Open Code Review:把 AI 代码审查拆成确定性流水线
拆解 alibaba/open-code-review:它不是简单把 diff 丢给模型,而是用文件筛选、规则匹配、并发子任务、专用工具、评论定位和会话记录,把 Agent 约束进一条可观测的审查流水线。
项目:alibaba/open-code-review
分析版本:main 分支fb81951
一句话结论:Open Code Review 的重点不是“让模型会审代码”,而是把代码审查这件事拆成一条确定性流水线,再把真正需要语义判断的部分交给 Agent。
先说它在解决什么
Open Code Review,简称 OCR,是阿里开源的一款 AI 代码审查 CLI。它可以审查工作区变更、分支范围变更或单个 commit,输出精确到行号的 review comment,也能以 JSON 形式接入 CI。
如果只看 README,很容易把它理解成“读取 git diff,然后调用 LLM 做 review”。但源码里真正值得拆的地方不在模型调用,而在它给模型加了很多硬边界:
- 哪些文件进入审查,由扩展名、默认排除规则和用户规则决定。
- 每个文件独立变成一个 subtask,默认并发执行。
- 大 diff 先跑 plan phase,小 diff 跳过计划,直接进入主审查。
- 主审查只暴露少量代码审查专用工具,而不是通用 shell。
- 模型提交评论时不直接决定行号,只提交
existing_code,行号由 diff 匹配和 re-location 模块确定。 - 所有 LLM request、response、tool call 都写入本地 JSONL session,后续 viewer 可以回看。
这套取舍很像把一个容易发散的通用 Agent,压进代码审查这个场景的轨道里:工程逻辑负责范围、规则、并发、定位和记录;模型负责阅读上下文、判断风险、写出评论。
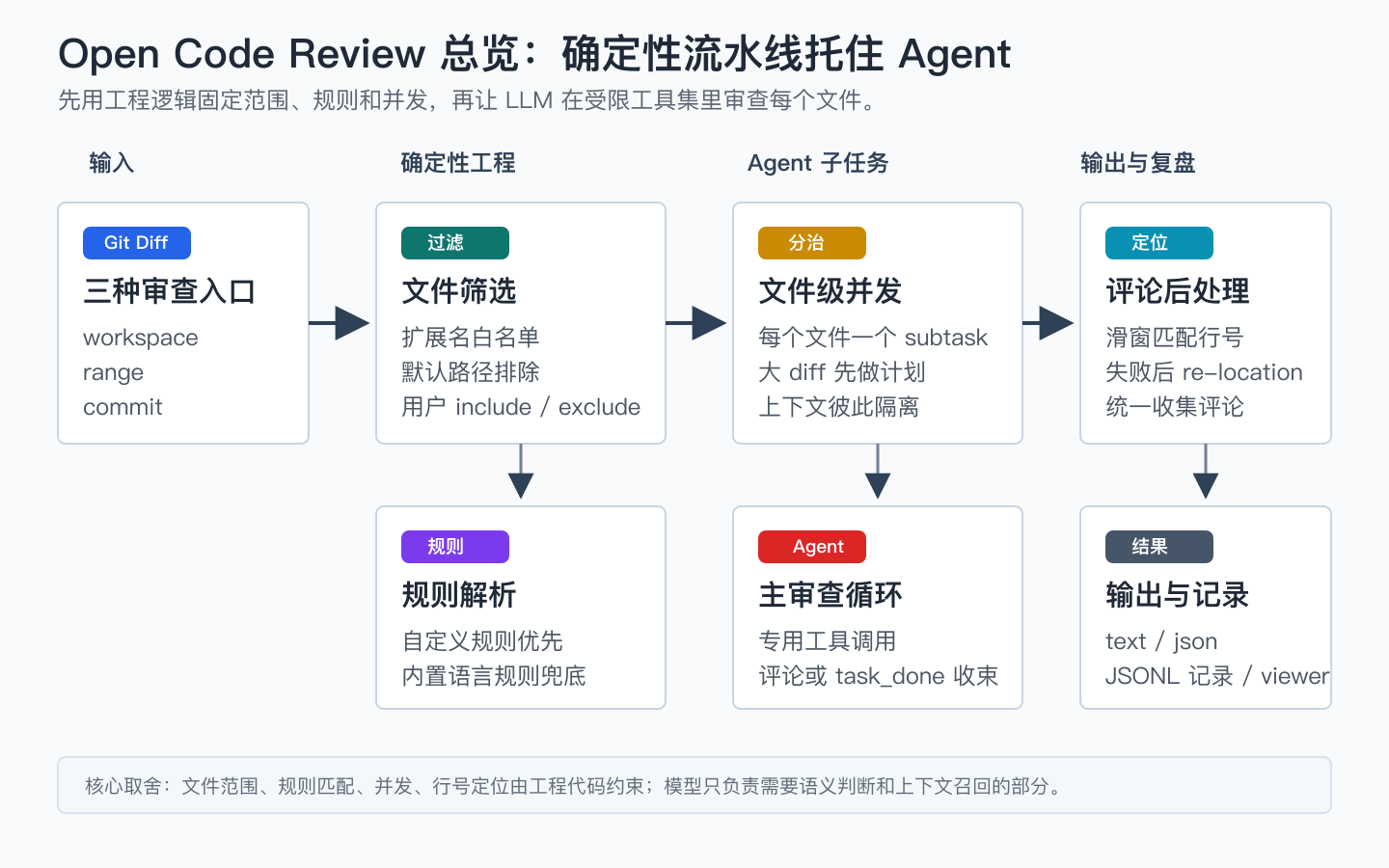
图 1:OCR 的核心不是单次 LLM 请求,而是“Git diff -> 文件筛选 -> 规则匹配 -> 文件级 Agent 子任务 -> 评论定位 -> 输出和记录”的流水线。
CLI 入口:review 命令先把依赖装好
入口在 cmd/opencodereview/main.go。顶层命令很薄,ocr review 和 ocr r 都会走 runReview:
case "review", "r":
return runReview(args[1:])真正的组装发生在 cmd/opencodereview/review_cmd.go。这里会依次加载模板、规则、工具配置、LLM endpoint、git runner、comment collector,最后创建 agent.Agent:
tpl, err := template.LoadDefault()
resolver, fileFilter, err := rules.NewResolver(repoDir, opts.rulePath)
toolEntries, err := toolsconfig.Load(opts.toolConfigPath)
ep, err := llm.ResolveEndpoint(cfgPath)
llmClient := llm.NewLLMClient(ep)这几行已经能看出 OCR 的设计气质:模型只是最后一个依赖。模型之前,它先确定审查模板、规则解析器、文件过滤器、工具定义和 git 执行器。
