QA Wolf:把端到端测试做成 AI 平台 + 托管服务
从官方文档和官网页面拆解 QA Wolf 的完整服务链路:环境准备、Mapping、Automation AI、调试、运行、失败调查、清理发布和 Full Service 到底分别做什么。
资料基于 QA Wolf 官方文档与官网页面,整理时间:2026-06-09。
官方入口:QA Wolf Docs、QA Wolf 官网。
先说结论:QA Wolf 提供的是“覆盖交付”,不只是“AI 写脚本”
QA Wolf 很容易被误解成一个 AI 测试录制器:给它一句话,它帮你点点点,最后生成一条自动化用例。这个理解太窄了。
从官方文档看,它更接近一套 E2E 测试覆盖交付系统:
- 先准备测试环境:变量、账号、并发、私有网络、默认环境。
- 用 Mapping AI 探索应用,生成覆盖地图和 flow stubs。
- 用 Automation AI 把 stubs 或自然语言需求变成 Playwright / Appium 代码。
- 在 live browser 里运行、调试、修复、发布测试代码。
- 通过手动、定时或 CI/CD 触发 run。
- 每个 flow 最多尝试三次,逐步降低并发,减少临时环境问题带来的误判。
- 失败后进入 Investigation,按 flake、产品 bug、broken test 三类归因。
- 用重试、修代码、bug report、maintenance report 或 Do Not Investigate 清理发布信号。
- Full Service 场景下,QA Wolf 的服务团队会参与创建、维护、调查和扩展覆盖。
所以它卖的不是一个“测试生成按钮”,而是把端到端测试从一次性脚本,变成持续覆盖、持续运行、持续维护的流程。

图 1:按 QA Wolf 官方 Map、Automate、Runs、Clearing a release、Environment docs 整理的生命周期图。图里每个节点对应一个真实操作阶段,不是抽象架构图。
下面按这条链路拆开讲。
阶段 0:环境先准备好,否则后面都是假稳定
在 QA Wolf 里,environment 不只是一个名字。官方 Environment docs 把它定义成应用的某个版本,比如 development、staging、production。每个环境可以有自己的变量、并发限制、VPN 访问和相关设置。这里最关键的点是:flows 和 tests 是按环境隔离的,不会跨环境共享。
实际落地时,这一步要做四件事。
第一,创建环境。入口是 workspace settings 里的 Environments,创建后给它一个唯一名字。常见命名是 Staging、Production、PR Preview、Customer Demo 这类。
第二,配置默认环境。Flows 和 Runs tab 都依赖默认环境,团队最好把最常调试的环境设成默认值。若启用了 PR testing,还要单独设置 PR testing 的 base environment。
第三,配置变量。典型变量包括:
BASE_URL:当前环境的入口地址;- 测试账号、租户 ID、组织 ID;
- API token、第三方服务密钥;
- 支付、邮件、短信、MFA 等测试凭据。
这些变量是按环境加密存储的。官方文档也提醒,QA Wolf 不会强制跨环境变量名一致,所以团队要自己约定命名,例如 staging 和 production 都叫 BASE_URL,只是值不同。
第四,控制并发和网络访问。默认情况下,QA Wolf 会并发执行 run 里的 flows;如果环境承压有限,可以给 environment 设置 concurrency limit。内部系统或预发环境还可能需要 OpenVPN、IPSec、Tailscale、Twingate 或静态 IPv4 allowlist。
这一阶段的产出很明确:一个能被 QA Wolf 稳定访问、变量完整、并发可控、网络打通的测试环境。如果这里没准备好,后面的 Mapping 和 Run 会把环境问题误判成产品问题或测试问题。
阶段 1:Mapping AI 先生成“该测什么”
很多团队做 E2E 自动化的第一步是直接写脚本,但 QA Wolf 把第一步放在 coverage map:先搞清楚应用有哪些关键用户路径、状态和边界。
官方 Create a product map 文档里的流程很明确。
第一步,从 Map tab 开始。点击右侧的 New Flows,或者点左侧 sidebar 里的图标并选择 Mapping session。
第二步,新的 mapping session 会打开一个 live browser。agent 会让你确认要探索的 URL,也可以直接在 chat 里输入自己的指令。
第三步,告诉 agent 要探索什么。可以是宽泛目标,比如:
Create a test plan for https://yourapp.com也可以更具体:
Map admin user flows around inviting a teammate, changing permissions, and removing a member.第四步,实时引导。Mapping 不是一次性丢 prompt 就结束。agent 遇到登录、权限、验证码、页面不确定或范围不清时,会在 chat 里问你。你可以随时补充账号、限定范围、让它跳过某个区域,或者要求它继续找更多 flows。
第五步,审查新发现的 flows。agent 探索过程中,右侧会出现 New tab,里面是它创建的 flow stubs。这里的 stub 不是完整测试代码,而是“这个用户路径应该被测试”的结构化占位。
第六步,发布到 coverage map。点击 Publish 后,这些 flows 会进入 coverage map,并在 Automate tab 里创建对应的 folder structure 和 empty flow files。
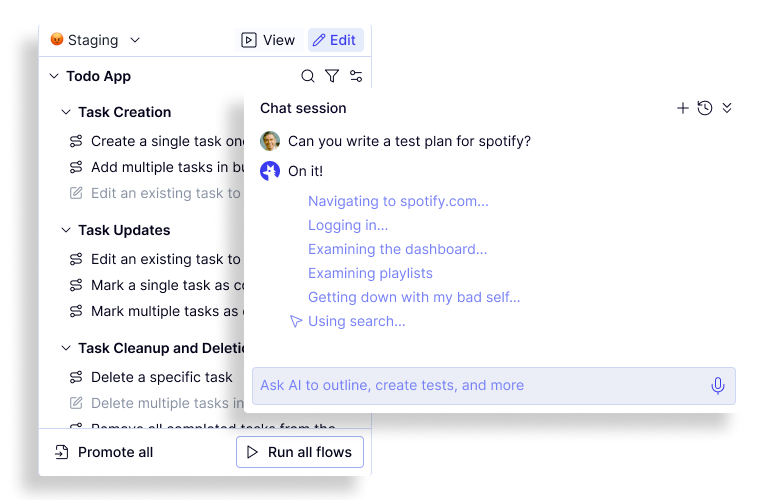
图 2:Mapping AI 的官网产品图。左侧是覆盖地图,右侧是 mapping agent 的探索对话。图片来源:QA Wolf 官网。
这一阶段最容易误会的地方是:Mapping 的结果不是“测试已经写完了”,而是“覆盖范围被结构化了”。它的产出是:
- 哪些功能区域需要测;
- 每个区域里有哪些用户路径;
- 这些路径如何组织成 folders 和 flows;
- 哪些 flows 还只是 stub,需要进入 Automate 阶段补代码。
这一步解决的是“该测什么”,不是“代码怎么写”。
阶段 2:Automation AI 把流程补成可运行代码
Mapping 之后,QA Wolf 进入 Automate。这里的目标是把自然语言流程或 flow stub 补成真实可执行代码。
官方 Automate flows using AI 文档里的入口也很明确:从 Automate tab 打开右侧 AI chat panel,然后用文字或语音描述你想让 flow 做什么。
常见输入可以很简单:
Log in with a valid email and password and assert that the dashboard loads.也可以更接近真实业务:
Invite a new teammate as an admin, verify the invite email arrives, accept the invitation, and assert the new user appears in the members table.Automation AI 做的事包括:
- 如果 group 或 flow 不存在,它会先创建所需结构。
- 生成 flow code,并在编辑器里打开。
- 你可以立即点 Run,在右侧浏览器面板看它执行。
- 你可以 review code,手动改,也可以继续在 chat 里让 AI 修改。
- 如果 flow 失败,可以点击 banner 里的 Fix with AI,或者把 Logs tab 的错误贴回 chat。
- 需要第三方库时,可以直接让 AI import package。

图 3:按官方 Mapping 与 Automate docs 整理的 authoring 细节图。左边阶段产出 stubs,右边阶段产出可运行测试代码。

图 4:Automation AI 的官网产品图。左侧是 flow/code,右侧是浏览器和 AI 辅助调试面板。图片来源:QA Wolf 官网。
这里有一个重要设计选择:QA Wolf 没有把回归测试做成“每次运行都让 agent 临场看屏幕、临场推理、临场点击”。它用 AI 生成和维护代码,但最终运行的是 Playwright / Appium 这类确定性测试。
这样做的好处是:
- 代码可以 review;
- 失败有具体行号;
- selector、assertion、helper function 可以持续演进;
- 团队能复用 Playwright / Appium 生态;
- 测试资产可以版本化,而不是散在一次次 agent 轨迹里。
阶段 3:调试不是只看错误,要用四个面板缩小问题
官方 Debug tests & flows 文档把调试入口说得很清楚:点击 Run 后,右侧 live browser 会实时展示 flow 执行过程。
如果通过,编辑器顶部会出现绿色 Flow passed banner。
如果失败,编辑器顶部会出现红色 Flow failed banner,失败代码行会被高亮。此时有两条主要修复路径:
- Fix with AI:让 Automation AI 根据错误自动诊断和修复;
- 局部运行:重置浏览器状态,选中一段代码运行,避免每次都重跑整个 flow。
QA Wolf 的调试面板更值得细看。底部右侧面板主要有四个 tab:
- Problems:默认问题面板。比如命名冲突、结构问题、发布前需要处理的问题,会在文件树上标黄点。
- Logs:时间戳执行日志。失败时最快的线索通常在这里,也可以把日志贴给 AI。
