Video2GUI:把互联网教程视频变成 GUI Agent 的预训练燃料
解析 ICML 2026 论文 Video2GUI:如何从 5 亿级视频元数据中自动筛选教程视频,构建 WildGUI 大规模交互轨迹数据集,并用它提升 GUI grounding 与 computer-use agent 泛化能力。
目录
- 为什么这篇论文值得关注
- 背景与问题定义:GUI agent 真正缺的是“规模化真实轨迹”
- Video2GUI 的核心思路
- 方法设计拆解:从视频到可训练轨迹
- WildGUI 数据集与训练方案
- 实验结果与结论
- 对 macOS 研发效率工具和 GUI 自动化的启发
- 局限性与我的点评
- 总结
- 参考链接
1. 为什么这篇论文值得关注
今天选的论文是 ICML 2026 的 Video2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining。
- 论文地址:https://arxiv.org/abs/2605.14747
- PDF:https://arxiv.org/pdf/2605.14747
- 项目主页:https://weiminxiong.github.io/Video2GUI/
- 代码仓库:https://github.com/WeiminXiong/Video2GUI
- 作者:Weimin Xiong、Shuhao Gu、Bowen Ye、Zihao Yue、Lei Li、Feifan Song、Sujian Li、Hao Tian
- 机构:北京大学、小米 LLM-Core、香港大学、中国人民大学
- 时间:arXiv:2605.14747v1,2026 年 5 月 14 日;ICML 2026 接收
如果说过去一年 GUI agent 的研究重点是“怎么让模型点得更准、走得更稳”,那么 Video2GUI 关注的是更底层的问题:我们有没有足够多、足够真实、足够多样的 GUI 交互数据,去训练一个能跨 Web、桌面、移动端泛化的图形界面智能体?
