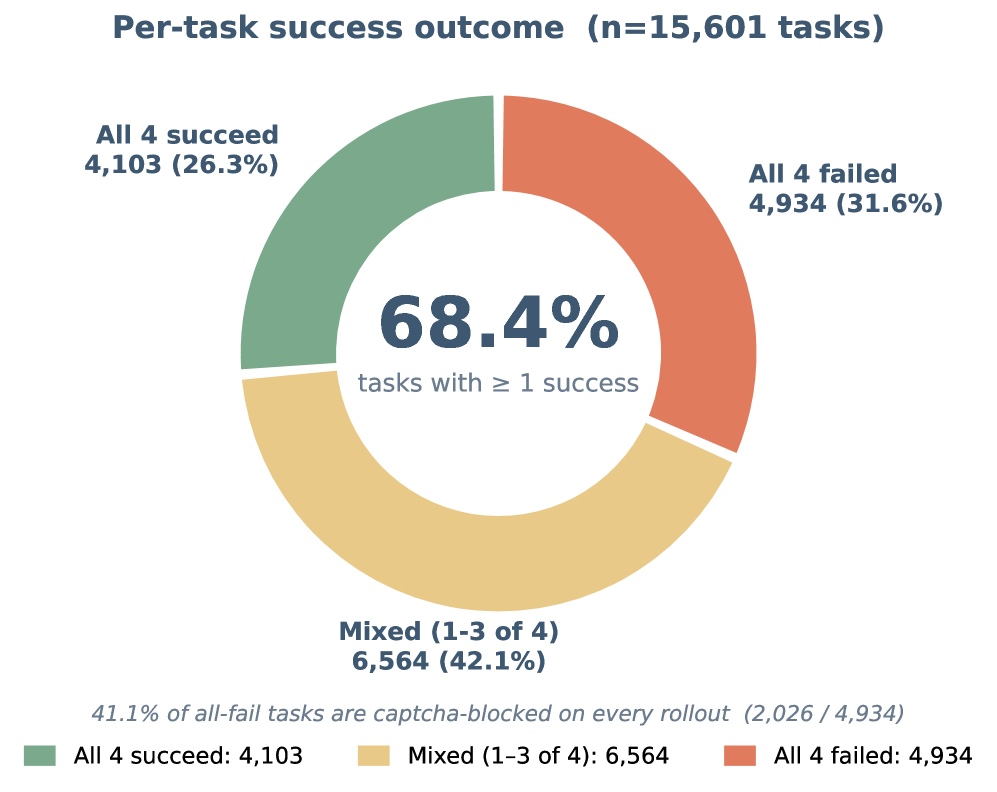
图 7:teacher rollout 的真实结果分布。最值得注意的是,不只是模型会失败,真实网站本身也会通过 captcha、登录、动态页面等机制让任务不可直接自动化。把这些样本一概当作噪声过滤掉,会高估 GUI agent 的真实部署能力。
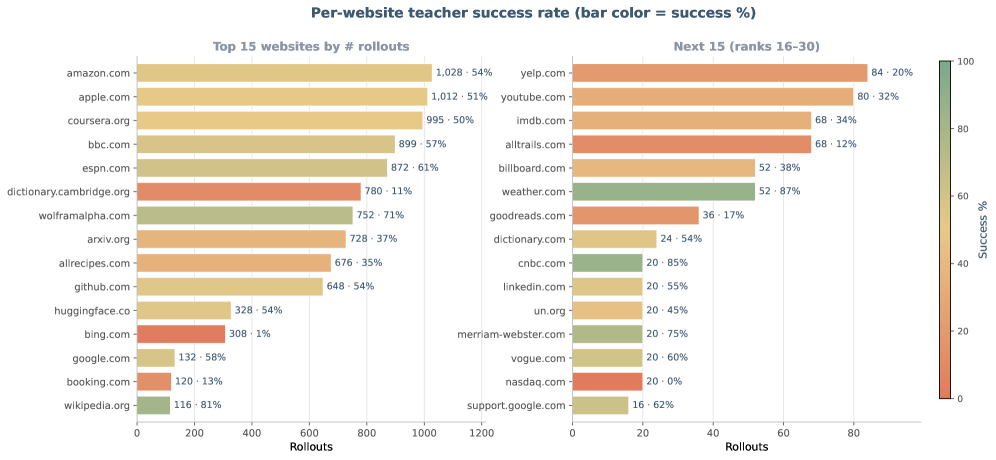
图 8:按网站拆分的 teacher success rate。条长表示 rollout 数量,颜色表示成功率。这个图对工程落地很有启发:同一个 agent 在不同网站上的失败率可能完全不同,网站级策略、反自动化机制、页面复杂度和账号状态都会显著影响 computer-use agent 的可用性。
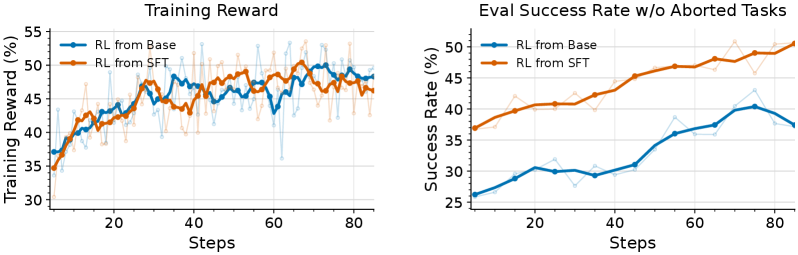
图 9:Orchard-GUI 的 RL training / evaluation curve。红色曲线从 SFT checkpoint 初始化,蓝色从 base model 初始化。论文的经验结论是,小规模高质量 SFT 不只是提高初始分数,也能让后续 RL 更稳定。
这里有一个反直觉但重要的选择:SFT 没有直接吃下所有成功轨迹,而是只保留一个很小的 curated subset:最终 412 个任务、70 个网站。原因是作者担心过度模仿 teacher 的长轨迹和坏习惯,选择先用短、干净、去重的成功轨迹建立基础行为,再用 2,198 个 RL tasks 做 rollout-based optimization。
训练对象是 Qwen3-VL-4B-Thinking。SFT 冻结视觉编码器和 multimodal projector,只更新 LM weights,3 epochs,peak LR 1e-5,global batch 128。RL 使用多轮 GRPO,reward 规则相对简单:动作格式有效且最终 done(response) 成功为 +1,重复格式失败为 -1,否则为 0,并配合 15 步到 30 步的课程式 step budget。
站在 GUIAgent 训练角度,这个 recipe 的价值在于它把几种经验连成了一条闭环:大模型 teacher 生成轨迹,小模型只吃高质量少量 SFT,随后用环境在线 rollout 和 judge reward 做能力提升。它不是纯 imitation,也不是从零 RL,而是更符合当前 GUI agent 的现实:先教会工具语法和基本网页行为,再让模型在可控环境中学习任务完成。
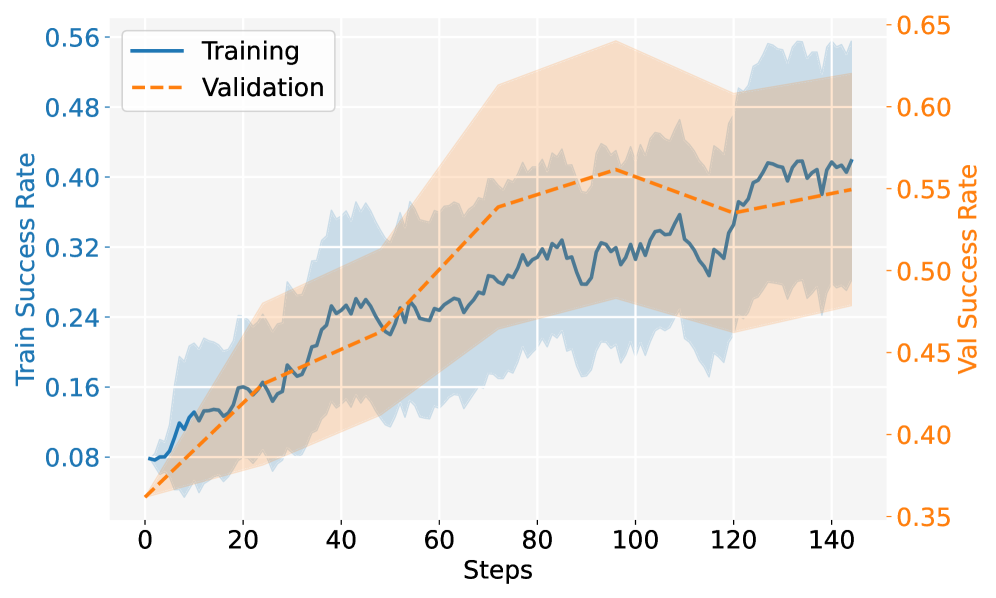
图 10:Orchard-Claw 的 RL success-rate curve。虽然本文重点讨论 GUI/browser agent,但这张图说明 Orchard 的环境层不是只为网页点击服务,也能支撑 email、calendar、daily tool-use 这类个人助理工作流。
