StainFlow:给 GUI Agent 的每一步进展一条可追踪证据链
解析 arXiv 2026 论文 StainFlow:如何用实体染色流和自适应证据窗口,为长程 GUI Agent 强化学习提供更可靠的过程奖励。
目录
- 为什么这篇论文值得关注
- 背景与问题定义:GUI 强化学习为什么难在“中间过程”
- StainFlow 的核心思路
- 方法设计拆解:Global Entity Stain Tracking
- 方法设计拆解:Local Stain Evidence Linking
- 训练与评测设置
- 实验结果与结论
- 对 macOS 研发效率工具和 GUI 自动化的启发
- 局限性与我的点评
- 总结
- 参考链接
1. 为什么这篇论文值得关注
今天选的论文是 2026 年 6 月 5 日提交到 arXiv 的 StainFlow: Entity-Stain Tracking and Evidence Linking for Process Rewards in GUI Agents。
- 论文地址:https://arxiv.org/abs/2606.07027
- PDF:https://arxiv.org/pdf/2606.07027
- 作者:Haojie Hao、Longkun Hao、Yihang Lou、Yan Bai、Zhenyang Li、Zhichao Yang、Dongshuo Huang、Hongyu Lin、Lanqing Hong、Jiakai Wang、Xianglong Liu
- 提交时间:2026-06-05
我觉得这篇论文值得单独写,是因为它没有再讨论“GUI agent 能不能看懂按钮”这个基础问题,而是切到一个更接近产品化训练闭环的核心环节:当一个图形界面智能体执行十几步甚至几十步任务时,系统到底应该如何评价它每一步是否推动了任务进展?
很多 computer-use agent 的训练反馈仍然偏稀疏:最后完成了就是成功,失败了就是失败。但真实 GUI 任务并不是这样。一个 agent 可能前 8 步都做对了,只在最后一步点错;也可能最终完成任务,但中间绕了很多无效路径。如果只看最终成功/失败,强化学习很难知道哪些动作值得保留、哪些动作应该被惩罚。
