SE-GA:让 GUI Agent 从静态执行器进化成会积累经验的学习者
解析 ICML 2026 论文 SE-GA:如何用 TTME 分层记忆与 MASE 自进化训练,提升图形界面智能体在长程、多步、动态 GUI 任务中的泛化与稳定性。
目录
- 为什么这篇论文值得关注
- 背景与问题定义:GUI agent 为什么会“越做越糊涂”
- SE-GA 的核心思路
- 方法设计拆解:TTME 分层记忆
- 方法设计拆解:MASE 自进化训练
- 实验结果与结论
- 对 macOS 研发效率工具和 GUI 自动化的启发
- 局限性与我的点评
- 总结
- 参考链接
1. 为什么这篇论文值得关注
今天选的论文是 ICML 2026 接收论文 SE-GA: Memory-Augmented Self-Evolution for GUI Agents。
- 论文地址:https://arxiv.org/abs/2605.16883
- HTML:https://arxiv.org/html/2605.16883v1
- 代码:https://github.com/jinshilong-dev/SE-GA
- 作者:Shilong Jin、Lanjun Wang、Zhuosheng Zhang
- 时间:arXiv:2605.16883v1,2026 年 5 月 16 日提交;ICML 2026 接收
我觉得这篇论文值得单独写,是因为它切中了 GUI agent / computer-use agent 走向真实产品时的一个核心矛盾:很多系统看起来能根据当前截图做一步决策,但一旦任务拉长、界面状态变化、前面步骤的信息需要在后面复用,agent 就很容易丢上下文、重复试错或在某一步之后不可逆失败。
SE-GA 给出的方向不是再堆一个更大的模型,而是把 GUI agent 重新定义成“会记忆、会复盘、会把经验沉淀进策略”的动态学习者。它包含两个关键组件:
- TTME(Test-Time Memory Extension):推理时引入分层记忆,包括 episodic memory、semantic memory、experiential memory。
- MASE(Memory-Augmented Self-Evolution):把 TTME 采集到的经验转成训练数据,通过 grounding 训练和自进化训练改进基础策略。
论文报告的结果也相当直接:基于 7B 模型,SE-GA 在 ScreenSpot 上达到 89.0,AndroidControl-High 成功率达到 75.8%,AndroidWorld 达到 39.0%,并在多轮自进化中持续提升。
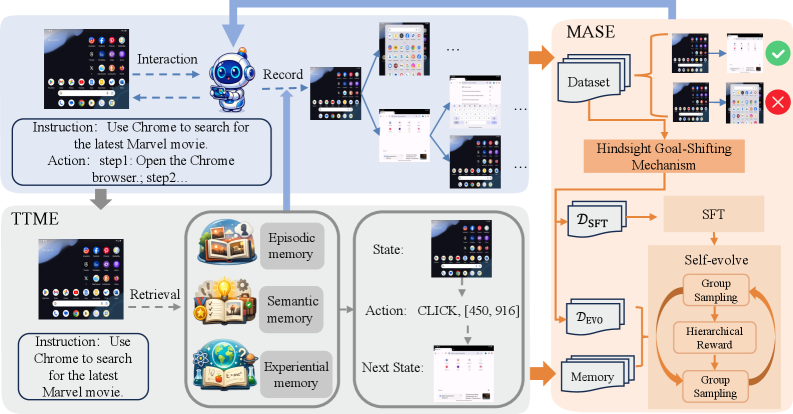
图 1:SE-GA 的整体框架。它先在在线环境中通过 TTME 支持交互与记忆采集,再用 MASE 将这些经验转化为模型策略的改进。
2. 背景与问题定义:GUI agent 为什么会“越做越糊涂”
图形界面智能体的任务看似简单:看屏幕、理解用户目标、点击或输入。但真实 GUI 任务有几个比静态视觉问答更难的特征。
第一,GUI 任务是部分可观测的。当前截图只显示当前状态,不显示用户刚才点过什么、不显示某个弹窗是怎样出现的,也不显示一个列表之前滚动过哪些内容。对人来说,这些信息存在短期记忆里;对 agent 来说,如果上下文窗口有限,信息就会被截断。
第二,GUI 任务具有历史依赖。比如“在一个应用里查到下一场比赛时间,再到待办应用里创建提醒”,后半段的输入依赖前半段查到的信息。早期步骤中观察到的内容,可能在十几步后才真正发挥作用。
第三,GUI 环境是动态且高方差的。页面加载延迟、布局变化、登录状态、弹窗、权限提醒、网络结果差异,都会让固定策略失效。哪怕前面 90% 的动作都正确,最后一步点错也可能导致任务失败。
论文把 GUI navigation 建模为 POMDP。每一步输入不是只有当前观察 o_t 和用户指令 Q,还应包括被检索出来的记忆 M_retrieved:
x_t = (o_t, Q, M_retrieved)
πθ(a_t | x_t)这个建模上的小改动很重要。它意味着 agent 的能力不应只来自“当前屏幕理解”,还应来自“过去交互、通用规则、类似任务经验”的组合。
3. SE-GA 的核心思路
SE-GA 的主张可以概括为一句话:
用显式记忆补齐长程推理,用自进化训练把显式经验压进隐式策略,让 GUI agent 从静态执行器变成动态学习者。
具体来说,它把问题拆成两个层面。
在推理阶段,TTME 负责给模型补充上下文。它不是简单把历史截图全部塞进 prompt,而是把记忆分成三类:
| 记忆类型 | 解决的问题 | 典型内容 |
|---|---|---|
| Episodic memory | 最近发生了什么 | 最近若干步的观察、动作、下一观察 |