agent.New(...) 里传进去的东西也很完整:
ag := agent.New(agent.Args{
RepoDir: repoDir,
Template: *tpl,
SystemRule: resolver,
FileFilter: fileFilter,
LLMClient: llmClient,
Tools: tools,
})所以 ocr review 不是“命令行包装一个 prompt”。它更像一个代码审查运行时:先把审查环境固定下来,再让 Agent 在这个环境里工作。
Diff 来源:workspace、range、commit 三种模式
OCR 的 diff 获取在 internal/diff/git.go。它支持三种模式:
| 模式 | 触发方式 | 实现含义 |
|---|---|---|
| workspace | ocr review | 读取 tracked diff,并补上 untracked 文件 |
| range | --from main --to branch | 先算 merge-base,再 diff 到目标分支 |
| commit | --commit abc123 | 用 git show 审单个 commit |
源码里对应得很直接:
case ModeRange:
base := p.MergeBase(ctx)
out, err := p.runGit(ctx, "diff", "--no-color", "-U3", base, p.to, "--")
case ModeCommit:
out, err := p.runGit(ctx, "show", "--no-color", "-U3", p.commit)
case ModeWorkspace:
tracked, err := p.workspaceTrackedDiff(ctx)
untracked, err := p.untrackedFileDiffs(ctx)这里有个容易忽略的点:workspace 模式会审 untracked files。这在日常使用里很重要。如果你只想审暂存区,OCR 默认行为并不是“只看 staged”。它会把当前工作区里未跟踪的新文件也合成 diff。
解析 diff 时,OCR 还会读取新版本文件全文:
finalizeDiff(ctx, current, repoDir, ref, runner)
d.NewFileContent = string(content)这不是多余信息。后面评论行号定位时,如果 diff hunk 里匹配不上 existing_code,还会回退到 NewFileContent 做全文扫描。
文件筛选:先决定“哪些文件值得审”
Agent.Run 的第一步是加载 diff,然后在进入 LLM 前做筛选:
if err := a.loadDiffs(ctx); err != nil {
return nil, fmt.Errorf("load diffs: %w", err)
}
a.injectDiffMap()
a.args.Tools.Freeze()
a.diffs = a.filterDiffs(a.diffs)文件是否进入审查,由 internal/agent/preview.go 里的 whyExcluded 决定:
if d.IsBinary {