StainFlow 的答案是:不要只依赖预先写好的里程碑,也不要只看固定长度的局部窗口,而是把任务相关的 GUI 实体当成“染色载体”,沿着轨迹追踪它们的可见性、状态变化和证据强度,再围绕这些实体动态构造证据窗口。论文报告的结果包括:在 AndroidWorld 在线 RL 中相对提升 3.2% 成功率,在 OGRBench 轨迹完成判断中相对提升 1.8% 准确率。
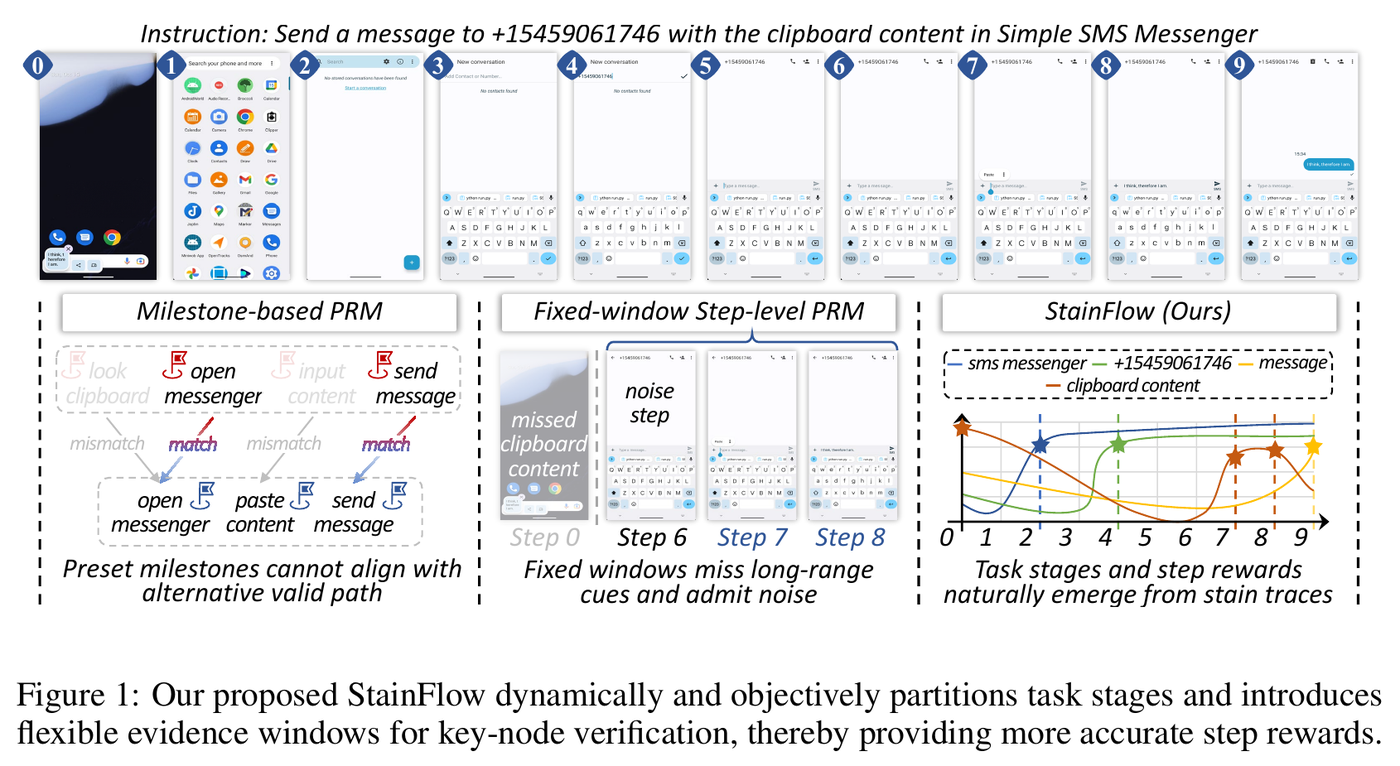
图 1:论文用短信任务说明传统 PRM 的两类失败。里程碑式奖励可能不匹配替代路径;固定窗口式奖励可能既漏掉剪贴板内容等远距离线索,又混入无关噪声。StainFlow 则让任务阶段和步骤奖励从实体证据流中自然浮现。
2. 背景与问题定义:GUI 强化学习为什么难在“中间过程”
GUI agent 的执行环境天然是长程、随机、部分可观测的。用户一句“把剪贴板内容发给某个联系人”,背后可能涉及:打开应用、搜索联系人、粘贴内容、确认发送、处理权限弹窗、返回验证等多个状态转换。对于人类来说,这些转换有清晰的语义;对于训练系统来说,它只看到一串截图、动作和最终结果。
强化学习要让 agent 变强,必须解决 credit assignment,也就是“功劳/责任分配”问题。最终成功不能说明每一步都好,最终失败也不能说明每一步都坏。过程奖励模型(Process Reward Model, PRM)的目标,就是把最终结果拆成更细粒度的训练信号。
论文把已有 GUI PRM 大致分成两类。
第一类是 global milestone verification。这类方法先把任务拆成若干阶段或子目标,然后检查轨迹是否完成了这些里程碑。优点是解释性强,缺点是很容易把一个真实 GUI 任务压缩成单一路径。真实用户和 agent 经常有多条可行路径:可以搜索、可以从最近联系人进入、可以用分享面板、可以从历史记录恢复。预设里程碑如果只覆盖其中一种路径,就会低估其他有效路径。
第二类是 local step-level evaluation。这类方法围绕当前步骤、当前截图、动作和短上下文来判断动作价值。优点是反馈及时,缺点是 GUI 证据经常跨越很长时间。比如剪贴板内容在第 0 步出现,真正发送在第 8 步发生;固定窗口如果只看第 7-9 步,就可能不知道发送内容是否正确。窗口开得太大,又会把大量无关帧塞进判断,稀释信号。
StainFlow 的问题定义正是针对这两点:如何在不预设单一路径的情况下发现全局进展,又如何在不使用固定窗口的情况下为关键步骤找回真正相关的证据?