- Elements:输入 locator 或 CSS selector,在 live browser 中高亮匹配元素,用来确认 selector 是否稳定。
- Details:显示 tags 和 readiness status。运行后也会显示每个 run step 的耗时,用来找慢步骤或卡住的步骤。
这一步的产出不是“某次手动运行通过”这么简单,而是:
- flow 代码被修到能稳定通过;
- selector 和 assertion 被验证过;
- tags、readiness、依赖关系等元信息被补齐;
- 该 flow 可以进入 schedule 或 CI run。
需要注意一个细节:Automate 里的 Run History 只显示 scheduled runs。编辑器里手动跑、Map tab 手动跑,不会进入这个历史视图。这一点很容易误会。
阶段 4:Run 是发布信号,运行方式不同,反馈位置也不同
QA Wolf 的 run 是一个或多个 flows 的执行。官方 How Runs work 文档把入口分得比较细:
| 运行方式 | 典型入口 | 反馈在哪里 | 是否进 Run History |
|---|---|---|---|
| 选中几行运行 | Automate editor | Editor only | 否 |
运行一个 test() block | Automate editor | Editor only | 否 |
| 运行一个完整 flow | Automate Run button | Editor only | 否 |
| 在环境里运行全部 flows | Map / Runs tab | Runs tab | 否 |
| 在环境里选择部分 flows | Map / Runs tab | Runs tab | 否 |
| scheduled run | schedule 自动触发 | Runs tab + Run History | 是 |
| CI/CD 触发 | 部署成功或 webhook | Runs tab / 状态检查 | 通常作为发布信号 |
这张表的意义是:你在编辑器里点 Run,更像开发调试;scheduled run 和 CI/CD run 才更像团队发布流程里的质量信号。
QA Wolf 的 run 有两个状态最核心:
- Completed:所有 flows 通过,或者失败项已经被标记为 Do Not Investigate。
- Needs Investigation:一个或多个 flows 失败,并且还没有被处理。
还有一个常见状态:
- Canceled:同一个 branch 和 environment 上有后续 run 触发,旧 run 在执行中被取消。
阶段 5:失败最多尝试三次,不是一红就立刻报 bug
QA Wolf 的 retry 逻辑值得单独拿出来讲,因为它直接影响如何理解红灯。
官方 How Runs work 文档说,run 里的每个 flow 最多尝试三次,目的不是“硬凑通过率”,而是排除偶发环境问题。
三次尝试的并发策略也不同:
- 第一次:默认所有 flows 并发执行,除非 run rules 指定了其他顺序。
- 第二次:只重跑第一次失败的 flows,并且五个一批执行。
- 第三次:第二次后仍失败的 flows 串行执行。
这个设计很实际。第一次并发能节省时间;第二次降低并发,减少环境碰撞;第三次串行,进一步排除互相干扰。如果三轮之后仍失败,就更有理由进入 Investigation。

图 5:按官方 How Runs work、Diagnose、Clear a release docs 整理的运行决策图。上半部分是 run 和 retry,下半部分是失败归因与清理方式。

图 6:Run Infra 的官网产品图。它把不同 run 的状态、失败数、bug 数和维护数放在同一视图里。图片来源:QA Wolf 官网。
这一步的产出是一个更可信的发布信号:不是“某个脚本刚刚失败了”,而是“这个 flow 在降并发和串行重试后仍未清理,需要调查”。
阶段 6:Investigation 把失败归成三类
官方 Diagnose 文档把失败原因分成三类:
- Flakes:基础设施、网络、依赖服务或临时环境问题导致的失败,应用和 flow 本身可能没问题。
- Bugs:应用行为确实不符合预期,是产品问题。
- Broken tests:flow 逻辑、selector、断言或历史假设不再匹配应用,是测试代码问题。
这三类非常重要,因为后续动作完全不同。
进入 Investigation view 后,推荐的排查顺序是:
- 从 Runs tab 打开处于 Investigating 或 Failed 的 run。
- 在左侧面板看 Failed、Running、Passed 分类。
- 点击 Failed tab,只看失败 flows。
- 选择某个 flow,看被高亮的失败代码行。
- 如果一个 flow 在同一个 run 里被尝试多次,切换 attempts 对比:每次都同一行失败,还是偶发失败。
- 看 recorded video。视频通常是最快判断“产品没出现预期页面”还是“selector 写错了”的证据。