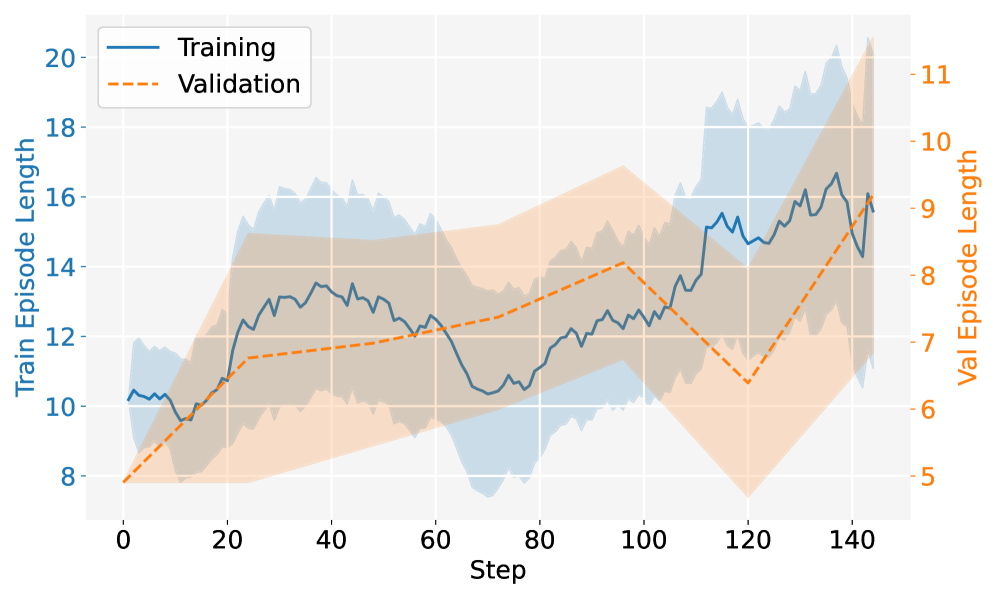
图 11:Orchard-Claw 的 episode length curve。成功率上升的同时,episode length 也上升,说明 agent 不只是更快结束,而是能支撑更长的多轮工具使用过程。对 macOS 研发效率工具来说,这意味着同一套轨迹和环境基础设施可以覆盖 IDE、终端、浏览器、文档和消息工具。
5. 实验结果与可信度评估
论文报告 Orchard-GUI-4B 在 30-step setting 下达到:
- WebVoyager:74.1%
- Online-Mind2Web:67.0%
- DeepShop:64.0%
- 平均:68.4%
对比表里,Gemini computer-use-preview 在 100-step setting 下平均 69.3%,GPT-5 + SoM 100-step 平均 65.8%,OpenAI computer-use-preview 100-step 平均 51.3%。开源模型里,MolmoWeb-8B 平均 51.9%,Fara-7B 平均 44.6%,UI-TARS-1.5-7B 平均 36.4%。因此作者称 Orchard-GUI-4B 是强开源 GUI agent,并且在这些 web benchmarks 上接近 proprietary computer-use systems。
这些结果值得重视,但也要谨慎解读。
首先,它证明的是 open-web/browser navigation 能力,而不是完整桌面 computer-use 能力。WebVoyager、Online-Mind2Web、DeepShop 都非常重要,但它们仍然比真实桌面自动化少了很多因素:多应用切换、本地文件、权限弹窗、菜单栏、快捷键冲突、窗口遮挡、高 DPI 缩放、长时间软件状态漂移等。把 Orchard-GUI 直接等同于 OSWorld 或 DeskCraft 风格桌面 agent,会高估它的外推能力。
其次,reward 依赖 judge 和 benchmark success definition。论文用 GPT-4.1 判断 teacher rollout 成功,RL reward 也围绕最终 done(response) 是否成功。这是当前 web agent 训练的实用方案,但会引入 judge 偏差、网站任务表述偏差,以及“模型学会迎合 benchmark 终止条件”的风险。尤其当任务涉及购物、搜索和网页信息抽取时,最终回答的可验收性未必等价于真实用户目标完成。
第三,30-step 与 100-step 的比较要谨慎。Orchard-GUI 在 30-step 下表现强,说明它的路径效率和训练质量不错;但不同系统的 step budget、工具定义、观察格式、是否使用 SoM / Axtree / screenshot-only、是否允许额外结构化信息,都会影响横向公平性。