3. StainFlow 的核心思路
StainFlow 借鉴了网络流分析里的 stain tracing / traceback 思想。可以把 GUI 轨迹想象成一条信息流,任务里的关键实体——联系人、目标应用、剪贴板内容、目标文件、待发送消息、订单状态——就是“染色载体”。当某个实体在截图中出现、被选择、被修改、消失或转移时,它的“染色浓度”和状态也随之变化。
这套比喻放到 GUI agent 中很自然:任务进展往往不是抽象地发生在“第几步”,而是发生在实体状态的变化上。
- 联系人从未出现到被搜索出来;
- 文件从源目录出现到目标目录出现;
- 表单字段从空白变成指定内容;
- 按钮从不可点击变成可点击;
- 订单状态从未提交变成已确认;
- Terminal 命令从未执行变成输出完成结果。
因此,StainFlow 的整体设计包含两个模块。
- Global Entity Stain Tracking:抽取任务相关、视觉可验证的实体,追踪它们在轨迹中的可见性、状态和染色浓度,从实体流的变化中发现候选关键节点。
- Local Stain Evidence Linking:以候选关键节点的触发实体为中心,检索局部步骤和远距离相关步骤,构造动态证据窗口,再判断这个候选节点是否真的是关键进展。
这两部分共同把“过程奖励”从人为拆分的里程碑,转成围绕 GUI 实体状态变化的证据链。
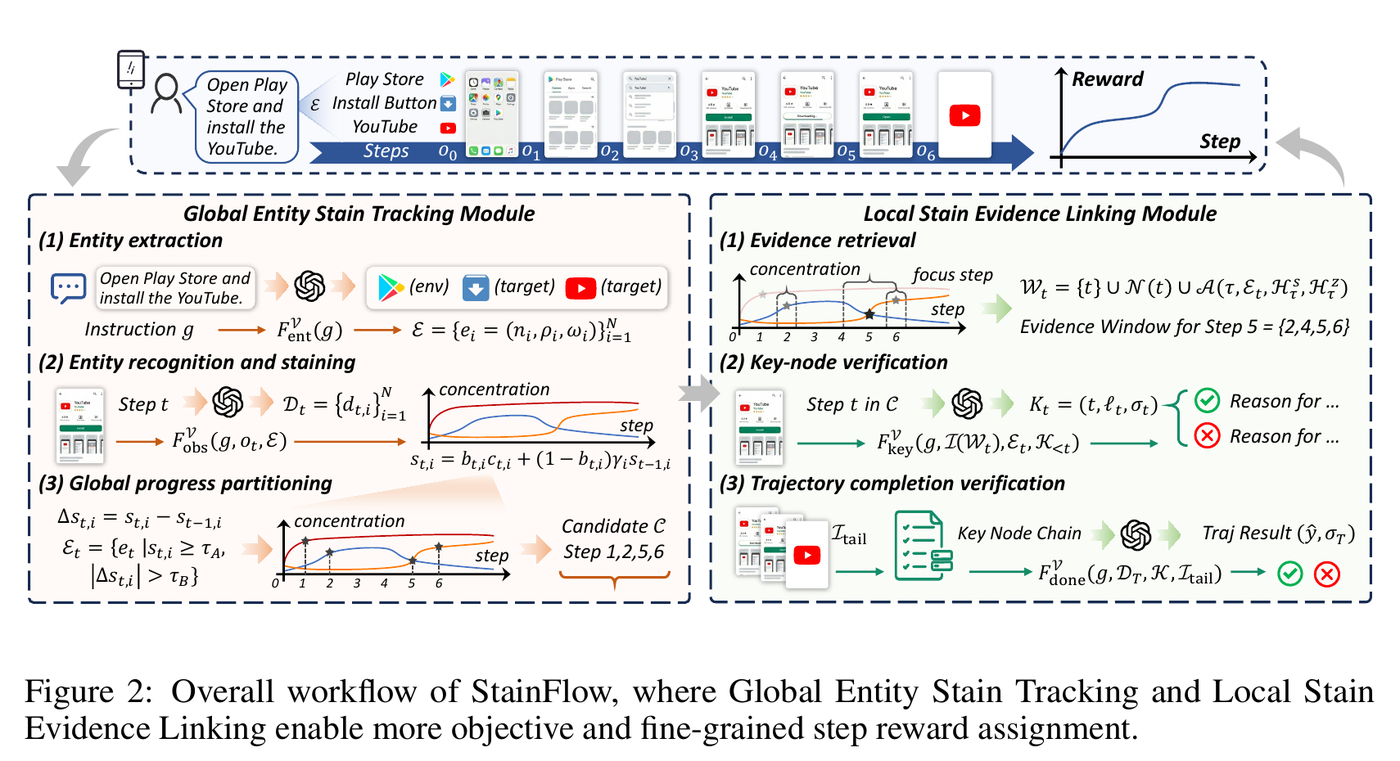
图 2:StainFlow 的 workflow。左侧追踪实体染色浓度与状态变化,产生候选节点;右侧围绕候选节点构造自适应 evidence window,并进一步做 key-node verification 和 trajectory completion verification。
4. 方法设计拆解:Global Entity Stain Tracking
Global Entity Stain Tracking 的目标,是替代“先验里程碑拆分”。它不是先问模型“这个任务应该分成哪几步”,而是先从执行轨迹中抽取实体,再观察这些实体如何随时间变化。
论文把任务实体表示成带有名称、角色和持久性等属性的对象。比如在“给某个号码发送剪贴板内容”的任务中,实体可能包括短信应用、目标号码、剪贴板内容、消息输入框、发送按钮等。不同实体的持久性不同:应用环境、目标联系人可能持续存在;临时 toast、弹窗、某一次输入内容则更短暂。
染色浓度可以理解为一个随时间更新的证据强度。实体在当前截图中可见且状态明确时,浓度上升;实体暂时不可见时,浓度按衰减系数下降。持久实体使用较慢衰减,瞬态实体使用较快衰减。论文实现中,持久实体的 decay 使用 0.8,其他实体使用 0.5。
