DeskCraft:桌面 GUI Agent 离真实专业工作流还有多远?
解析 arXiv 2026 论文 DeskCraft:一个覆盖 538 个专业桌面任务、长程工作流和人机协作协议的执行式 GUI Agent 基准。
目录
- 为什么这篇论文值得关注
- 背景与问题定义:桌面 agent 为什么不能只测“点按钮”
- DeskCraft 的核心思路
- 方法设计拆解:任务、难度与交互协议
- 数据构建与执行式评测
- 实验结果与结论
- 对 macOS 研发效率工具和 GUI 自动化的启发
- 局限性与我的点评
- 总结
- 参考链接
1. 为什么这篇论文值得关注
今天选的论文是 2026 年 6 月 2 日提交到 arXiv 的 DeskCraft: Benchmarking Desktop Agents on Professional Workflows and Human-in-the-Loop Collaboration。
- 论文地址:https://arxiv.org/abs/2606.03103
- HTML:https://arxiv.org/html/2606.03103v1
- 项目仓库:论文称将开源于 https://github.com/mrwwk/DeskCraft
- 作者:Wenkai Wang、Tao Xiong、Jingchen Ni、Yunpeng Bao、Xiyun Li、Tianqi Liu、Hongcan Guo、Zilong Huang、Shengyu Zhang
- 机构:浙江大学、清华大学、腾讯、香港大学
这篇论文值得单独写,是因为它把 GUI agent 的评测从“能不能完成一个短任务”推进到了更接近真实桌面工作的场景:专业软件、长程交付、人机协作、执行式验证。
过去很多 desktop / computer-use benchmark 已经证明模型可以看屏幕、点按钮、填表单。但真实工作并不是这样。一个设计师不会只要求 agent “点击导出”;他会要求它修改素材、调整布局、保持工程文件可复用、导出指定格式,并在过程中临时补充需求。一个研发工具也不会只执行单步 GUI 操作,而要跨 IDE、浏览器、终端、文档、设计稿和测试环境完成一条工作流。
DeskCraft 给出的核心判断很直接:即便是当前强模型,在这种更真实的桌面任务上也还远没有“稳”。论文评测了 18 个专有和开源 agent:最佳标准任务成功率是 Kimi-K2.6 的 33.8%,最佳交互任务成功率是 GPT-5.4 的 27.6%;GPT-5.4 在标准任务上是 31.6%,Kimi-K2.6 在交互任务上是 25.7%。这说明桌面 GUI agent 的瓶颈已经不只是视觉 grounding,而是长程规划、状态管理、可验证交付和主动澄清能力。
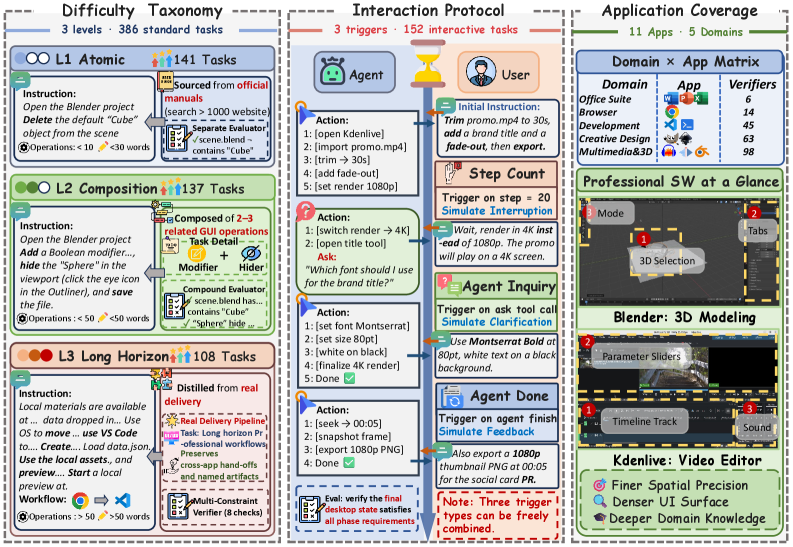