第四,captcha 不是噪声,而是真实部署信号。15,601 个任务中有 13.0% 在 teacher 四次 rollout 中全部被 captcha 阻断。很多论文会把 captcha 当作要过滤掉的异常,但从 product engineering 看,这正是 computer-use agent 进入真实网页世界必须面对的边界:什么时候停止、什么时候请求用户介入、如何处理账号、权限和反自动化机制。
总体上,我认为 Orchard-GUI 的结果可信地说明:在开放网页任务上,小模型 + 高质量轨迹蒸馏 + 环境中 RL 可以显著提升 computer-use agent;但它还不能证明同样 recipe 能无缝迁移到 OS-level desktop agent。
6. 专家点评:真正贡献、被高估部分、工程落地建议
真正贡献
第一,Orchard 的真正贡献是把 agent training 的环境层做成可复用基础设施。GUIAgent 领域过去很容易把论文贡献局限在 model、prompt 或 benchmark 上,但如果没有稳定环境服务,RL、轨迹采集、评测复现都很难规模化。Orchard Env 给出的是一种“薄环境层”的工程范式。
第二,Orchard-GUI 展示了一个务实训练 recipe:大模型 teacher 采样、多轮 rollout、judge 过滤、小规模 curated SFT、再接 on-policy RL。这个 recipe 对 GUI agent 比“堆更多 SFT 数据”更有启发,因为 GUI 轨迹里充满冗余动作、失败尝试和网站特定习惯,盲目 imitation 容易学到噪声。
第三,论文把 SWE、GUI、personal assistant 三类 agent 放在同一个基础设施下。这说明 computer-use agent 的边界正在变得模糊:代码 agent、web agent、桌面 agent、个人助理 agent 共享很多环境需求,例如 sandbox、文件系统、网络策略、工具调用、轨迹记录和最终验收。
可能被高估的部分
第一,标题里的 “Agentic Modeling Framework” 容易让人误以为它已经解决通用 GUI agent 训练。实际上 Orchard-GUI 主要是 browser navigation,不是完整 desktop GUI。它和 OSWorld、AndroidWorld、DeskCraft、UI-Vision 这些强调真实 OS / mobile / desktop 状态的工作处在不同层级。
第二,68.4% 平均成功率很亮眼,但 benchmark 组合仍然偏 web。WebVoyager、Online-Mind2Web 和 DeepShop 能测试网页导航、信息查找和购物流程,但不能充分测试专业桌面软件、跨 App 文件流、系统权限、低层 OS 操作和长程产物验收。
第三,环境层的 Kubernetes 方案对研究机构和大团队很有吸引力,但对个人开发者或小团队可能过重。论文证明的是“可扩展训练基础设施”的方向,不意味着每个 macOS 自动化产品都应该直接上 K8s。