候选关键节点来自几类信号:
- 实体染色浓度超过高阈值,说明该实体当前成为强证据;
- 染色浓度发生明显变化,说明任务状态可能发生转换;
- 实体属性或状态发生变化,比如内容被写入、目标被选中、结果被确认。
这个设计的重要性在于,它允许任务阶段从轨迹中“长出来”。如果 agent 走的是替代路径,只要关键实体状态真的发生了有效变化,StainFlow 就有机会识别到进展,而不是要求它命中某个预设子目标。
5. 方法设计拆解:Local Stain Evidence Linking
只找到候选关键节点还不够,因为并不是每个浓度变化都代表有效进展。有些变化可能是界面噪声、误点、回退或无关弹窗。因此,StainFlow 的第二步是对候选节点做 evidence linking。
传统固定窗口方法通常只看当前步附近的若干帧。StainFlow 改成以触发实体为中心构造动态窗口,包含三类信息:
- 候选步骤本身;
- 候选步骤附近的局部邻域;
- 与触发实体相关的远距离支持步骤。
这能解决 GUI 任务中的一个常见问题:关键证据不一定在当前截图附近。比如第 8 步点击发送按钮是否正确,可能要回看第 0 步剪贴板内容、第 3 步联系人选择、第 6 步输入框内容。固定窗口容易漏掉这些信息;全量历史又太吵。StainFlow 的实体链相当于提供了一个检索索引:只把与当前候选节点相关的证据拿回来。
验证阶段会输出 key-node 信息,包括步骤、标签和置信度。随后,系统再结合关键节点链、尾部截图证据和任务目标,判断整条轨迹是否完成。这样,StainFlow 同时服务两个目标:训练时的细粒度步骤奖励,以及推理/评测时的轨迹完成判断。
6. 训练与评测设置
论文做了两类实验。
第一类是 AndroidWorld 在线强化学习。GUI policy model 使用 Qwen3-VL-8B,辅助 verifier 使用 Qwen3.5-VL-9B 和 Qwen3.5-VL-27B。对比方法包括:
- No Training;
- 只用环境最终结果的 Outcome Reward;
- GUI-Critic-R1;
- ADMIRE;
- OS-Themis;
- StainFlow。
在线 RL 训练设置包括 5 个 epoch、batch size 64、GRPO group size 8、学习率 1e-5、过程奖励权重 η = 0.5。这些细节说明论文不是只做离线评估,而是把 PRM 放进实际训练循环里看它对策略成功率的影响。