图 1:DeskCraft 的整体设计。左侧是 L1/L2/L3 三层难度的 386 个标准任务,中间是由 step_count、agent_ask、agent_done 三类触发器驱动的 152 个交互任务,右侧覆盖 Writer、Calc、Impress、Chrome、VS Code、GIMP、Inkscape、Kdenlive、Audacity、Blender、UI 生成、多应用和 OS 等桌面场景。
2. 背景与问题定义:桌面 agent 为什么不能只测“点按钮”
图形界面智能体的评测通常面临一个张力:如果任务太短,评测稳定、复现容易,但离真实工作很远;如果任务太真实,又会引入大量环境差异、素材差异和人工判断成本。
DeskCraft 选择正面处理这个张力。论文认为,真实桌面工作流至少有三类特征没有被现有 benchmark 充分覆盖。
第一,任务是长程的。专业工作流常常不是 3 到 5 步,而是几十步甚至超过 50 步。比如在 Blender 里配置场景、材质、相机和渲染参数;在 Kdenlive 里导入素材、剪辑、调整比例、添加标题卡并导出;在 VS Code 里修改项目文件并让页面达到指定效果。每一步都可能改变后续状态。
第二,任务发生在专业软件里。很多 GUI benchmark 更偏浏览器或系统设置,界面元素相对规则。专业软件的 UI 则更密集、更空间化、更状态化:工具栏、面板、时间线、图层、画布、属性窗口、快捷键和隐藏状态都会影响最终结果。对模型来说,这不只是“找按钮”,而是理解软件工作流。
第三,用户需求会在过程中变化。真实协作里,用户可能一开始说得不完整,执行中补充约束,看到结果后要求修改,或者临时打断原计划。一个成熟的 computer-use agent 不能假装所有信息都在第一条指令里,也不能在不确定时一直盲目执行。
因此,DeskCraft 的问题定义不是“模型能否点击正确坐标”,而是:给定一个真实桌面环境、一个可演化的用户目标和一个可执行验证器,agent 是否能交付最终可验收的桌面状态或产物?
3. DeskCraft 的核心思路
DeskCraft 可以理解成三个设计叠在一起。
第一层是 execution-based desktop benchmark。它不是让评审读模型回答,也不是只看过程文本,而是在真实桌面环境里执行操作,并由任务级 evaluator 检查最终状态。比如文件是否存在、导出格式是否正确、文档样式是否满足要求、项目文件是否保存、网页组件是否渲染正确。
第二层是 L1/L2/L3 难度体系。论文不是用表面步数来划分难度,而是按执行能力要求划分:L1 是单个明确操作,L2 是 2-4 个相互依赖的操作,L3 是多个子任务组成的长程交付工作流。这个划分有助于定位失败到底来自基础操作、短链组合,还是长程状态管理。