论文给出的答案非常直接:互联网上已经有海量软件教程、网页操作、手机应用演示视频,只是它们没有被整理成 agent 可以学习的结构化轨迹。Video2GUI 的贡献,就是提出一条自动化流水线,把这些未标注视频变成带任务指令、动作序列和空间定位的 GUI 训练样本,并最终构建出 WildGUI:包含约 12.7M 条交互轨迹、124.5M 张截图、覆盖 1,500+ 应用和网站的大规模预训练数据集。
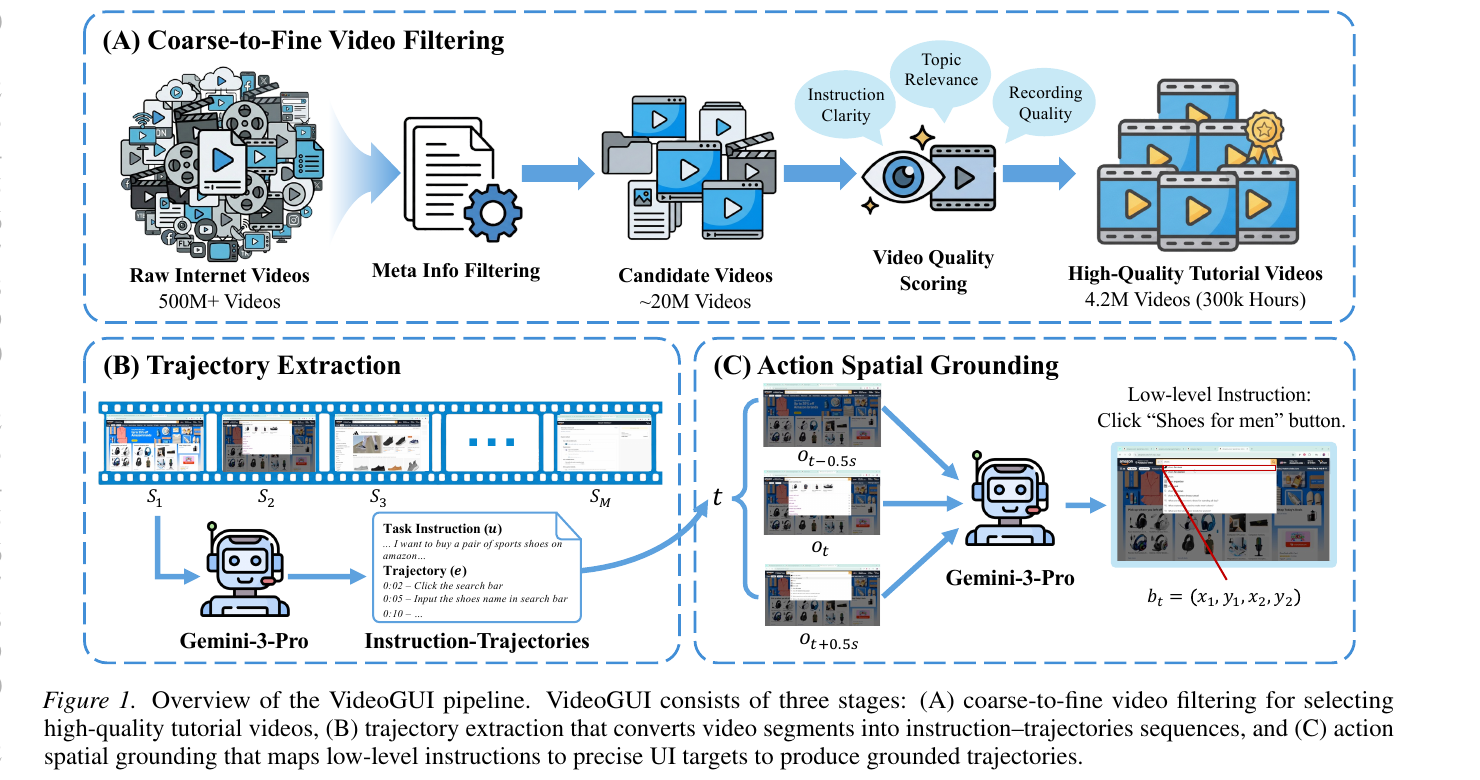
图 1:Video2GUI 的核心想法。互联网上的教程视频本来是给人看的,但经过筛选、轨迹抽取和动作 grounding 后,可以转化为 GUI agent 的预训练语料。
2. 背景与问题定义:GUI agent 真正缺的是“规模化真实轨迹”
GUI agent / computer-use agent 的目标,是让模型像人一样观察屏幕、理解任务,并通过点击、输入、滚动、拖拽、返回等动作完成跨应用任务。这个方向已经有不少基准和系统,例如 ScreenSpot、OSWorld、AndroidControl、AndroidWorld 等,也有大量方法围绕 GUI grounding、动作生成、长程规划和自纠错展开。
但数据仍然是一个绕不开的瓶颈。
现有 GUI 数据通常来自几类渠道:人工录制轨迹、众包标注、模拟环境、特定 App 的规则生成任务、或从网页 DOM / 移动端无障碍树中构造监督信号。这些方式都很有价值,但也存在明显限制:
- 人工标注贵:要同时标注任务意图、截图状态、动作类型、坐标或元素目标,成本远高于普通文本数据。
- 领域覆盖窄:很多数据集只覆盖移动端、网页或少数应用,模型容易学习到平台特定模式。
- 真实分布不足:模拟环境和规则任务很干净,但真实用户界面里有广告、弹窗、个性化布局、语言差异、版本变化和复杂工作流。
- 长尾任务缺失:研发工具、设计软件、办公套件、系统设置、浏览器插件等场景往往不在主流数据集中心。
Video2GUI 的切入点在于:教程视频天然包含了“人在真实软件里为了某个目标而操作界面”的过程。相比静态截图,视频提供了时间维度;相比单步标注,教程视频往往有清晰的任务语义;相比模拟环境,它覆盖了真实应用生态。