return ExcludeBinary
}
if f != nil && f.IsUserExcluded(path) {
return ExcludeUserRule
}
if ext != "" && !allowedext.IsAllowedExt(ext) {
return ExcludeExtension
}
if allowedext.IsExcludedPath(path) {
return ExcludeDefaultPath
}翻译成人话是四层过滤:
- 二进制文件不审。
- 用户 exclude 命中的文件不审。
- 扩展名不在支持列表里不审。
- 默认排除路径不审,比如
.git/、node_modules/、vendor/、target/等。
ocr review --preview 复用同一套算法,只是不调用 LLM。这个命令很实用,因为它能提前告诉你哪些文件会审、哪些会被过滤。
规则系统:不是一份大 prompt,而是按路径匹配
OCR 的内置规则在 internal/config/rules/system_rules.json。它不是把所有语言规则塞进一个 prompt,而是按路径匹配不同规则文档:
"path_rule_map": {
"**/*.properties": "properties.md",
"**/pom.xml": "pom_xml.md",
"**/*.java": "java.md",
"**/*.{ts,js,tsx,jsx}": "ts_js_tsx_jsx.md"
}规则解析器在 internal/config/rules/system_rules.go。默认系统规则之外,还支持项目和用户自定义规则:
// 1. Custom rule file specified via --rule flag
// 2. Project-local .opencodereview/rule.json
// 3. Global ~/.opencodereview/rule.json
// 4. Embedded system default rules
func NewResolver(repoDir, customRulePath string) (Resolver, *FileFilter, error)实际 resolve 时是 “first match wins”:
for _, pr := range r.PathRules {
if matched, _ := doublestar.Match(p, path); matched {
return pr.Rule
}
}
return r.DefaultRule这就是 README 里说“精细化规则匹配”的工程落点。模型看到的不是一份包罗万象的代码审查宝典,而是当前文件路径对应的规则片段。
比如 Java 规则文档会强调 NPE、死代码、边界条件、数据库循环查询、线程安全;TS/JS/React 规则会强调 any、==、Hooks、XSS、innerHTML、异步错误处理。规则越贴近文件类型,模型越不需要在无关 checklist 里分神。
分治:每个文件一个 subtask
Agent.Run 的核心注释已经把流程写得很清楚:
// Run executes the full review pipeline:
// parse diffs -> plan per file -> LLM tool-loop -> collect comments.