第三层是 human-in-the-loop interaction protocol。DeskCraft 把交互任务建模为多个 phase,每个 phase 有用户补充消息和触发条件。触发器包括 agent 主动询问、执行到某个步数、agent 宣告完成。这样一来,评测可以复现“用户中途补充需求”“agent 需要主动澄清”“用户在完成后反馈修改”等协作模式,而不是把交互变成不可控聊天。
4. 方法设计拆解:任务、难度与交互协议
论文把一个任务写成:
τ = (s0, u0, Φ, ℰ, R)其中 s0 是初始桌面状态,u0 是初始用户指令,ℰ 是桌面环境,R 是最终评测函数,Φ=(ϕ1,...,ϕK) 是可选的交互阶段序列。每个阶段 ϕk=(uk,gk) 包含一条后续用户消息和一个触发条件。
agent 的动作空间不仅有 GUI 操作,还包含三个关键控制动作:
a_t ∈ A ∪ {DONE, ASK, FAIL}这里 A 是点击、键入、滚动等 GUI 操作;DONE 表示认为任务完成;ASK 表示需要向用户澄清;FAIL 表示无法继续。这个建模很重要,因为它把“何时结束”“何时求助”“何时承认失败”也纳入了 agent 能力,而不仅是屏幕操作。
难度层级方面,DeskCraft 的 L1/L2/L3 很适合工程团队借鉴。
- L1:原子操作。例如修改字号、冻结一行、添加转场、导出 WAV、切换浏览器设置。这类任务主要测感知、定位和基础控件操作。
- L2:小型组合任务。例如在表格中添加公式并排序,修改文档某个段落样式,基于 starter bundle 做一个本地 Web 组件。这类任务开始要求局部规划。
- L3:完整交付工作流。例如在 GIMP 中既导出图像又保存组织良好的 XCF 项目,在 Blender 中同时处理场景、材质、相机和渲染设置。这类任务测的是长程状态管理、跨区域一致性和最终产物交付。
交互协议则由三类触发器构成。
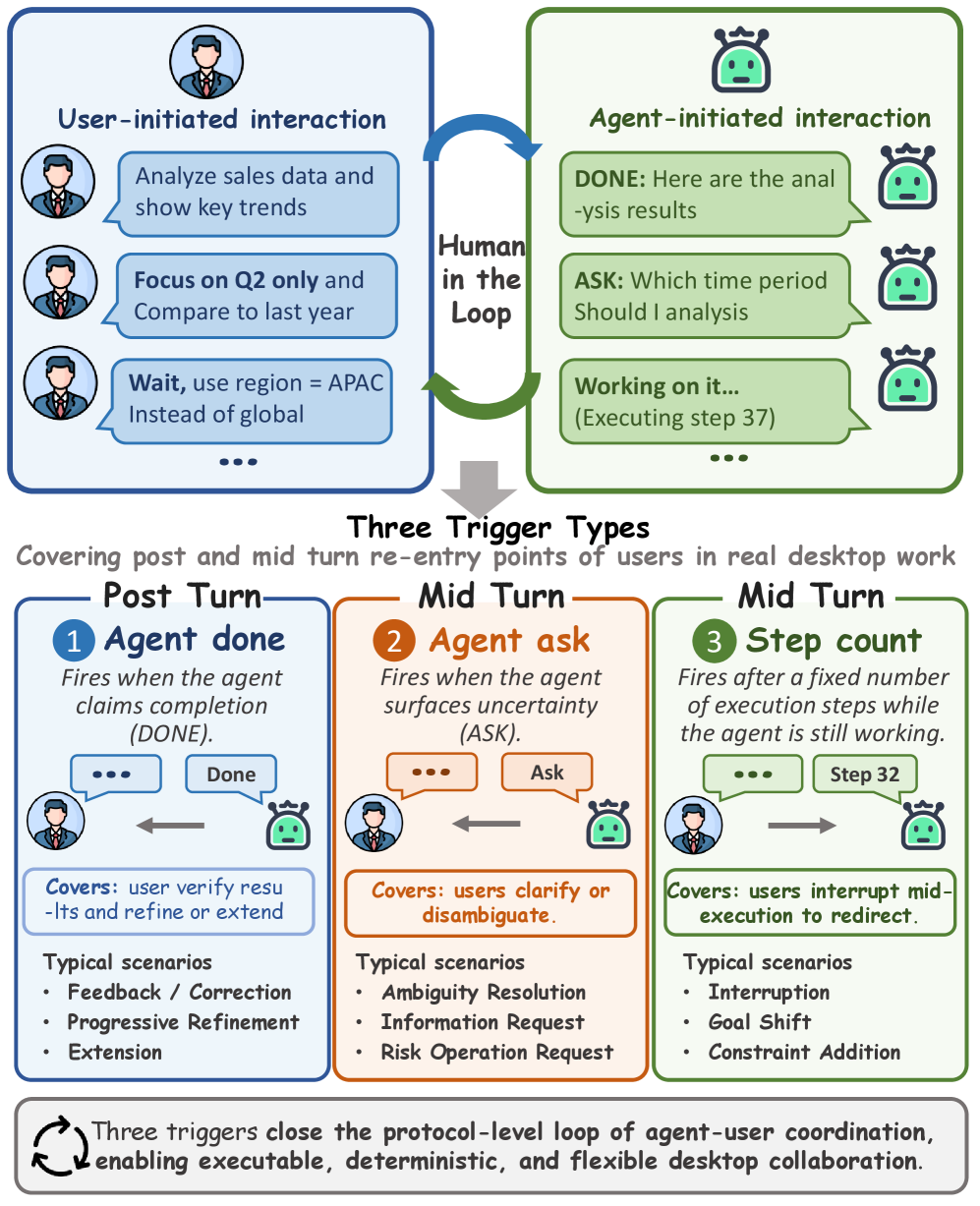
图 2:DeskCraft 的 human-in-the-loop 协议。agent_done 触发完成后反馈,agent_ask 触发用户澄清,step_count 触发执行过程中的用户更新或打断。这个设计让交互评测可复现,而不是依赖随机人工介入。
我觉得这张图的价值不只是 benchmark 设计,也直接提示了产品设计:如果要做一个面向 macOS 研发效率的桌面 agent,必须把“用户何时进入回路”设计成协议,而不是把聊天窗口简单接在 agent 旁边。
5. 数据构建与执行式评测
DeskCraft 总共包含 538 个任务:其中 386 个标准任务、152 个交互任务。它覆盖 11 个应用和一个多应用类别,跨设计、视频、音频、3D、代码和系统操作等领域。
