Flue:把 Claude Code 式 agent 变成可部署的 TypeScript 框架
拆解 withastro/flue:它不是一个聊天 SDK,而是围绕 harness、session、sandbox、skills、routing 和 build target 设计的 headless agent 框架。
项目:withastro/flue
分析版本:main 分支bb9245f
一句话结论:Flue 想做的是 agent 时代的应用框架,而不是又一个模型调用 SDK。
先说它是干什么的
Flue 是 Astro 团队开源的一个 TypeScript agent 框架。它的定位很明确:如果说 Claude Code、Codex、OpenCode 这类工具让开发者体验到了“agent 自己读文件、跑命令、改代码、调用工具”的工作方式,那么 Flue 要做的就是把这套 agent harness 变成可编程、可部署、无 UI 依赖的框架。
README 里有一句很关键的话:Flue 是 “The Agent Harness Framework”。翻译成人话就是:它不只帮你发一次 LLM 请求,而是把一个 autonomous agent 运行时该有的东西都包起来,包括:
- agent 和 workflow 的源码组织方式;
- session 会话、消息历史和可继续状态;
- 文件系统、shell、工具调用和 sandbox 抽象;
AGENTS.md与.agents/skills/这样的 Markdown 上下文;- HTTP、WebSocket、异步 dispatch、run logs 等入口;
- Node.js 和 Cloudflare Workers / Durable Objects 两种部署目标;
- SDK、OpenTelemetry、Sentry / Braintrust 示例和 connector 生态。
所以,Flue 最适合的场景不是“我要调一个模型做摘要”,而是“我要把一个 agent 做成服务,让它持续接收消息、保留状态、在隔离环境里执行工具,并且能部署到不同运行时”。
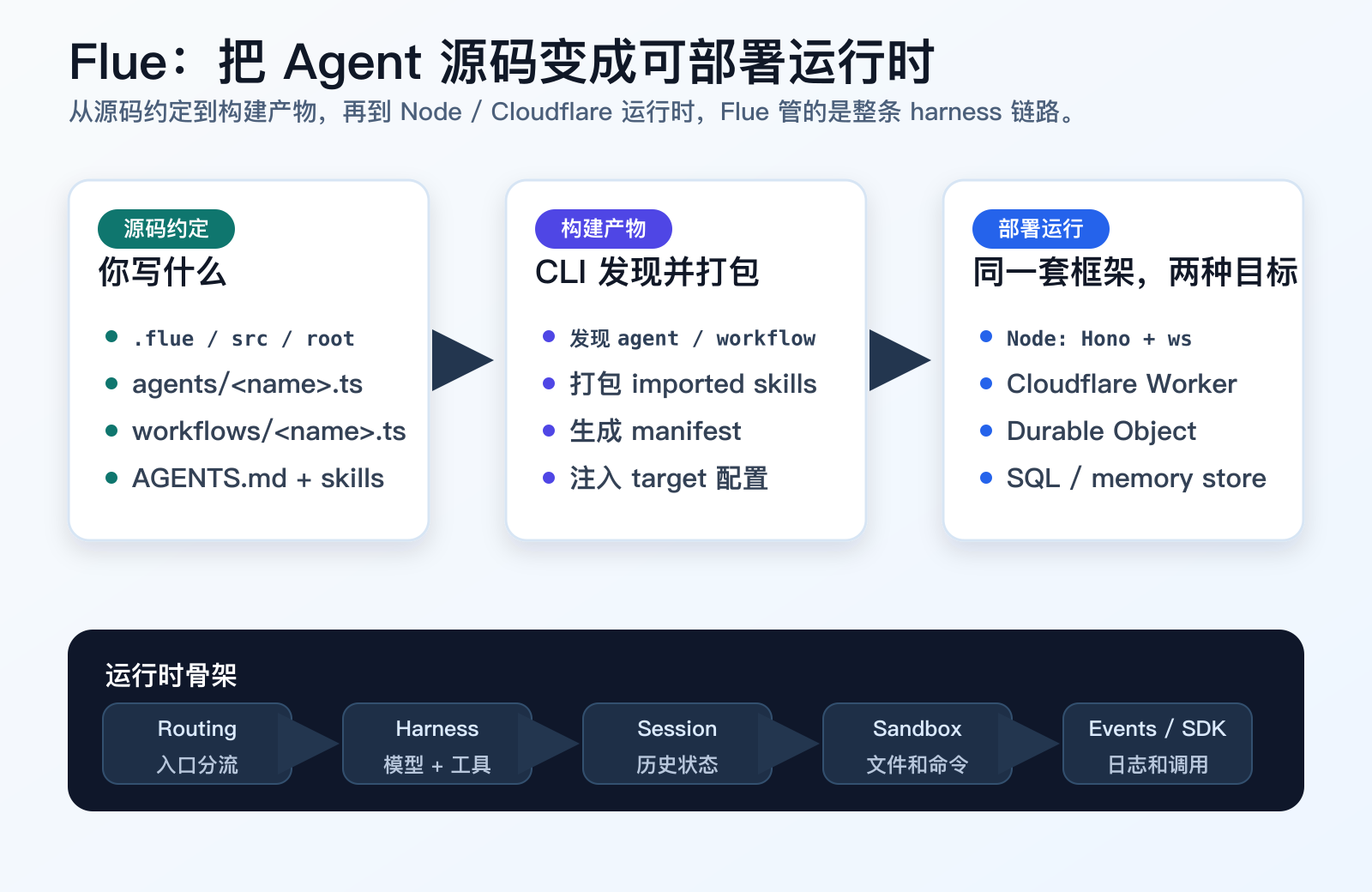
图 1:Flue 的核心链路。你写 agents/、workflows/、AGENTS.md 和 skills,CLI 负责发现和构建,运行时负责路由、session、sandbox、工具、事件和 SDK。
它为什么不是普通 AI SDK
普通 AI SDK 的抽象中心通常是一次模型调用:传入 messages、tools、schema,然后拿回 response。Flue 的抽象中心不是 response,而是 一个能持续运行的 agent 环境。
项目自己的 AGENTS.md 把层级写得非常清楚:
Agent module
└─ AgentInstance
└─ Harness
└─ Session
└─ Operation
└─ Turn这组术语非常重要。AgentInstance 来自 URL 里的 <id>,代表一个稳定运行范围;Harness 是模型、工具、沙箱和上下文的组合;Session 才是具体会话;Operation 是一次 prompt()、skill()、task() 或 shell();Turn 则是底层模型的一轮往返。
这也解释了 Flue 的设计气质:它把“会话可继续”“工具可执行”“上下文可发现”“部署目标可切换”当成框架的基本能力,而不是业务代码里的临时拼装。
入口:workflow、agent、dispatch 三条路