func (a *Agent) Run(ctx context.Context) ([]model.LlmComment, error)真正并发是在 dispatchSubtasks:
concurrency := a.args.MaxConcurrency
if concurrency <= 0 {
concurrency = 8
}
sem := make(chan struct{}, concurrency)
go func(d model.Diff) {
if err := a.executeSubtask(fileCtx, d); err != nil {
a.recordWarning("subtask_error", d.NewPath, err.Error())
}
}(a.diffs[i])这个设计解决了通用 Agent 审大 diff 时最常见的两个问题。
第一是覆盖率。每个被筛选后的文件都会被派发一个 subtask,不靠模型自己“决定先看哪些文件”。模型不会因为变更太多而只审前几个文件。
第二是上下文隔离。每个文件的主 prompt 都只围绕当前 diff、当前文件规则、其他变更文件列表和可选 plan。它不会把所有文件的细节混在一个超长上下文里。
当然,分治也有代价:跨文件语义问题只能通过工具补上下文。OCR 的做法不是让每个 subtask 天然拥有所有文件全文,而是提供 file_read_diff、file_read、code_search 等工具,让模型在怀疑问题时主动查。
单文件流程:先计划,再进入工具循环
一条文件级 subtask 由 executeSubtask 驱动。它先计算当前文件的其他变更列表、匹配规则,再决定是否运行 plan phase:
rule := a.resolveSystemRule(strings.ToLower(newPath))
threshold := a.args.Template.PlanModeLineThreshold
changeLines := d.Insertions + d.Deletions默认模板里,PLAN_MODE_LINE_THRESHOLD 是 50。源码里的判断是:如果配置了 plan task,且当前变更行数低于阈值,就跳过计划阶段:
if threshold > 0 && changeLines < int64(threshold) {
fmt.Fprintf(stdout.Writer(), "[ocr] Skipping plan phase for %s", newPath)
} else {
planResult, err = a.executePlanPhase(...)
}这点很务实。小改动先跑计划会增加延迟,也未必增加质量;大改动先让模型列风险点和工具策略,主审查时就更像“按计划排查”。
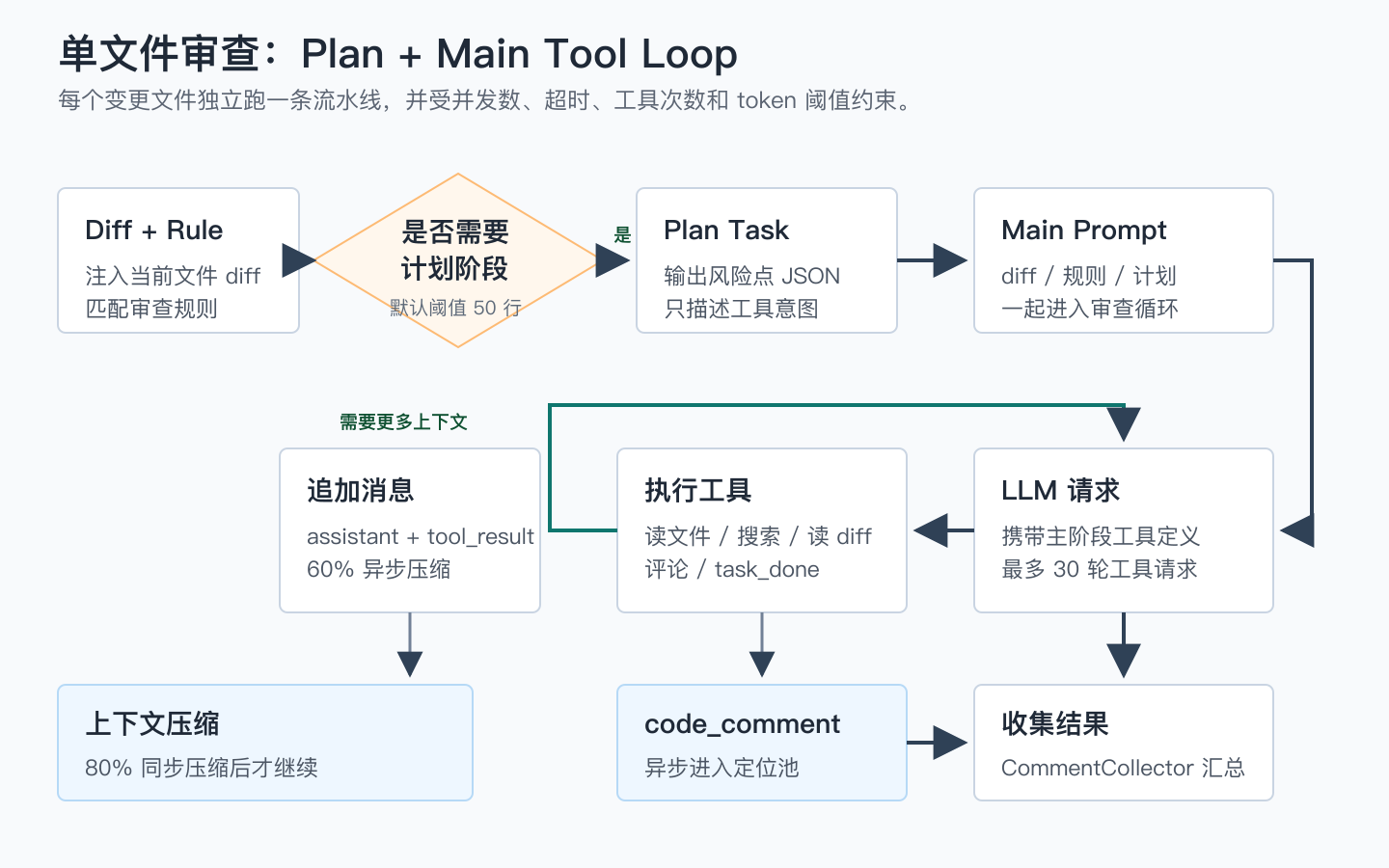
图 2:每个文件先进入 Diff + Rule 准备阶段;大 diff 会多跑一次 Plan Task;Main Task 通过工具循环获取上下文、提交评论或调用 task_done。
Plan Task 的 prompt 要求输出 JSON,里面包括 change_summary 和按 severity 排序的 issues。但它明确规定工具只做参考,不真的调用:
Tools are for reference purposes only and must not be actually invoked;
describe the calling intent within tool_guidance这说明 plan phase 不是一个 agent loop,它只是审查前的风险分析。真正调用工具的是 Main Task。
主审查循环:工具很少,但足够贴合场景
OCR 的主阶段工具定义来自 internal/config/toolsconfig/tools.json,最终通过 BuildToolDefs 转成 LLM tool schema:
func BuildToolDefs(entries []toolsconfig.ToolConfigEntry, planOnly bool) []llm.ToolDef {
for _, e := range entries {
defRaw, ok := e.ToolDefsByPhase(planOnly)
defs = append(defs, llm.ToolDef{Type: "function", Function: fn})
}
}工具注册在 buildToolRegistry:
reg.Register(tool.NewFileRead(fr))
reg.Register(tool.NewFileFind(fr))
reg.Register(tool.NewFileReadDiff(tool.DiffMap{}))
reg.Register(tool.NewCodeSearch(fr))
reg.Register(&tool.CodeCommentProvider{Collector: collector})加上 task_done,OCR 的主审查工具集其实很克制:
| 工具 | 用途 |
|---|---|
file_read | 读变更后的文件内容 |
file_find | 按文件名关键词找文件 |
file_read_diff | 读取其他变更文件的 diff |
code_search | 在代码库里搜索上下文 |
code_comment | 提交结构化 review comment |
task_done | 当前文件审查完成 |
这和通用 coding agent 最大的区别是:它没有给模型 shell、写文件、改文件这类能力。OCR 要的是审查,不是修复。所以工具越少,越容易控制输出质量和风险面。
主循环在 performLlmCodeReview:
for toolReqCount > 0 {
resp, err := a.args.LLMClient.CompletionsWithCtx(ctx, llm.ChatRequest{
Messages: messages,
Tools: a.args.MainToolDefs,
})
calls := resp.ToolCalls()
}如果模型没有成功调用任何工具,OCR 会追问一次:
messages = append(messages,
llm.NewTextMessage("user", "You did not successfully call any tools. Please try again or use task_done if finished."))这是一种很具体的行为约束:主阶段不是让模型随便回复一段自然语言,而是要求它要么调用 code_comment,要么调用上下文工具继续查,要么调用 task_done 结束。
code_comment:评论不是直接写行号
code_comment 的 schema 要求模型提交 content 和 existing_code:
{
"content": "Comment content",
"existing_code": "Code snippet used to locate comment position",
"suggestion_code": "Corresponding suggested code snippet"
}注意这里没有让模型手填 start_line。这很关键,因为行号漂移是 AI code review 最常见的痛点之一。OCR 的做法是让模型提供一段最相关的新增代码片段,然后由工程代码定位。
executeToolCall 里对 code_comment 做了特殊处理:
comments, errMsg := tool.ParseComments(args)
for i := range comments {
cm := &comments[i]
d := a.findDiff(cm.Path)
if d != nil {
if !diff.ResolveComment(cm, d) {
diff.ReLocateComment(...)