第二类是 OGRBench 轨迹完成判断。这里比较多个视觉语言模型作为 verifier,包括 Qwen3-VL-8B、Qwen3.5-VL-9B、Qwen3.5-VL-27B、GPT-5、Gemini-3-Flash;任务环境覆盖 Ubuntu、Mobile、Windows、MacOS、Web。这个设置对 desktop / computer-use agent 更有参考价值,因为它不局限于 Android 单一界面形态,而是跨移动、桌面和网页环境测试轨迹判断能力。
7. 实验结果与结论
最直观的结果来自 AndroidWorld 在线 RL。论文报告:在 Qwen3.5-VL-9B verifier 下,StainFlow 成功率为 60.34%,高于 ADMIRE 的 56.90% 和 OS-Themis 的 58.62%;在 Qwen3.5-VL-27B verifier 下,StainFlow 达到 62.28%,高于 ADMIRE 的 57.76% 和 OS-Themis 的 60.34%。
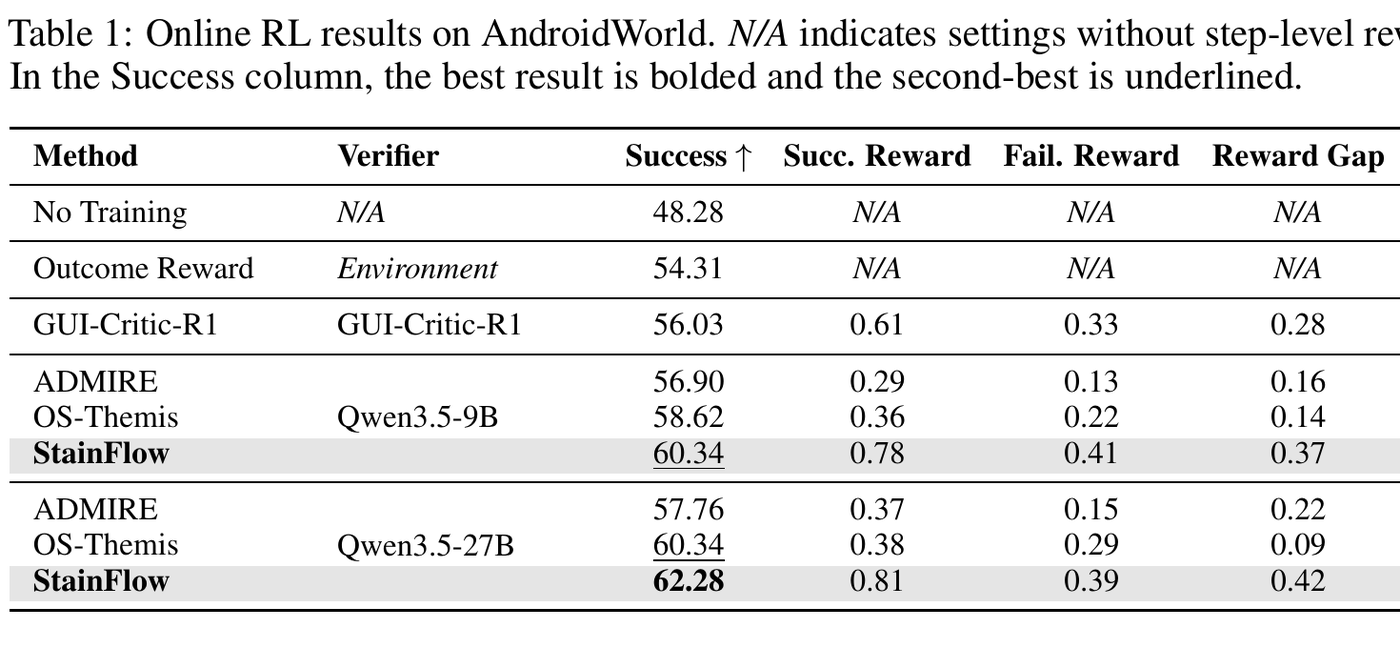
图 3:论文 Table 1。StainFlow 不只提高最终成功率,也拉开了成功轨迹与失败轨迹的 reward gap。更大的 reward gap 通常意味着过程奖励更能区分真实进展和无效步骤。
这里有一个比最终成功率更值得关注的指标:reward gap,也就是成功轨迹平均步骤奖励和失败轨迹平均步骤奖励之间的差距。用 Qwen3.5-9B 时,StainFlow 的 reward gap 为 0.37,明显高于 ADMIRE 的 0.16 和 OS-Themis 的 0.14;用 Qwen3.5-27B 时,StainFlow 的 reward gap 为 0.42。这说明它不只是“给更多奖励”,而是更能区分有效进展和无效路径。
在 OGRBench 轨迹完成判断中,论文报告使用 Gemini-3-Flash 时,StainFlow 取得 overall Acc./F1 88.2 / 88.2,相对最强 baseline OS-Themis 有 1.8% 的 accuracy gain。更重要的是,它在 Ubuntu、Mobile、MacOS、Web 等子集上表现都较强,说明“实体证据链”不完全依赖某一种 UI 结构。
消融实验也支持两个模块都重要。只保留 Global Stain 容易高估弱证据;只做 Local Judgment 容易把太多步骤误判为关键节点;把动态证据链接换成固定窗口,则会漏掉远距离证据,导致 reward gap 下降。换句话说,StainFlow 的收益来自“全局实体流 + 局部自适应证据窗口”的组合,而不是某一个简单技巧。
8. 对 macOS 研发效率工具和 GUI 自动化的启发
我最关心的是:这篇论文对 macOS 研发效率工具、桌面自动化和 computer-use 产品有什么启发?