Flue 最容易误解的地方,是把所有调用都叫成 run。源码和文档都在强调:run 只属于 workflow,直接 agent 交互和 dispatch 不是 run。

图 2:Flue 的三类入口。workflow 会产生 runId 并进入 /runs 历史;direct agent 复用 agent instance 和 session;dispatch 是异步投递,拿到的是 dispatchId。
从运行时路由看,Flue 的公共 Hono 子应用暴露这些主要路径:
app.post('/workflows/:name', workflowRouteHandler);
app.get('/workflows/:name', workflowSocketRouteHandler);
app.post('/agents/:name/:id', agentRouteHandler);
app.get('/agents/:name/:id', agentSocketRouteHandler);
app.get('/runs/:runId', runByIdRouteHandler(action));来自 packages/runtime/src/runtime/flue-app.ts。
这里可以拆成三类工作负载。
第一类是 workflow。它更像一次性任务:POST /workflows/:name 后生成 runId,运行结果、事件流、错误都会进入 run store,后续可以通过 /runs/:runId、/runs/:runId/events、/runs/:runId/stream 查看。
第二类是 direct agent。它走 /agents/:name/:id,URL 里的 id 是 agent instance。你可以把它理解为“某个用户、某个仓库、某个客户会话、某个长期工作空间”的稳定标识。复用同一个 id,就能继续同一个 agent 实例里的 session 和 sandbox 状态。
第三类是 dispatch。它是应用侧把异步输入投递给一个持续 agent session。dispatch() 返回的是 dispatchId,不是 runId。这条路径适合 webhook、消息队列、后台事件触发。Node 默认是进程内内存队列;Cloudflare 会把 admission 交给目标 agent Durable Object。
这三个入口分清楚后,Flue 的产品形态就很清楚了:它既能做“跑一次就结束”的自动化任务,也能做“长期在线、持续接收消息”的 agent 服务。
核心运行时:createAgent 只是声明,init 才真正组装
Flue 写 agent 的入口看起来很轻:
const agent = createAgent(() => ({ model: 'anthropic/claude-sonnet-4-6' }));
export async function run({ init }: FlueContext) {
const harness = await init(agent);
const session = await harness.session();
return await session.prompt('What is 2 + 2?');
}这个例子来自 examples/hello-world/src/workflows/hello.ts 的简化版。
真正要注意的是:createAgent() 并没有立刻创建一个长期对象,它只是冻结了一个 initializer。