| Semantic memory | 通用交互规则是什么 | 登录后才能访问、保存前需要确认等规则 |
| Experiential memory | 过去类似任务怎么做 | 成功轨迹、反思摘要、任务意图与视觉特征 |
在训练阶段,MASE 负责让模型真正“学会经验”。如果只在推理时做检索,agent 仍然依赖外部记忆;一旦检索不准、上下文太长或环境变化,能力就会受限。MASE 的目标是把 TTME 采集到的高质量交互数据转成训练信号,让基础模型本身的 grounding、规划与自纠错能力提升。
4. 方法设计拆解:TTME 分层记忆
TTME 是 SE-GA 中最贴近工程系统的一部分。它不是一个抽象的“长期记忆”概念,而是把不同时间尺度、不同抽象层级的信息分开管理。
4.1 Episodic memory:最近轨迹是工作记忆
Episodic memory 存储最近交互转移:
m_k = <o_k, a_k, o_{k+1}>也就是“某个观察下做了什么动作,之后界面变成什么样”。论文使用滑动窗口保留最近 H 步,避免无限堆历史造成上下文膨胀。
这对长程任务很实用。比如 agent 刚刚在浏览器里查到了一个时间,随后切到提醒应用;如果没有 episodic memory,模型可能只看到提醒应用当前界面,却忘了应该填入什么内容。episodic memory 相当于给 agent 一段短期工作记忆。
4.2 Semantic memory:把经验抽象成规则
Semantic memory 存储的是可复用的抽象规则,例如:
- 访问受限页面前通常需要登录。
- 设置提醒时要确认日期、时间和标题三个字段。
- 表单提交前需要检查必填项是否为空。
这些规则不一定绑定某个具体截图,而是来自历史任务的归纳。论文用文本 encoder 将历史任务意图编码成 key,通过当前用户指令做相似度检索,取出 Top-K 规则作为语义上下文。
这类记忆对产品化很关键。一个 macOS 自动化 agent 不能只记“昨天在这个按钮上点过”,还要能总结“在 Xcode 里运行测试前要确认 scheme 和 target”,“在 Finder 批量移动文件前要确认目标目录是否存在”。这正是 semantic memory 的价值。
4.3 Experiential memory:复用相似任务的成功策略
Experiential memory 更接近“案例库”。每条记忆包含:
m_i^exp = <τ_i, g(τ_i), k_i^intent, k_i^task>其中 τ_i 是原始轨迹,g(τ_i) 是对轨迹的反思摘要,k_i^intent 是任务意图向量,k_i^task 是任务/视觉向量。检索时同时考虑文本意图相似度和视觉任务相似度。
这比单纯按指令文本检索更合理。GUI 任务里,两个指令表面不同,但界面结构和操作路径可能很像;反过来,两个指令文字相似,却可能发生在完全不同的应用环境。混合文本与视觉检索,可以让 agent 找到更有用的历史经验。
4.4 TTME 的工程意义
从工程角度看,TTME 的意义不只是“提高模型效果”,而是给 GUI agent 引入了一套可审计的上下文管理机制:
- agent 为什么做这一步,可以追溯到最近轨迹、规则或历史案例。
- 长任务不必把所有截图粗暴塞进上下文,而是按记忆类型组织。
- 成功轨迹可以被后续训练消费,形成数据闭环。
这对桌面自动化尤其重要。真实用户不会接受一个完全黑盒的 agent 长时间操作电脑;如果系统能展示“本轮决策参考了哪些历史步骤和规则”,可解释性和可调试性会明显更好。
5. 方法设计拆解:MASE 自进化训练
只做记忆检索还不够。很多 RAG-style agent 系统的瓶颈在于:经验永远停留在外部库里,模型本身没有变强。SE-GA 的第二个组件 MASE,就是要把记忆数据转成策略能力。
MASE 分为两个阶段。
第一阶段是 Grounding Training。它使用 TTME 收集到的三元组和记忆上下文进行监督微调,让模型更好地学习“在当前屏幕和任务上下文下,应该选择哪个 GUI 动作”。这一步强化的是基础定位、动作类型和界面理解能力。
第二阶段是 Self-Evolution Training。论文使用 GRPO 风格的强化学习思路,在自进化数据上进一步优化策略。这里的重点不是让模型在无约束环境里盲目探索,而是利用 TTME 已经筛出的轨迹、记忆和结果反馈,降低 GUI 环境高方差带来的训练不稳定。
我比较喜欢这篇论文的一点,是它把“记忆”和“训练”接成了闭环:
- 在线交互产生轨迹。
- TTME 把轨迹组织成 episodic / semantic / experiential memory。
- MASE 从记忆中构造训练信号。
- 改进后的策略再进入下一轮交互。
这比“做一个记忆库,然后每次检索几条相似记录”更进一步。它试图回答:GUI agent 如何随着使用变得更好?