第四,judge reward 和数据过滤可能隐藏了 benchmark-specific bias。使用 GPT-4.1 判断成功、过滤任务、筛选轨迹是现实选择,但也会让模型优化到 judge 偏好的行为风格。对于真实生产工具,更可靠的 reward 应该尽量来自可执行检查:文件 diff、UI state、测试结果、数据库状态、日志和用户确认。
可复现 / 可落地建议
如果要复现 Orchard 的价值,我不建议从完整 K8s 集群开始,而建议先复现它的三条原则:
- 环境层和 harness 解耦:把浏览器 / 桌面 / 终端环境控制封装成服务,训练逻辑只通过统一 API 获取 observation、执行 action、读取文件和重置状态。
- 轨迹要保留失败和中间证据:不要只存成功 trace。失败 trace 对 reward modeling、error recovery 和安全策略同样重要。
- SFT 小而干净,RL 多而可验证:先用少量高质量轨迹教会动作语法和基本策略,再用可执行 reward 或 verifier 做在线优化。
7. 对 macOS 研发效率工具 / GUI 自动化的启发
如果目标是做 macOS 研发效率工具,Orchard 的启发非常直接:不要把 GUI agent 产品做成一个 monolithic bot;要把它拆成环境层、动作层、轨迹层、验证层和策略层。
环境层负责启动和隔离工作区。对 macOS 来说,这未必是 Kubernetes pod,可能是临时 workspace、浏览器 profile、Xcode / VS Code 项目副本、模拟器、Docker 容器、沙盒目录、或者一个可重置的应用状态快照。关键是每次任务要能记录初始状态、执行动作、回滚或清理。
动作层要混合使用 GUI、Accessibility、CLI、API 和 MCP。Orchard-GUI 的 13 个浏览器动作很干净,但真实 macOS 工具不能只靠 click。改代码、跑测试、查日志、改配置应该优先用 CLI / API;只有当应用没有稳定接口、需要视觉判断或跨 App 协调时,才退到 GUI 操作。这样既快,也更安全。
轨迹层要把每一步 observation、action、reasoning、工具返回、截图、文件 diff 和最终状态都记录下来。没有轨迹,agent 失败后就无法复盘;没有可复盘,就无法做 reward modeling、回归测试和用户信任。
验证层要尽量 deterministic。对于研发效率场景,好的 reward 不应该主要来自 LLM judge,而应该来自:测试是否通过、构建是否成功、文件 diff 是否符合预期、截图前后是否变化、目标窗口是否存在、日志是否出现指定事件、PR 检查是否绿。LLM 可以辅助解释,但不应该是唯一验收者。
策略层要处理权限和人机协作。Orchard 提到 network policy 和 sandbox isolation,这对 macOS agent 同样重要。比如:删除文件、提交代码、发送消息、访问凭证、修改系统设置,都应该有明确 policy gate 和用户确认。真正可用的 computer-use agent 不是“全自动乱点”,而是“在可观测边界内自动,在高风险边界前停下来”。