export function createAgent(initialize) {
return Object.freeze({ __flueCreatedAgent: true, initialize });
}来自 packages/runtime/src/agent-definition.ts。
到了请求进入 runtime 时,ctx.init(agent) 才会调用 initializer,解析 profile,选择模型,解析 sandbox,发现上下文,然后生成 Harness。
const resolvedOptions = await agent.initialize({ id: config.id, env: config.env, payload });
const localContext = await discoverSessionContext(env, definition.instructions, definition.skills);
return new Harness(config.id, name, agentConfig, env, store, eventCallback);来自 packages/runtime/src/client.ts。
这个设计带来两个结果。
第一,agent 初始化可以读取当前请求的 id、env、payload。也就是说,同一份 agent 源码可以根据不同客户、仓库、环境变量或请求参数初始化出不同运行环境。
第二,Flue 把“业务编排代码”和“agent runtime 状态”分开了。workflow 里可以初始化多个 harness,甚至用不同名字隔离不同阶段;direct agent 则由运行时按 agent module 和 URL id 自动初始化。
Session:历史、工具、结果 schema 都在这里收束
Harness 的核心职责是创建和管理 session。源码里默认 session 名是 default,storage key 会包含 instance id、harness 名和 session 名,因此同一个 agent instance 下可以有多个对话线程。
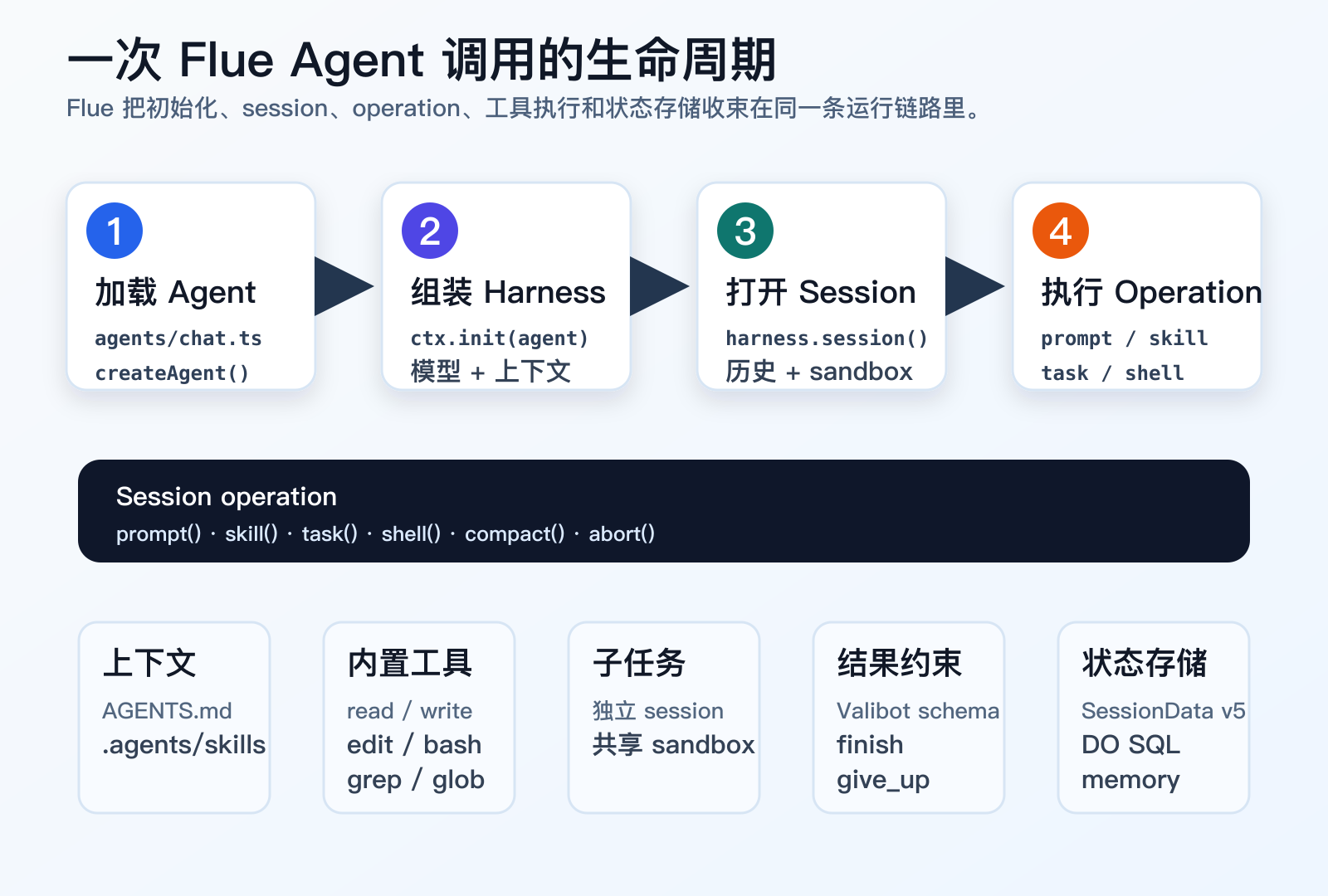
图 3:Flue 的 session 生命周期。一个 session 不只是 messages 数组,它还绑定了工具、沙箱、技能激活、结果 schema、子任务和持久化存储。
Harness 打开 session 时会先看内存里有没有已经打开的对象,没有就去 store 里加载;如果还没有,就创建新的 SessionData。
const storageKey = createSessionStorageKey(this.instanceId, this.name, sessionName);
const existingData = await this.store.load(storageKey);
const session = new Session({ name: sessionName, storageKey, config, env, store });来自 packages/runtime/src/harness.ts。
Session 内部包了一层 @earendil-works/pi-agent-core 的 Agent,并把系统提示、模型、工具、历史消息、thinking level、sessionId 塞进去。
this.harness = new Agent({