6. 实验结果与结论
论文在离线 grounding benchmark 和在线动态 benchmark 上都做了评测。
6.1 ScreenSpot:7B 模型达到 89.0
在 ScreenSpot 上,SE-GA 使用 7B 模型达到 89.0 平均分。对比同为 7B 规模的模型:
- Qwen2.5VL-7B:76.1
- UGround-7B:71.5
- OS-Atlas-7B:82.5
- Aguvis-7B:84.4
- SE-GA-7B:89.0
更有意思的是,SE-GA 在 Mobile / Desktop / Web 的 text 与 icon 子项上都比较均衡,说明它不只是针对某个单一平台做了优化。
6.2 AndroidControl / GUIOdyssey:长程任务收益明显
在 AndroidControl-High 上,SE-GA 的成功率达到 75.8%;在 GUIOdyssey 上达到 83.9%。论文的消融实验显示:
| 模型 | AndroidControl-High SR | GUIOdyssey SR |
|---|---|---|
| SE-GA | 73.8 / 75.8(文中不同表格口径略有差异) | 83.9 |
| w/o TTME | 61.4 | 74.9 |
| w/o MASE | 59.7 | 60.4 |
这里最值得关注的是:去掉 TTME 或 MASE 都会明显下降。TTME 对长程任务的在线上下文管理很关键;MASE 则显著提升模型底层 grounding 与规划能力。
6.3 AndroidWorld:动态环境泛化提升
在 AndroidWorld 上,论文报告的结果是:
| 模型 | AndroidWorld |
|---|---|
| GPT-4o | 23.7 |
| Qwen2.5-VL-7B | 25.5 |
| OS-Genesis-7B | 17.4 |
| GUI-Critic-R1-7B | 27.6 |
| UI-TARS-7B | 33.0 |
| SE-GA-7B | 39.0 |