8. 局限性与未来方向
Orchard 最明显的局限是 GUI 部分仍偏浏览器场景。下一步如果要更贴近 GUIAgent 全领域,需要把同样的环境层思想扩展到 OSWorld / AndroidWorld / DeskCraft / UI-Vision 这类更真实的系统环境和桌面专业软件任务中。
第二个局限是 reward 仍然比较粗。done(response) 成功给 +1 的 RL 规则足够简单可用,但对长程 GUI 任务来说,中间过程 reward、错误恢复 reward、风险动作惩罚、用户澄清质量都还没有充分建模。这也是 StainFlow、VeriGUI、process reward model 等方向继续有价值的原因。
第三个局限是复现门槛。Orchard 开源了框架和数据,这是好事;但要完整复现 128+ sandbox 并行、teacher rollout、judge filtering、SFT 和 RL,仍然需要相当的云资源、工程经验和模型训练能力。它更像是给研究社区和基础设施团队的一套参考架构,而不是开箱即用的小工具。
未来我希望看到三类延伸。
第一,把 Orchard Env 接入更真实的桌面环境,让同一套环境服务管理 Linux desktop、macOS automation sandbox、Android emulator 和 browser profiles。
第二,把 reward 从 LLM judge 扩展到多源 verifier:文件 diff、UI tree diff、截图检测、测试结果、日志事件、业务 API 状态和人类审批。
第三,把训练数据和产品 telemetry 打通。真实 macOS 研发效率工具每天都会产生大量“用户目标—agent 行动—验证结果—失败原因”的轨迹,如果能在隐私和权限边界内沉淀成训练/评测数据,它比通用网页任务更能提升垂直场景 agent。
9. 参考链接
- Orchard: An Open-Source Agentic Modeling Framework:https://arxiv.org/abs/2605.15040
- arXiv HTML:https://arxiv.org/html/2605.15040v2
- GitHub:https://github.com/microsoft/Orchard
- Hugging Face Dataset:https://huggingface.co/datasets/microsoft/Orchard
- WebVoyager、Online-Mind2Web、DeepShop:论文中用于 Orchard-GUI 的开放网页评测基准
- OSWorld、AndroidWorld、DeskCraft、UI-Vision:用于对照真实 OS / mobile / desktop GUI agent 能力边界的相关 benchmark