问题是,原始视频不能直接拿来训练 agent。它们没有结构化动作、没有坐标标签、质量参差不齐,还混有大量与 GUI 无关的内容。因此论文把任务定义为:如何从大规模未标注互联网视频中,自动抽取高质量、可 grounding、可预训练的 GUI 交互轨迹。
3. Video2GUI 的核心思路
Video2GUI 的主线可以概括为四个关键词:筛选、抽取、定位、训练。
首先,它从 500M+ YouTube 视频元数据出发,通过粗到细的过滤机制找到高质量 GUI 教程视频。然后,它把视频切成较短片段,用多模态模型抽取任务指令、动作时间戳和动作描述。接着,它对每个低层动作做空间 grounding,把“点击搜索框”“选择左侧菜单项”这类语义动作映射到屏幕区域。最后,它用得到的 WildGUI 数据集对 Qwen2.5-VL、Mimo-VL 等多模态模型做 GUI 领域的 continual pretraining,再进行后训练。
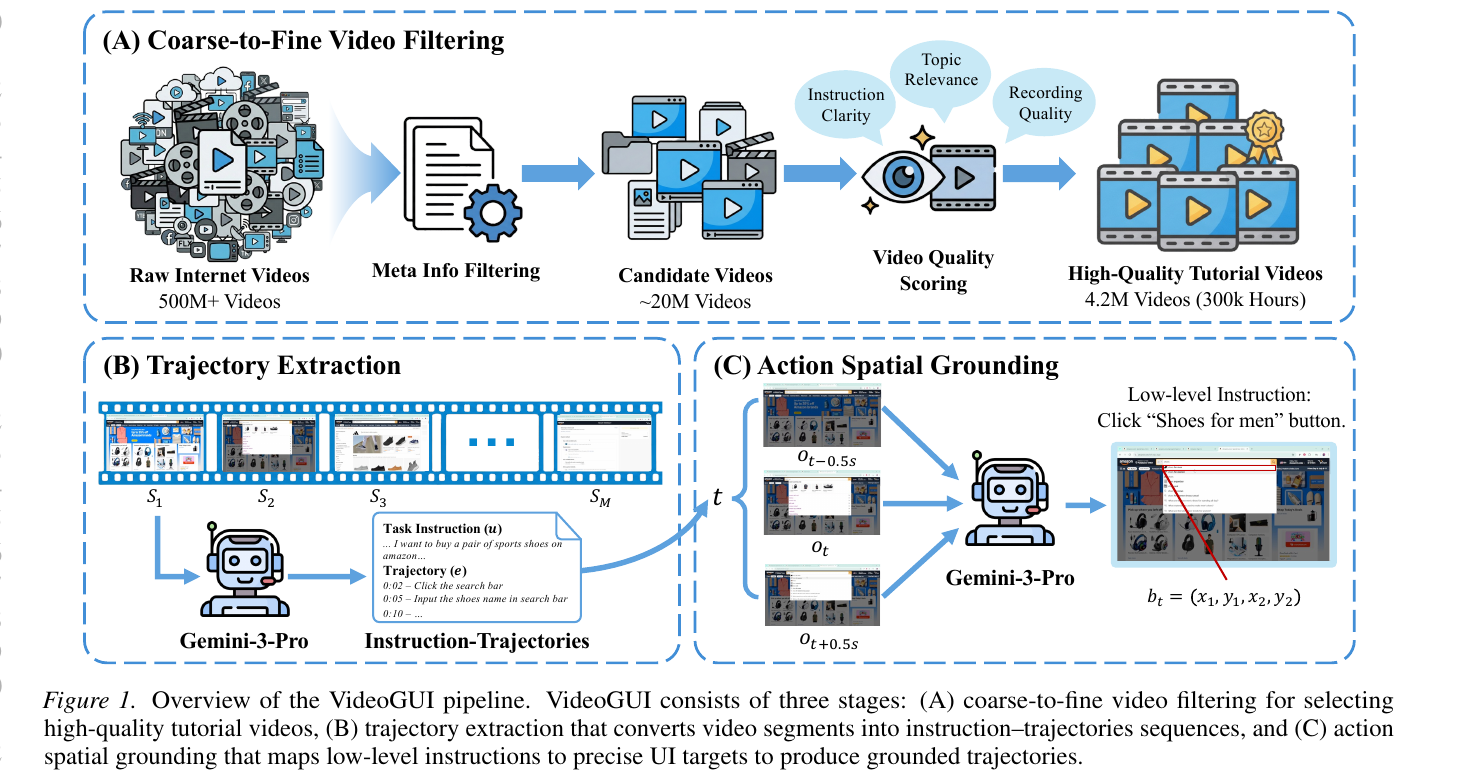
图 2:论文方法图。Video2GUI 包含粗到细视频过滤、轨迹抽取、动作空间定位三个数据构建阶段;随后用 WildGUI 做持续预训练,并在公开 GUI 数据上后训练。
这条路线与很多 GUI agent 工作的差异在于:它不是只在小规模专家轨迹上做 SFT,也不是依赖在线环境中反复试错,而是先构建一个大规模、跨平台、跨应用的“GUI 行为语料库”。如果类比大语言模型,WildGUI 更像是 GUI agent 领域的预训练语料,而不是某个单一任务的微调集。
4. 方法设计拆解:从视频到可训练轨迹
4.1 粗到细视频过滤:先找到“值得看”的教程视频
第一步是从海量视频里找出 GUI 教程内容。论文使用两阶段筛选。
第一阶段是元数据过滤。 系统收集视频标题、频道、上传时间、关键词、描述、字幕等信息。作者先用 DeepSeek-V3 标注约 10K 条元数据样本是否与 GUI 教程相关,再用这些样本微调一个带分类头的 Qwen2.5-7B。这个分类器被应用到 500M+ 视频元数据上,将候选规模缩小到约 20M。
这个设计很工程化:如果直接用强多模态模型处理所有视频,成本不可接受;先用文本元数据做廉价粗筛,可以把算力留给更可能有价值的视频。