AndroidWorld 更接近动态真实环境,因此 39.0 这个结果说明:记忆和自进化不只是提高静态点击定位,也能改善多步任务中的稳定性。
6.4 多轮自进化:不是一次性训练,而是持续提升
论文还给出多轮 self-evolution 的结果:
| Benchmark | Round 1 | Round 2 | Round 3 |
|---|---|---|---|
| ScreenSpot | 79.3 | 86.0 | 89.0 |
| AndroidControl-Low | 68.3 | 75.5 | 88.6 |
| AndroidControl-High | 55.9 | 71.3 | 75.8 |
| GUIOdyssey | 52.3 | 75.1 | 83.9 |
| AndroidWorld | 28.6 | 34.5 | 39.0 |
这组数字支撑了论文的核心叙事:SE-GA 不是单次训练出的静态 agent,而是可以通过记忆增强的自进化持续变强。
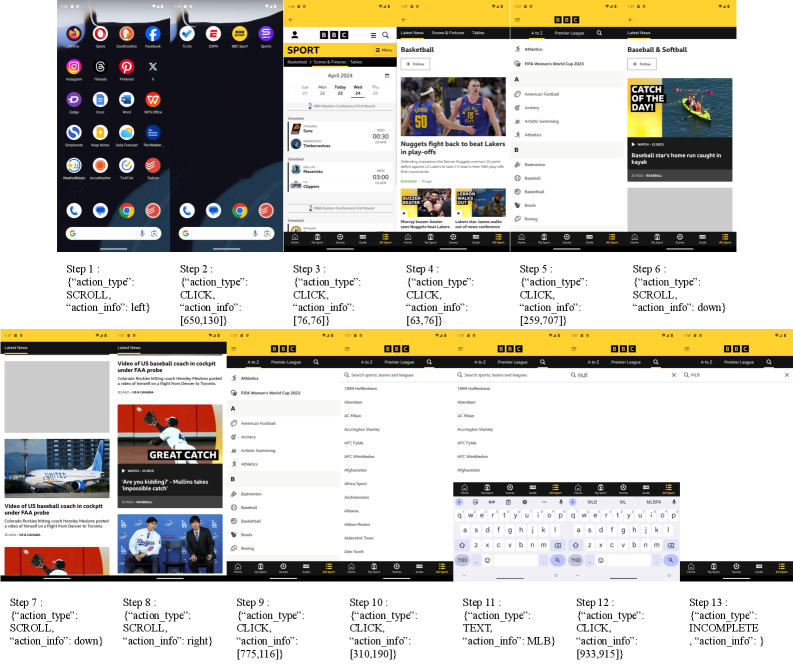
图 2:论文中的失败轨迹示例。任务跨多个应用和步骤,早期信息与后续动作强相关;一旦中间环节丢失关键信息,后续操作会持续偏离目标。
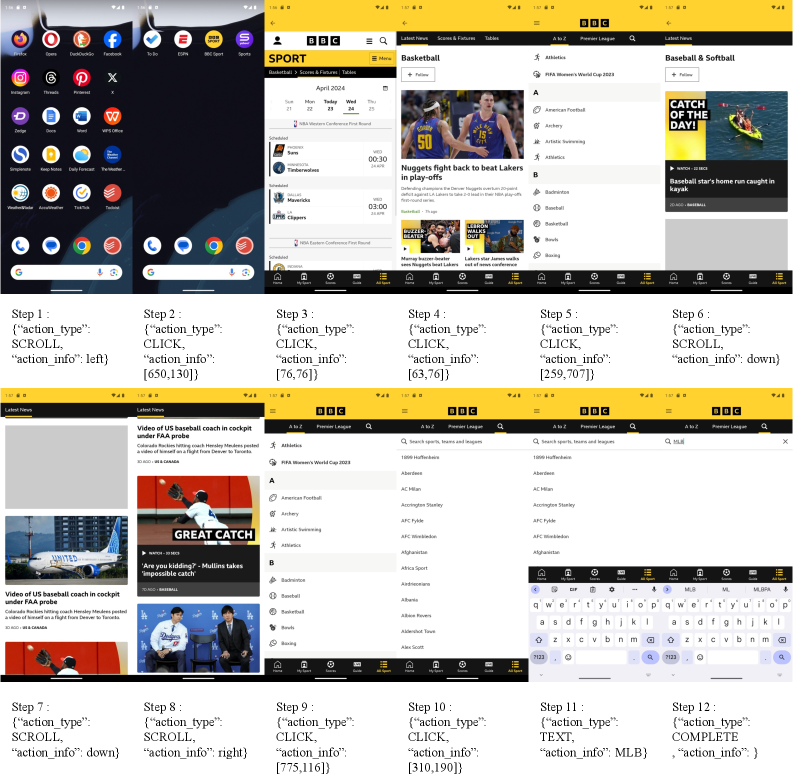
图 3:论文中的成功轨迹示例。SE-GA 能利用历史交互与反思经验,重新组织目标并完成一段更可靠的操作序列。
7. 对 macOS 研发效率工具和 GUI 自动化的启发
我最关心的是:这篇论文对 macOS 研发效率工具、桌面自动化和 computer-use 产品有什么启发?
7.1 研发工具 agent 需要“任务记忆”,不只是聊天记忆
很多桌面 agent 现在的记忆更像聊天摘要:用户偏好、常用项目、历史对话。但 SE-GA 提醒我们,GUI 自动化更需要的是任务记忆:
- 刚才在哪个窗口执行过什么命令?
- 哪个测试 target 失败了?
- 哪个文件被打开、修改、保存?
- 某个 IDE 面板当前处于什么状态?