任务来源也比较扎实。论文从 11 个应用的官方文档和在线教程中系统收集工作流,得到 224 个参考来源,形成 120+ 操作类别的能力矩阵。386 个标准任务背后有 300+ evaluator functions,并使用 279 个唯一资源文件,覆盖 19 种文件格式。附录给出的来源分布包括:官方文档 204 个任务,占 52.8%;作者设计工作流 105 个任务,占 27.2%;文本和视频教程 29 个任务,占 7.5%;Web 开发资源 20 个任务,占 5.2%。
这套构建方式有两个值得注意的工程点。
第一,DeskCraft 没有把任务设计成“玩具指令”。L3 任务来自真实专业场景的 workflow distillation:先找真实流程,再拆成自包含任务,明确输入文件和可验证交付物。这样既保留现实复杂性,又能把评测闭环落到自动 evaluator 上。
第二,交互任务不是随意加一句话,而是从 L2/L3 工作流派生出 phase-level user messages。论文覆盖的交互模式包括 progressive refinement、ambiguity / clarification、requirement change、interruption、correction / feedback、workflow 等。也就是说,它测的不是“模型会不会聊天”,而是模型能否在桌面状态已经变化后吸收新的用户要求。
6. 实验结果与结论
DeskCraft 评测了三类 agent:专有 frontier 模型、开源通用 VLM、面向 GUI 使用优化的开源 CUA foundation models。实验问题包括:当前 agent 在标准和交互任务上表现如何,长步数预算能否显著提升成功率,难度上升时性能如何退化,以及 agent 是否能在人机协作中表现稳定。
总体结果并不乐观。
在标准任务上,最佳平均成功率是 Kimi-K2.6 的 33.8%,GPT-5.4 为 31.6%。在交互任务上,最佳平均成功率是 GPT-5.4 的 27.6%,Kimi-K2.6 为 25.7%。这意味着即使最强模型也只能完成大约三分之一的标准专业桌面任务,交互任务则更低。
更有意思的是难度退化。论文报告,随着 L1/L2/L3 难度提高,各模型成功率明显下降,主要 cliff 出现在 L3。比如 EvoCUA-32B 从 L1 的 19.9% 降到 L2 的 10.7%,再降到 L3 的 1.0%。强通用 agent 也没有逃过这个规律:Kimi-K2.6 从 L2 的 41.0% 降到 L3 的 21.6%,GPT-5.4 从 L2 的 40.7% 降到 L3 的 9.5%。
执行长度也随难度上升。Kimi-K2.6 的平均步数从 L1 的 30.8 增加到 L2 的 48.8,再到 L3 的 77.7;GPT-5.4 从 25.0 到 44.3 再到 71.2。这说明困难任务不仅更容易错,而且更容易拖长。长程任务中的每一步都会积累状态误差,一旦 agent 缺少可靠记忆、计划检查和中间验证,就会在后半程失控。