}
}
a.args.CommentCollector.Add(*cm)
}这里做了三件事:
- 解析模型提交的 comment。
- 用 diff 定位
existing_code对应的行号。 - 定位失败时,调用 re-location task 让模型从 diff 里重新抽取最小代码片段,再定位一次。
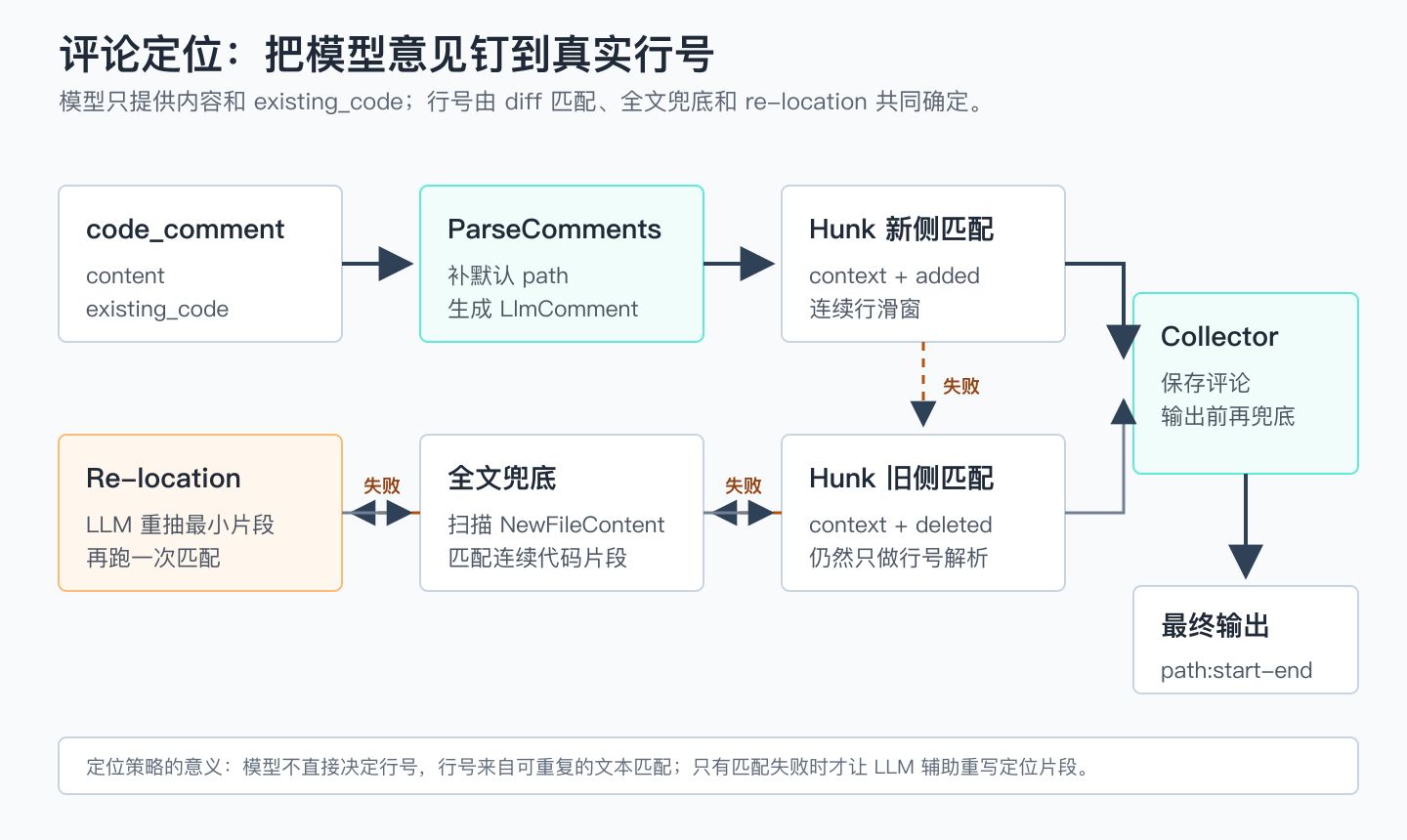
图 3:模型给出的是评论内容和 existing_code;行号由 hunk 新侧、hunk 旧侧、全文扫描和 re-location 逐级兜底。
diff.ResolveComment 的第一优先级是 hunk 新侧匹配:
newSide := extractSideLines(&hunks[i], true)
if start, end, ok := matchConsecutive(newSide, targetLines); ok {
cm.StartLine = start
cm.EndLine = end
return true
}如果新侧失败,再尝试旧侧;如果还是失败,就扫描新文件全文:
if resolveFromHunk(d, cm) {
return true
}
return resolveFromFileContent(d, cm)re-location prompt 更窄,只要求从 diff 和评论中抽出最小连续代码块:
Identify the minimal contiguous code range in the diff that the comment targets.