- 打开 Playwright trace,看 DOM、网络、截图、action timeline。
- 查看 Run History。最多可以看最近 100 次 run,判断是不是最近才开始回归。
- 查看 Activity 和 Notes。Activity 可以解释 flow 何时改过 readiness、maintenance;Notes 可以记录已知边界和排查结论。
到这一步,QA Wolf 的价值就不只是“告诉你挂了”,而是把证据集中在一个调查界面里,帮你把失败从噪音变成可处理事项。
阶段 7:Clear Release 的目标不是 100% 全绿,而是所有失败都有结论
官方 Clear a release 文档说得很直接:解决失败不是追求 100% passing results,而是有意识地清理 release。
这句话很关键。现实发布里,有些失败是 flaky 环境问题,有些是测试过期,有些是真 bug,有些是已知第三方依赖问题。QA Wolf 关心的是:每个失败是否被审查、归因、处理,并且不再悬空。
常见清理方式有五类。
第一类,flake 重试。适用于你确认失败来自临时环境问题。可以选择:
- Reattempt with latest version:只重跑失败 flows,快速确认问题是否消失;
- Duplicate run:完整复制 run,包括最多三次尝试,适合确认临时问题是否掩盖了更深的问题。
第二类,Do Not Investigate。适用于你理解失败原因,但它不应该阻断当前发布。例如第三方依赖已知短暂异常。被标记后,这个失败 flow 对当前 run 来说算 resolved。
第三类,修 broken test。入口通常是 Investigation view 里的 Edit code。修完之后需要 publish changes,然后用 Use as reattempt 把新版 flow 应用回当前 run。通过后,它会进入 Completed。
第四类,file bug report。适用于产品问题。bug report 的 severity 会影响环境状态,比如高优先级 bug 可能让环境显示 Failed。
第五类,file maintenance report。适用于测试本身需要较多维护,当前发布窗口内不适合马上修完。maintenance report 会阻止这个 flow 被纳入后续 runs,直到修复完成。
一个 run 只有在所有 failed flows 都被通过、修复、绕过、挂 bug 或挂 maintenance 后,才会转成 Completed。所有 run 都清理完成后,环境才能退出 Needs investigation 或 Failed,回到可以发布的状态。
阶段 8:CI/CD 集成把 QA Wolf 接到发布流程里
如果 QA Wolf 只停留在平台里,它的价值会打折。官方 CI/CD 文档把它接到部署流程里,典型方式包括 GitHub Actions、GitLab、CircleCI、Azure DevOps、webhook 和 SDK。
以 GitHub Actions 为例,大致链路是:
- 在 QA Wolf 里创建 static environment,记录 environment ID。
- 配置
QAWOLF_API_KEY。 - 在部署成功后调用
qawolf/notify-qawolf-on-deploy-action。 - QA Wolf 收到部署成功事件后触发对应 environment 的测试。
- PR testing 场景下,对 preview environment 运行测试,并把结果写回 GitHub status checks。
- 如果启用 CI Greenlight,就可以把 QA Wolf 的结果作为 pipeline gate 或合并门禁。
这一步的产出是自动化发布信号:每次部署、每个 PR、每个 preview environment 都能触发对应测试,而不是靠 QA 或开发手动点。
Full Service:平台之外,它还提供托管 QA 团队能力
到这里为止,QA Wolf 已经像一个 AI 测试平台。但它的商业形态不止平台,还包括 Full Service,也就是官方常说的 Coverage-as-a-Service。
从 Full Service FAQ 看,QA Wolf 会参与这些工作:
- 帮客户创建端到端测试;
- 按产品变化扩展覆盖;
- 维护 Playwright / Appium 测试;
- 调查失败;
- 判断是产品 bug 还是测试问题;
- 把产品 bug 同步到 Slack、Teams、Jira、Linear 等协作工具;
- 对测试维护问题进行修复或 maintenance 处理。
这解释了 QA Wolf 的核心差异:它不只是给你一个平台让你自己折腾,而是把“写测试、跑测试、查失败、修测试”一起打包成服务。
对缺少专职自动化 QA 团队的公司,这个模式有吸引力。因为 E2E 测试最耗人的部分通常不是第一条脚本,而是半年后产品改了、selector 变了、数据脏了、账号冲突了、第三方服务抽风了,谁来每天处理这些红灯。