initialState: {
systemPrompt,
model: this.config.model,
tools,
messages: previousMessages,
thinkingLevel: this.config.thinkingLevel ?? 'medium',
},
toolExecution: 'parallel',
sessionId: this.affinityKey,
});来自 packages/runtime/src/session.ts。
这里很像 Claude Code / Codex 的内核:模型不是单独回答,而是带着系统上下文、文件工具、shell 工具、任务委派工具持续运行。区别是 Flue 把这套能力做成了 TypeScript API 和可部署服务。
内置工具:默认就有一个小型 agent 工作台
Flue 默认给 session 注入一组工具:
const tools = [
createReadTool(env, packagedSkills),
createWriteTool(env),
createEditTool(env),
createBashTool(env),
createGrepTool(env),
createGlobTool(env),
];来自 packages/runtime/src/agent.ts。
这组工具覆盖了 agent 最常见的工作面:读文件、写文件、精确替换、执行命令、grep 搜索和 glob 找文件。如果当前 session 支持任务委派,还会追加 task 工具;如果有 skills,则追加 activate_skill 工具。
Flue 对工具还有两层防护。
第一,自定义工具不能和内置工具重名。read、write、edit、bash、grep、glob、task、activate_skill 都是框架保留名,避免用户工具覆盖框架语义。
第二,bash 工具对超时做了专门处理。模型请求超时时,Flue 会把它变成类似 exit code 124 的可恢复结果,让模型有机会调整命令,而不是直接把整个 operation 打断。
这说明 Flue 的工具系统不是“把 function calling 暴露一下”这么简单。它更关心 agent 在真实执行里如何恢复、如何记录、如何和 sandbox 边界配合。
Sandbox:默认轻量,必要时再接真实环境
README 里说,Flue 默认使用 just-bash 驱动的 virtual sandbox。源码里的 Node 构建入口也能看到默认环境是一个 InMemoryFs 加 Bash:
async function createDefaultEnv() {
const fs = new InMemoryFs();
return bashFactoryToSessionEnv(() => new Bash({ fs }));
}来自 packages/cli/src/lib/build-plugin-node.ts 的生成模板。
这点很关键:默认 sandbox 不是你的宿主机文件系统。它是一个内存文件系统,适合高并发、低成本、无容器的 agent 服务。例如客服机器人可以把知识库写进 sandbox,再让 agent 用 grep、read 检索。
如果需要真实宿主环境,Node target 提供 local():
export function local(options = {}) {
return {
createSessionEnv: async () => createLocalSessionEnv(options),