第一,桌面 agent 的评测不能只看最终状态,还要记录实体级证据链。比如让 agent 在 Xcode 中切换 scheme、运行测试、定位失败日志、打开相关文件并修改代码。如果只看最后有没有改文件,很难判断中间步骤是否可靠。更合理的评测应记录:目标 project 是否打开、scheme 是否正确、test target 是否执行、失败 case 是否定位、修改文件是否匹配错误堆栈。StainFlow 的实体染色思路可以直接迁移为“研发任务实体链”。
第二,过程奖励也可以成为产品可解释性的一部分。用户不会放心一个黑盒 agent 长时间操作自己的电脑。如果系统能展示“本轮执行中,哪些实体被识别为任务关键对象、哪些状态变化被判定为进展、哪些步骤被视为无效探索”,可调试性会大幅提升。这对 macOS 自动化尤其重要,因为 Finder、Terminal、Xcode、浏览器、内部平台之间的状态经常跨应用流动。
第三,自动化回归测试可以从 fixed checkpoint 走向 evidence-linked checkpoint。传统 GUI 自动化脚本常写死断言:某个按钮出现、某段文本存在、某个 URL 匹配。但 agent 任务更开放,路径可能变化。StainFlow 启发我们把断言写成实体状态链:目标文件从 A 目录移动到 B 目录、issue 状态从 open 变成 resolved、测试报告从 failing 变成 passing。这样既保留可验证性,又允许多路径执行。
第四,混合动作系统也需要实体流统一视角。未来的 macOS agent 不会只靠鼠标点击,它会混合 GUI、CLI、AppleScript、快捷指令、API、浏览器 DevTools 等动作。不同动作通道的共同语言,不应该是“第几步调用了哪个工具”,而应该是“哪个任务实体的状态发生了可验证变化”。StainFlow 的实体染色可以作为跨通道 trace 的抽象层。
第五,安全与权限治理可以挂在实体证据上。如果某个任务实体涉及敏感文件、账号、生产环境、付款、删除操作,那么系统应在染色浓度上升或状态即将改变时触发更强的确认、日志和回滚策略。也就是说,过程奖励不只是训练信号,也可以成为运行时风险控制信号。
9. 局限性与我的点评
StainFlow 的方向很有价值,但也有几个需要谨慎看的点。
第一,实体抽取本身依赖视觉语言模型能力。如果 verifier 不能稳定识别任务实体,后续染色浓度和证据链接都会受影响。GUI 中的实体有时并不显式,比如隐藏菜单、快捷键触发状态、后台任务、文件系统变化,这些都不是单张截图容易捕捉的。