第二阶段是内容质量评分。 元数据相关不代表视频真的可用:有些视频可能只是软件宣传片,有些录屏模糊,有些没有明确操作步骤。Video2GUI 进一步用内容评分器评估三个维度:主题相关性、指令清晰度、屏幕录制质量。经过这一层筛选,得到约 4.2M 个高质量教程视频,总时长约 300K 小时。
对 GUI agent 来说,这一步非常关键。数据规模固然重要,但如果训练语料里混入大量无关视频、模糊界面或无法对应动作的片段,模型学到的可能是噪声而不是操作常识。
4.2 轨迹抽取:把被动视频变成 instruction–trajectory pair
找到视频之后,下一步是把视频转成 agent 可学习的轨迹。
论文将每个视频切分成不超过 4 分钟的片段,并使用 Gemini-3-Pro 在滑动窗口和历史上下文下进行分析。输出不是简单字幕摘要,而是结构化的 instruction–trajectory pair:
(u, e) = (任务指令, 动作序列与观察序列)其中包含:
- 高层任务目标,例如“在设置中开启某个选项”;
- 动作时间戳,说明操作发生在视频的哪个时刻;
- 动作细节,例如点击、输入、滚动、选择;
- 视觉 grounding 所需的低层指令,例如“点击右上角的保存按钮”。
这里的难点在于,教程视频通常不是严格的演示轨迹:讲解者会停顿、移动鼠标、放大画面、切换窗口,甚至穿插讲解幻灯片。Video2GUI 需要从这些非结构化视频中恢复“对 agent 有学习价值的动作链”。这也是为什么论文强调历史上下文和滑动窗口:单独看某一帧很难判断动作意图,必须结合前后步骤和视频语义。
4.3 动作空间 grounding:从“点击按钮”到屏幕坐标区域
轨迹抽取只能得到语义动作,还不足以训练 GUI agent。真正执行时,模型必须知道目标在哪里。因此 Video2GUI 的第三阶段是 action spatial grounding。
对每个交互时间点 t,系统输入三张高分辨率截图:
{o_{t-0.5s}, o_t, o_{t+0.5s}}再结合低层动作指令,让模型预测目标区域:
b_t = (x1, y1, x2, y2)使用三帧而不是单帧很有意义。GUI 操作的效果往往体现在前后变化中:按钮被按下、菜单展开、输入框聚焦、列表滚动。如果只看动作发生时刻的一张图,模型可能分不清鼠标悬停、点击前状态和点击后状态。前后帧提供了动作效果线索,能帮助定位真正的交互对象。
论文项目页提到,作者对 200 个采样动作做人工验证,超过 95% 的动作参数化是正确的。这个数字不代表所有自动标注都完美,但说明这种视频到 grounding 的路径至少具备可用的数据质量基础。
5. WildGUI 数据集与训练方案
最终构建出的 WildGUI 是这篇论文最重要的资产之一。项目页和论文摘要给出的规模包括:
- 12.7M 条交互轨迹;
- 124.5M 张截图 / 图像;
- 覆盖 1,500+ 应用和网站;
- 横跨 Web、移动端、桌面端;
- 包含高层任务指令和低层 grounded actions。

图 3:WildGUI 与已有 GUI 数据集的对比。它的核心优势不是某一个平台上的精标样本,而是跨平台、跨应用、互联网规模的真实教程轨迹。
训练上,论文采用两阶段策略。
第一阶段是 continual pretraining:把 WildGUI 当作 GUI 领域语料,对 Qwen2.5-VL、Mimo-VL 等基础多模态模型继续预训练,让模型吸收大规模界面操作模式、控件语义、任务流程和视觉定位规律。
第二阶段是 post-training:在更干净、更面向任务的公开 GUI 数据集上进行后训练,使模型适配具体 benchmark 的输出格式和任务要求。
这个设计有一个很清晰的逻辑:WildGUI 提供广度,后训练提供格式和精度。前者解决“见过足够多真实界面吗”,后者解决“能不能按评测规范稳定输出动作”。
6. 实验结果与结论
Video2GUI 的实验覆盖 GUI grounding、离线 GUI agent 评测和在线 GUI agent 评测。论文报告,在 WildGUI 上预训练 Qwen2.5-VL 和 Mimo-VL,可以在多个基准上带来 5%–20% 的稳定提升,并达到或超过当时的开源 SOTA。
项目页和论文摘要中特别强调了几个结果:
- WildGUI 预训练在 ScreenSpot-Pro、OSWorld-G 等 GUI grounding benchmark 上显著提升定位能力;
- 在 AndroidControl、CAGUI、OSWorld、AndroidWorld 等动作与任务执行评测中也能带来收益;
- 社区摘要中提到 ScreenSpot-Pro accuracy 从 41.2 提升到 56.9,相当于约 38% 的相对提升;
- 随着 WildGUI 预训练数据规模增加,性能呈现平滑提升趋势。
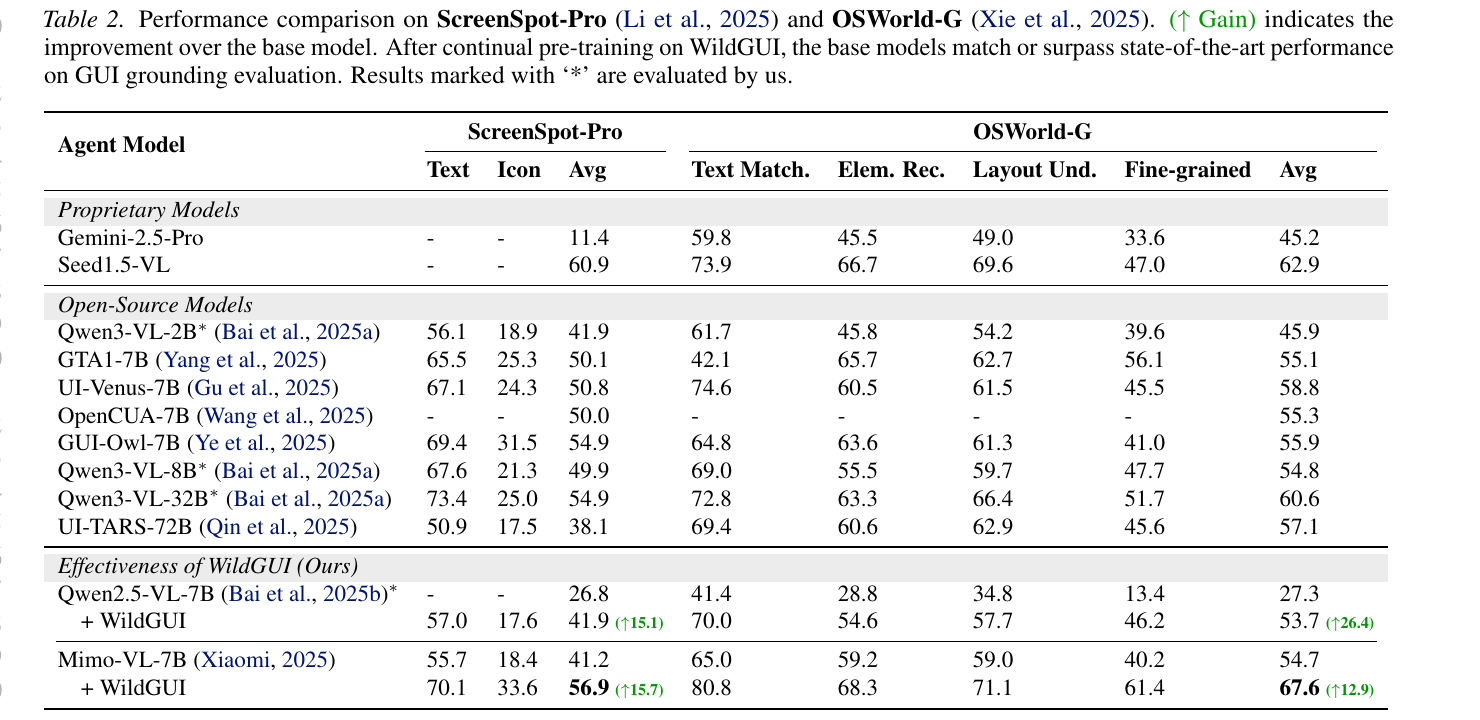
图 4:Video2GUI 的主要实验结果之一。大规模视频轨迹预训练提升了模型在 GUI grounding 和 GUI agent 相关 benchmark 上的表现。
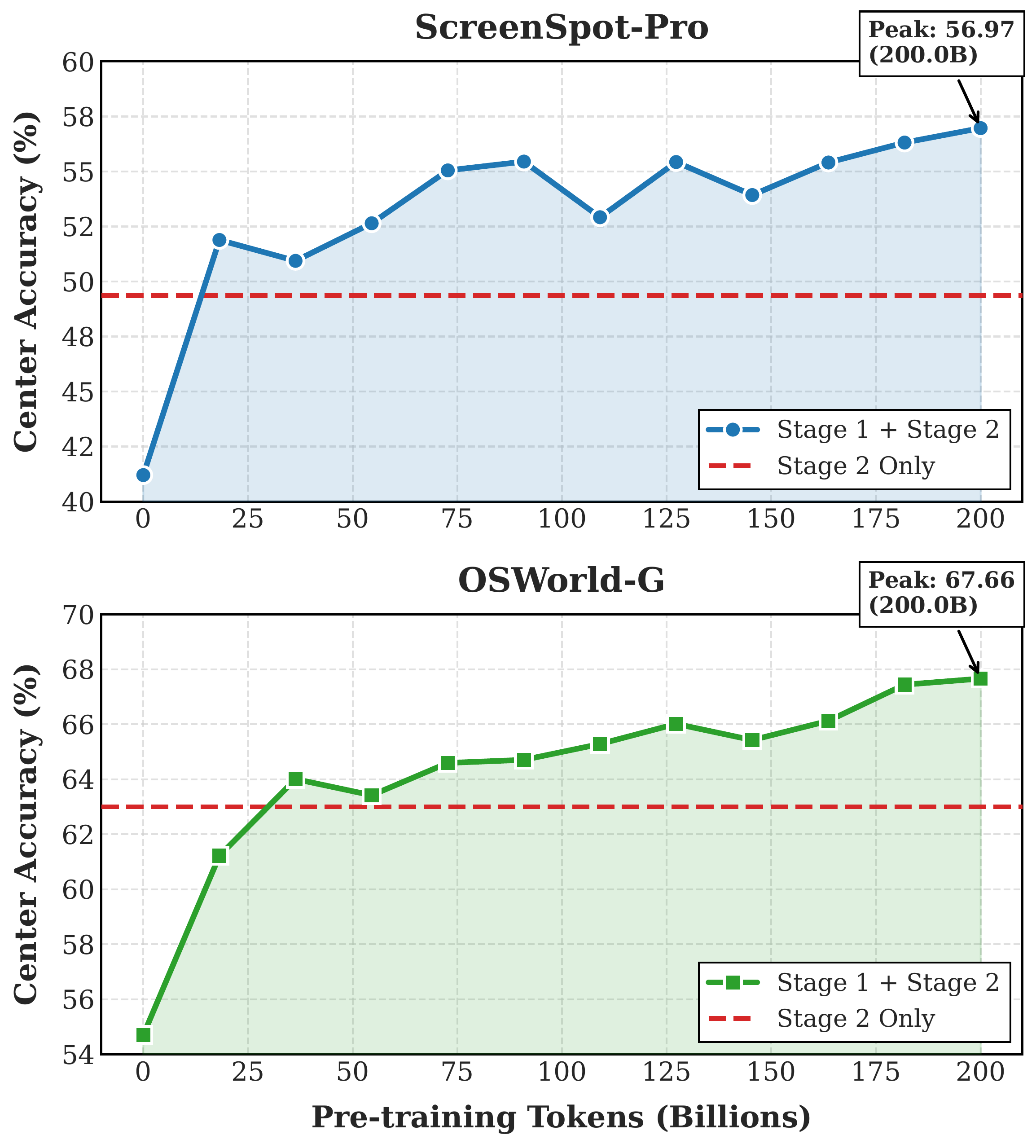
图 5:数据规模实验。论文强调性能会随着 WildGUI 预训练数据量增加而持续改善,这支持了“GUI agent 需要大规模真实交互语料”的核心判断。
这些结果的意义不只是“又提高了几个点”。更重要的是,它验证了一个方向:GUI agent 的泛化能力可以通过互联网规模的真实界面轨迹预训练来提升。 换句话说,GUI agent 不一定只能依赖昂贵的人工录制,也不一定只能在少量沙盒环境里学习。只要数据管线足够稳,视频世界本身就是一个巨大的 GUI 行为库。
7. 对 macOS 研发效率工具和 GUI 自动化的启发
从工程落地角度看,Video2GUI 对 macOS 研发效率工具、桌面自动化和 computer-use agent 有几个直接启发。
第一,真实操作视频是被低估的数据源。 很多团队在做内部工具、IDE 插件、设计软件自动化、CI 可视化面板或数据平台时,都会积累录屏、教程、客服排障视频、产品 demo。这些材料过去主要用于人类培训,但 Video2GUI 说明它们可以被转化为 agent 训练数据。对企业内部 macOS 工具链而言,录屏和操作日志结合,可能比从零人工标注更经济。