对 macOS 研发效率工具来说,episodic memory 可以记录最近窗口、应用、文件和操作结果;semantic memory 可以沉淀“构建前检查依赖”“提交前运行测试”等规则;experiential memory 可以保存“类似 bug 修复流程”“类似发布流程”的成功轨迹。
7.2 把“操作轨迹”当成一等数据资产
SE-GA 的闭环说明,GUI agent 的每次成功执行都不应只是一次性消耗。对工程产品来说,每条成功轨迹都可以被结构化为:
任务目标 -> 环境状态 -> 操作步骤 -> 中间观察 -> 最终结果 -> 反思摘要这类数据可以用于:
- 后续相似任务的检索增强。
- 生成自动化脚本或快捷指令。
- 训练更小的本地模型。
- 做回放、审计和错误定位。
如果把 macOS 上的 Finder、Terminal、Xcode、浏览器、设计工具、内部平台都看成 GUI 环境,那么“轨迹数据”会成为比 prompt 模板更长期、更有复利的资产。
7.3 外部记忆适合产品早期,策略内化适合规模化
SE-GA 的 TTME + MASE 也对应产品演进路线。
早期可以先做外部记忆:记录用户行为、检索历史案例、把相关上下文塞给模型。这上线快、可解释、容易调试。
但当任务规模变大后,仅依赖外部检索会遇到延迟、成本、检索偏差和上下文长度问题。此时需要 MASE 式的能力内化:把高频、稳定、可验证的 GUI 操作模式训练进模型或小型策略模块中。
这对端侧 macOS agent 特别重要。很多操作如果都走云端大模型,不仅慢,也有隐私和成本问题。更现实的路线是:大模型负责规划与反思,小模型或本地策略负责高频 GUI grounding 与动作执行。
7.4 记忆必须可审计、可删除、可分域
当然,记忆越强,治理越重要。GUI agent 处理的是用户真实电脑环境,记忆里可能包含文件名、路径、账号状态、内部系统界面等敏感信息。
因此产品设计上至少要考虑:
- 不同应用、项目、组织之间的记忆隔离。
- 用户可查看、删除、禁用特定记忆。
- 对包含隐私信息的截图和轨迹做脱敏或本地存储。
- 关键动作前给出“本次决策参考了哪些记忆”的解释。
- 对高风险动作保持人工确认,而不是让自进化策略无约束执行。
SE-GA 论文主要讨论性能,但真正落地时,记忆系统的权限边界和审计能力会和模型效果同等重要。
8. 局限性与我的点评
这篇论文的方向很有价值,但也有几个需要冷静看待的点。
第一,自进化数据质量决定上限。如果 TTME 收集到的轨迹本身有偏差,或者成功判定不可靠,MASE 可能会把错误模式固化进策略。GUI 环境里“看起来完成”和“真正完成”并不总是一回事,尤其涉及文件修改、支付、发布、删除等任务时,需要更强的验证器。
第二,记忆检索会引入新的失败模式。相似任务不代表相同任务。一个历史经验如果被错误召回,可能会让 agent 坚持错误路径。论文也比较了不同检索策略,说明 retrieval policy 本身就是系统关键组件。
第三,多轮自进化的安全边界还不够清晰。从研究角度看,agent 越用越强是好事;从产品角度看,agent 自我改进必须有版本管理、回滚、评测门禁和用户授权。尤其是桌面自动化场景,策略更新不能绕过可验证测试。
第四,实验主要集中在 Android / GUI benchmark。这对移动 GUI agent 很有说服力,但桌面端、macOS、多窗口、多显示器、文件系统、开发工具链等场景仍然复杂得多。SE-GA 的记忆思想可以迁移,但工程实现不会是直接照搬。
我的总体判断是:SE-GA 的价值不在于某一个 benchmark 数字,而在于它给 GUI agent 研究补上了一个重要拼图——从“会执行当前任务”走向“会积累可复用经验,并通过经验改进自己”。 这正是 computer-use agent 从 demo 走向长期助手时必须跨过的门槛。
9. 总结
SE-GA 把 GUI agent 的问题从“当前截图该点哪里”推进到“如何在长程、动态、部分可观测环境中持续学习”。
它的核心贡献可以总结为三点:
- TTME 分层记忆:用 episodic、semantic、experiential 三类记忆补齐长程上下文与历史经验。
- MASE 自进化训练:把推理时收集的记忆数据转化为 grounding 和策略改进。
- 实验验证持续提升:在 ScreenSpot、AndroidControl、GUIOdyssey、AndroidWorld 上取得强结果,并展示多轮 self-evolution 的收益。
对工程落地来说,这篇论文的启发非常明确:未来的 GUI agent 不应只是“调用大模型看屏幕并点击”,而应该有一套完整的运行时记忆系统、轨迹数据闭环、可审计的经验检索,以及受控的策略内化机制。
如果我们要做面向 macOS 研发效率的 computer-use agent,SE-GA 提供了一个很好的架构隐喻:把每次成功的 GUI 操作都变成下一次更可靠执行的燃料。