Output ONLY a fenced code block.这个模块的边界也很清楚:re-location 不是重新审查代码,它只负责把一个已经生成的评论重新定位到 diff 中的片段。
上下文压缩:长循环不直接撞 token 墙
主审查循环里,工具调用会不断追加 assistant 和 tool result。OCR 没有等到上下文爆掉才失败,而是做了双阈值压缩:
const (
tokenSoftThreshold = 0.60
tokenWarningThreshold = 0.80
)addNextMessage 的逻辑是:
if tokenCount > warnLimit {
*messages, _ = a.runCompression(ctx, *messages, filePath)
}
if tokenCount > softLimit && a.pendingJob == nil {
a.triggerAsyncCompression(ctx, *messages, filePath)
}60% 时后台异步压缩,80% 时同步压缩。压缩不是简单裁掉历史,而是保留前两条系统/用户消息,把中间工具轮次摘要成 <previous_review_summary>,再保留最近活跃轮次。
这也是一个典型的“Agent 工程化”细节:模型可以查上下文,但工具循环不能无限膨胀;压缩要能继续审查,而不是把前面结论全部丢掉。
会话记录和 viewer:把审查过程留下来
OCR 每次运行都会创建 SessionHistory。默认写到:
~/.opencodereview/sessions/<encoded-repo-path>/<session-id>.jsonl写入逻辑在 internal/session/persist.go,记录类型包括:
session_startllm_requestllm_responsellm_errortool_callsession_end
比如 LLM response 会记录模型、内容、工具调用、耗时和 token:
rec := map[string]any{
"type": "llm_response",
"filePath": filePath,
"taskType": string(taskType),
"tool_calls": toolCalls,
"usage": map[string]int{...},
}ocr viewer 则会扫描这些 JSONL:
func SessionsRoot() (string, error) {
return filepath.Join(home, ".opencodereview", "sessions"), nil
}这对调试 AI review 很重要。审查质量不稳定时,你可以回看某个文件的 plan、main task、工具调用、re-location 和压缩记录,而不是只看到最后一句“这里有问题”。
LLM 适配:Anthropic 和 OpenAI-compatible 都能走
OCR 的 LLM 配置解析在 internal/llm/resolver.go。优先级是:
~/.opencodereview/config.jsonOCR_LLM_URL/OCR_LLM_TOKEN/OCR_LLM_MODELANTHROPIC_BASE_URL/ANTHROPIC_AUTH_TOKEN/ANTHROPIC_MODEL- shell rc 文件里的 Anthropic export
源码里的策略列表很直接:
strategies := []struct {
name string
fn func() (ResolvedEndpoint, bool, error)
}{
{"OCR config file", tryOCRConfig},
{"OCR environment", tryOCREnv},
{"Claude Code environment", tryCCEnv},
{"Shell rc file", tryShellRC},
}最终 NewLLMClient 根据 protocol 创建 Anthropic 或 OpenAI client:
if ep.Protocol == "anthropic" {
return NewAnthropicClient(cfg)
}
return NewOpenAIClient(cfg)这解释了为什么 README 里说它兼容 OpenAI 和 Anthropic,也兼容 Claude Code 的环境变量。OCR 自己并不绑定某个 coding agent,它只需要一个可用的模型 endpoint。
集成层:CLI 是内核,Skill / Plugin / CI 是包装
仓库里除了 Go CLI,还有几层集成:
bin/ocr.js和package.json:把二进制包装成 npm 包。skills/open-code-review/SKILL.md:给通用 coding agent 使用的 Skill。plugins/open-code-review/commands/review.md:Claude Code 插件命令。plugins/open-code-review/skills/open-code-review/SKILL.md:Codex 插件技能。examples/github_actions/、examples/gitlab_ci/:CI 集成示例。
Skill 文件里有一句很能说明定位:
ocr review --audience agent --background "business context here" [user-args]--audience agent 会抑制进度 UI,只输出适合 Agent 继续处理的摘要;--background 则把需求背景注入到模板里的 {{requirement_background}}。也就是说,集成层不是重写审查逻辑,而是围绕同一个 CLI 调用约定做包装。
它容易被误解的几个点
第一,OCR 不是静态分析器。规则文档里会写 NPE、XSS、SQL 注入、线程安全等检查项,但真正判断仍由 LLM 完成。它提供的是“规则聚焦 + 工具取证 + 位置校准”,不是传统编译器级别的确定性告警。
第二,OCR 也不是通用 coding agent。它不提供 shell、edit、write 这类工具,主任务被限制在代码审查需要的读、搜、读 diff、评论和结束。这个限制反而是它稳定性的来源。
第三,行号定位并不完全依赖模型。模型提交的是 existing_code,工程代码负责把它匹配到 diff 或新文件全文。只有定位失败时,才让 re-location LLM 辅助重新抽片段。
第四,大 diff 不是无限塞上下文。文件 diff 单独超过 MAX_TOKENS 80% 会被预过滤;工具循环超过 60% / 80% token 阈值会压缩上下文。它宁愿跳过或压缩,也不硬撞模型窗口。
第五,workspace 模式会包含 untracked files。这个默认行为对本地使用很方便,但如果你只想审一小块改动,需要用分支范围、commit 或规则过滤收窄范围。
源码索引
如果继续读源码,我建议按这个顺序:
| 关注点 | 文件 |
|---|---|
| CLI 入口 | cmd/opencodereview/main.go、cmd/opencodereview/review_cmd.go |
| review 参数 | cmd/opencodereview/flags.go |
| diff 获取 | internal/diff/git.go、internal/diff/parser.go |
| Agent 主流程 | internal/agent/agent.go |
| preview / 文件过滤 | internal/agent/preview.go、internal/config/allowlist/allowed_ext.go |
| 规则匹配 | internal/config/rules/system_rules.go、internal/config/rules/system_rules.json |
| Prompt 模板 | internal/config/template/task_template.json |
| 工具定义 | internal/config/toolsconfig/tools.json、internal/tool/definitions.go |
| 评论定位 | internal/diff/resolver.go、internal/diff/relocation.go |
| 会话记录 | internal/session/history.go、internal/session/persist.go |
| viewer | internal/viewer/store.go、internal/viewer/server.go |
| LLM 适配 | internal/llm/resolver.go、internal/llm/client.go |
| Agent 集成 | skills/open-code-review/SKILL.md、plugins/open-code-review/commands/review.md |
总结
Open Code Review 最值得借鉴的地方,是它没有把“AI 代码审查”做成一个更长的 prompt。
它把流程里不能飘的部分拆出来:diff 范围、文件过滤、规则匹配、并发调度、工具列表、评论定位、token 压缩、session 记录。然后只把那些确实需要语义理解的动作交给 LLM:读上下文、判断风险、生成评论、必要时辅助重定位。
所以它的架构答案其实很朴素:不是让 Agent 更自由,而是让 Agent 只在该自由的地方自由。