论文还观察到,增加步数预算只能恢复少量成功。也就是说,很多失败不是“再给它一点时间就能好”,而是目标理解、状态跟踪、工具使用、主动澄清和验证闭环本身有缺口。
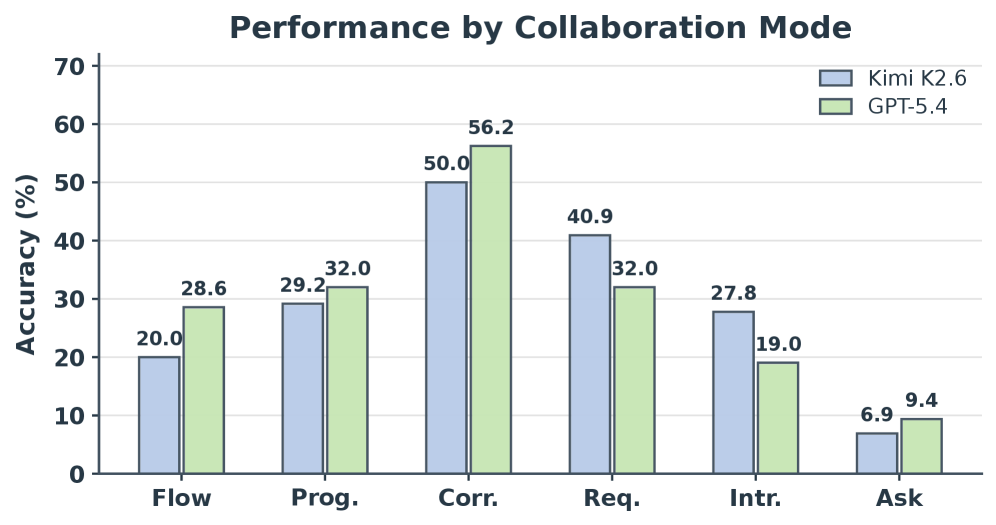
图 8:交互模式下的成功率。DeskCraft 将交互任务拆成 workflow、progressive refinement、correction、requirement change、interruption、clarification 等模式,用来观察 agent 在不同协作形态下的短板。
从产品视角看,图 8 的启发很直接:GUI agent 的“会问问题”不是锦上添花,而是完成真实任务的基本能力。用户需求不完整时不问、用户中途更新时不吸收、完成后反馈时不修正,都会让 agent 看起来像在执行,却不能真正交付。
7. 对 macOS 研发效率工具和 GUI 自动化的启发
我把 DeskCraft 放到 macOS 研发效率工具、桌面自动化和 computer-use agent 场景里看,有几条非常实际的启发。
第一,评测任务要从“操作成功”升级到“交付成功”。 对研发工具来说,点击 Xcode 按钮、打开 Simulator、切换 Finder 目录都只是中间动作。真正要评测的是:项目是否构建通过、测试是否运行、日志是否保存、PR 描述是否更新、截图是否归档、用户要求是否全部满足。DeskCraft 的执行式 evaluator 思路可以迁移到 macOS:用文件系统、进程状态、测试结果、页面快照和应用状态共同判断完成度。
第二,长程任务必须内置中间验收点。 L3 任务成功率 cliff 告诉我们,不能指望 agent 一口气做完 70 步再检查。更合理的系统设计是:每完成一个阶段就验证一次,例如“依赖安装完成”“测试用例生成完成”“UI 截图已保存”“崩溃日志已解析”“最终报告已写入”。这和我之前反复提到的 loop engineering 是同一个方向:把长任务拆成可验证回路。
第三,用户进入回路要协议化。 在 macOS 效率工具里,用户可能随时说“先别改这个文件”“把目标换成 release 分支”“这个截图不对,重新跑一遍”。如果系统只是把这句话塞进聊天上下文,很容易丢状态。DeskCraft 的 phase + trigger 设计提示我们:应该显式记录用户补充需求的触发点、优先级、生效范围和是否已满足。
第四,专业软件需要领域状态模型。 Blender、Kdenlive、GIMP 的失败不是简单视觉定位失败,而是 agent 不理解项目结构、时间线、图层、导出设置和文件依赖。macOS 上也一样:Xcode scheme、DerivedData、Simulator、Keychain、签名证书、Accessibility 权限、沙盒路径都是状态。真正可用的桌面 agent 需要把这些状态结构化,而不是只靠截图。