它能覆盖哪些测试场景
从官方 Welcome 文档和 Solutions 列表看,QA Wolf 覆盖面很宽。
Web 侧包括:
- Canvas、WebGL、拖拽、文件上传下载、PDF 校验;
- 视觉回归、UI diff;
- 多用户、多会话、多站点跨域流程;
- 浏览器扩展、Electron 和混合桌面应用;
- 邮件、短信、二维码、MFA;
- AI 输出断言、性能和可访问性检查。
移动端包括:
- iOS 和 Android 原生应用;
- 手势、布局、设备方向;
- Push notification、deep link、权限弹窗;
- Apple Pay / Google Pay;
- 相机、照片、视频、音频、GPS、蓝牙、Wi-Fi 等设备能力;
- Web 和移动端之间的跨设备旅程。
这说明 QA Wolf 面向的不是“登录按钮是否存在”这种简单 smoke test,而是现代产品里那些跨用户、跨设备、跨系统、状态复杂、人工回归又很贵的路径。
适合谁,不适合谁
比较适合的团队:
- 发布频率高,但人工回归跟不上。每天多次部署、PR preview 多、主路径不能靠人工点。
- 业务流程复杂。例如多角色、多租户、支付、邮件、短信、移动端硬件能力、企业后台、SaaS 工作流。
- 缺少成熟自动化 QA 团队。希望有人持续维护覆盖,而不是只买一个工具。
- 需要发布门禁。希望 QA Wolf 的 run 状态能进入 GitHub、GitLab 或 CI pipeline。
- 想保留代码资产。生成的是 Playwright / Appium 代码,团队可以 review 和修改。
不一定适合的团队:
- 产品还在极早期,连核心路径都每天重写;
- 只需要几条 smoke test,用 Playwright + CI 自己就能搞定;
- 公司要求测试运行基础设施完全内建,不能接受托管服务访问测试环境;
- 团队更需要底层框架自由度,而不是覆盖交付和维护服务;
- 应用没有稳定测试环境、账号、数据和网络入口,短期内难以接入外部运行器。
图表校对说明
这篇里的三张自绘图不是 QA Wolf 官方架构图,而是我按官方文档整理的步骤图。校对口径如下:
- 图 1 的 8 个节点,对应 Environment、Map、Automate、Runs、Diagnose、Clear a release 等文档页面里的操作阶段。
- 图 3 的 Mapping 部分对应 Create a product map:开启 mapping session、输入 URL/指令、实时引导、审核 New flows、Publish 到 Automate。
- 图 3 的 Automate 部分对应 Automate flows using AI:输入文字/语音、生成代码、Run、Fix with AI、发布代码。
- 图 5 的三次尝试对应 How Runs work:第一次并发、第二次失败项五个一批、第三次串行。
- 图 5 的失败分类对应 Diagnose:flakes、bugs、broken tests。
- 图 5 的清理动作对应 Clear a release:reattempt、duplicate run、Do Not Investigate、repair broken test、bug report、maintenance report。
另外,我在本地按博客正文宽度导出过这些 SVG,并检查文字是否重叠、裁切、过小或空白。图里没有把所有配置项都塞进去,细节放在正文里讲,是为了缩到移动端时仍然能读。
总结
QA Wolf 的核心不是“AI 会不会点按钮”,而是把 E2E 测试做成一条完整生产链路:
- AI 负责探索覆盖和生成测试;
- 代码负责可复现执行;
- 托管基础设施负责并行运行和移动设备;
- Investigation 负责把失败变成可处理证据;
- Full Service 负责长期维护和失败分流;
- CI/CD 集成负责把结果送回发布流程。
这也是它最值得借鉴的地方:AI 没有被放在最不稳定的位置上每次临场操作,而是被用来加速覆盖发现、代码生成和失败修复;真正要求稳定性的回归执行和发布判断,仍然落在代码、运行基础设施和明确的状态机上。
参考资料
- Welcome to QA Wolf
- Mapping AI
- Create a product map
- Automation AI
- Automate flows using AI
- How to verify and debug your test
- How Runs work
- Reviewing run results
- Diagnose the cause of a failing flow
- Clear a release
- Configure environments
- Run Infra
- Full Service FAQ
- GitHub Actions integration
- PR testing for GitHub
- QA Wolf Trust Center