第二,GUI agent 的训练数据应该覆盖“跨应用工作流”。 研发效率场景常常不是单一 App:开发者可能在浏览器查文档,在 VS Code / Cursor 修改代码,在终端运行命令,在 Finder 管理文件,在 Slack 或飞书同步信息。WildGUI 的跨 Web、桌面、移动端思路提醒我们,真正有用的 computer-use agent 不能只会某个 App 的固定流程,而要学会跨应用迁移控件语义和任务结构。
第三,视频到轨迹的自动化管线可以成为产品能力。 一个 macOS agent 如果能够观察用户授权的操作录屏,自动抽取“任务—步骤—界面状态—动作目标”,就可以生成可复用 workflow、自动化脚本或测试用例。这对研发工具尤其有价值:把一次人工排障、发布检查、回归验证流程沉淀为可审计的自动化模板。
第四,grounding 质量需要和可验证执行闭环结合。 Video2GUI 用前后帧帮助动作定位,但真实桌面环境还会遇到窗口遮挡、多显示器、Retina 缩放、输入法状态、权限弹窗等问题。因此落地到 macOS 时,最好把视觉 grounding 与 Accessibility tree、窗口元数据、执行后状态验证结合,而不是只依赖截图坐标。
第五,数据治理和权限边界要前置设计。 如果未来从内部教程视频或用户操作数据中学习,必须处理隐私、脱敏、授权、最小化采集和可删除机制。GUI agent 数据往往包含文件名、账户信息、业务页面、代码片段,比普通网页文本更敏感。Video2GUI 给出了规模化数据构建的技术路线,但工程产品必须补上治理层。
8. 局限性与我的点评
Video2GUI 很有启发性,但也有一些值得谨慎看待的地方。
首先,自动标注数据不可避免有噪声。超过 95% 的抽样动作参数化正确是一个积极信号,但抽样规模相对有限,且真实长尾场景中错误可能集中出现在复杂软件、低清录屏、快速切换、遮挡和动态布局里。对于长程 GUI agent,一个早期 grounding 错误可能会导致后续轨迹全部偏离。
其次,教程视频分布不等于真实任务分布。教程视频往往更线性、更解释性、更面向“展示功能”;真实用户任务则更碎片化、更受个人偏好和环境状态影响。例如研发人员在 IDE 中调试问题时,经常会来回尝试、撤销、查日志、搜索报错,这种探索式行为未必在教程视频中充分体现。