第五,安全和可追踪性要和自动化能力同步建设。 DeskCraft 里的 DONE/ASK/FAIL 很像产品中的控制面。对真实桌面 agent 来说,还应加入更细的“需要确认”“需要权限”“需要回滚”“需要人工接管”。尤其在研发场景里,删除文件、修改配置、提交代码、访问凭据都应该进入可审计轨迹。
8. 局限性与我的点评
DeskCraft 的贡献很明确,但也有一些局限需要放在上下文里看。
第一,它仍然是 benchmark,而不是真实企业环境。任务虽然来自文档、教程和专业流程,但真实工作中会有私有素材、历史上下文、团队规范、权限系统和大量隐性偏好。DeskCraft 能测试“桌面专业任务”这个方向,但不能完全代表组织内的生产流程。
第二,执行式 evaluator 的成本很高。论文为 386 个标准任务准备了 300+ evaluator functions,这本身就是一项重工程。对普通团队来说,如何低成本构造可维护的 evaluator,会决定这类评测能否规模化。
第三,交互协议虽然比静态任务真实很多,但仍然是离散 phase。真实用户的反馈可能更模糊、更情绪化,也可能夹杂“我其实想要另一种效果”这类目标漂移。未来 benchmark 可能还需要更丰富的用户模拟器和偏好建模。
第四,论文结果里使用的模型版本包含 2026 年的 proprietary / open-source agent,具体复现依赖后续开源代码、任务资产和模型接口稳定性。读实验数字时,应把它看成当前时点的能力剖面,而不是永久排名。
我的总体评价是:DeskCraft 的价值不在“又多了一个榜单”,而在于它把桌面 GUI agent 的下一阶段问题讲清楚了。这个领域正在从 ScreenSpot 式定位、OSWorld 式桌面任务,走向“专业产物交付 + 人机协作 + 可执行验证”。这也是 agent 真正进入办公、设计、研发和生产工具之前必须跨过的一道门槛。
9. 总结
DeskCraft 提出的 538 任务桌面基准,把 GUI agent 放进了更接近真实生产力场景的压力测试中:专业软件、长程工作流、交互式需求变化和执行式验收。
它给出的结论并不乐观,但非常有建设性:当前 agent 已经能完成一些短链桌面操作,却在 L3 长程交付、主动澄清、需求变更和状态管理上明显不足。最佳模型在标准任务上也只有三成左右成功率,在交互任务上更低。
对工程落地来说,DeskCraft 提醒我们不要只优化“看屏幕点按钮”的单步能力,而要把 GUI agent 当成一个带控制协议、验证器、状态模型和用户回路的系统来设计。对于 macOS 研发效率工具,这意味着未来的关键不只是让 agent 能打开 App,而是让它能在受控边界内完成可验证的研发工作流,并在不确定时正确地请求人类协作。