第二,“视觉可验证实体”覆盖不了所有 computer-use 状态。桌面研发任务里,很多关键状态存在于进程、文件、数据库、git diff、测试日志、网络请求中。仅靠截图会不够。真正落地到 macOS R&D agent 时,StainFlow 需要扩展为多模态实体流:视觉实体、文件实体、命令输出实体、代码符号实体、浏览器 DOM 实体共同参与证据链。
第三,过程奖励的正确性仍然需要任务级验证器兜底。StainFlow 能给中间步骤更细粒度的信号,但如果最终完成判断本身不可靠,训练仍可能学到错误捷径。尤其是涉及文件删除、发布、权限变更、数据写入的任务,必须有外部可执行验证,而不能只依赖 VLM 判断截图。
第四,3.2% 和 1.8% 的提升不是颠覆性数字,但方向比数字更重要。在 GUI agent 研究里,很多论文追求 benchmark 排名;我认为 StainFlow 更有意义的地方,是把 PRM 从“看当前动作好不好”推进到“围绕实体追踪长期证据”。这更接近真实产品需要的可审计训练闭环。
我的总体判断是:StainFlow 是一篇偏“训练基础设施”的论文。它不直接发明一个新的万能 GUI agent,而是回答了一个更底层的问题:当 agent 在复杂界面中探索时,系统如何把轨迹变成高质量、可解释、可复用的过程反馈? 对长期要做 desktop / mobile / web computer-use agent 的团队来说,这个问题非常关键。
10. 总结
StainFlow 的核心贡献可以概括为一句话:用任务实体的状态流替代主观里程碑,用自适应证据窗口替代固定局部上下文,从而为 GUI agent 强化学习提供更可靠的过程奖励。
它解决的不是“模型是否会点按钮”,而是“训练系统如何知道某一步点击是否真的推动了任务”。这个问题看似幕后,却决定了 GUI agent 能否从 demo 走向持续学习、持续评测、持续可靠的产品系统。
对 macOS 研发效率工具而言,我最值得带走的启发是:未来的桌面 agent 不应只保存操作日志,而应保存实体级证据链。一个好的 agent 运行记录应该能回答:它在什么时候识别了哪个任务实体?该实体状态如何变化?哪些动作被判定为有效进展?哪些动作只是噪声?这套 trace 既能训练模型,也能服务调试、审计、回滚和用户信任。
11. 参考链接
- StainFlow: Entity-Stain Tracking and Evidence Linking for Process Rewards in GUI Agents:https://arxiv.org/abs/2606.07027
- PDF:https://arxiv.org/pdf/2606.07027
- AndroidWorld benchmark(论文评测环境之一):https://github.com/google-research/android_world