第三,强模型参与数据生产带来成本与依赖问题。Video2GUI 在轨迹抽取和 grounding 中使用 Gemini-3-Pro 等强模型,这提高了标注质量,但也意味着数据构建成本、复现门槛和模型版本依赖需要仔细评估。对于普通团队,可能需要用较小模型、本地 OCR、事件日志和启发式规则做更经济的替代。
第四,开源承诺与实际可用性需要持续跟踪。论文和项目页表示会释放 WildGUI 数据集和 Video2GUI pipeline,但仓库当前 README 仍较简略。对研究社区来说,真正的影响力取决于数据许可、下载方式、标注格式、过滤策略、可复现脚本和隐私处理细节。
我的整体判断是:Video2GUI 的价值不只在于 WildGUI 这个数据集本身,更在于它把 GUI agent 的数据构建范式从“小规模人工演示”推进到“互联网规模自动轨迹合成”。这可能会成为未来通用 GUI agent 的基础设施方向。
9. 总结
Video2GUI 回答了一个非常关键的问题:当 GUI agent 需要跨平台、跨应用、跨任务泛化时,训练数据从哪里来?论文给出的方案是把互联网上大量未标注教程视频转化为结构化、可 grounding、可预训练的 GUI 交互轨迹。
它的主要贡献可以概括为三点:
- 提出自动化 Video2GUI 流水线,从 500M+ 视频元数据中筛选高质量 GUI 教程,抽取动作轨迹并完成空间 grounding;
- 构建 WildGUI,大规模覆盖 Web、移动端和桌面端的真实 GUI 交互数据;
- 验证 WildGUI 预训练可以在多个 GUI grounding 和 agent benchmark 上带来 5%–20% 的提升。
对工程侧来说,这篇论文最值得带走的不是某个具体 benchmark 数字,而是一种产品和系统思路:未来的 GUI agent 需要自己的“操作经验库”,而视频、录屏、日志、状态验证和权限治理,将共同构成这个经验库的生产管线。 对 macOS 研发效率工具而言,这意味着我们可以把日常操作、排障流程、发布检查和跨应用工作流沉淀为可学习、可复用、可验证的自动化资产。