};
}来自 packages/runtime/src/node/local.ts。
如果需要远程容器或第三方执行环境,Flue 用 SandboxApi 和 connectors 适配。仓库里有 Daytona、E2B、Modal、Vercel、Cloudflare Shell、Mirage、Boxd 等 connector markdown。它们不是普通 npm 包,而是给 coding agent 读取的安装说明:flue add daytona | claude 这种命令会把 connector 的实现指令交给另一个 agent 去落地。
这是一种很有意思的生态设计:Flue 自己定义最小沙箱接口,具体 provider 通过 connector 进入项目源码,最后仍然被 createAgent(() => ({ sandbox })) 统一接收。
Skills:Markdown 不是文档,而是运行时能力
Flue 对 AGENTS.md 和 .agents/skills/ 的处理,也很像 Codex / Claude Code 的工作方式。
运行时初始化 session context 时,会读取当前 cwd 下的 AGENTS.md 和 CLAUDE.md,再扫描 .agents/skills/<name>/SKILL.md。不过它不会一开始把所有 skill 正文都塞进 prompt,只会把 name 和 description 放进 “Available Skills”。
const agentsMd = await readAgentsMd(env, cwd);
const skills = mergeSkillCatalog(definitionSkills, await discoverLocalSkills(env, cwd));
const systemPrompt = composeSystemPrompt(agentsMd, skills, env, instructions);来自 packages/runtime/src/context.ts。
如果任务匹配某个 skill,模型会先调用 activate_skill,Flue 再把对应 SKILL.md 的完整指令注入进来。这个 lazy loading 很重要:skills 可以很多,但上下文窗口不能无限大。
Flue 还支持两类 skill。
一种是 workspace skill:运行时从 sandbox 文件系统里的 .agents/skills 发现。它适合用户项目随仓库提供规则、SOP、领域能力。
另一种是 imported skill:通过 import review from '../skills/review/SKILL.md' with { type: 'skill' } 静态导入,并由 Vite 插件打包支持文件。源码里会把这些 supporting files 暴露成 /.flue/packaged-skills/... 的只读路径,模型需要时再 read。
这里的设计很克制:Markdown 既不是纯文档,也不是魔法全局 prompt,而是可发现、可激活、可打包、可延迟加载的能力单元。
结果 schema:让 agent 用工具提交结构化答案
很多 SDK 会把结构化输出做成“模型必须返回 JSON”。Flue 的做法更像 agent runtime:当你给 session.prompt() 或 session.skill() 传入 result schema 时,它会动态注入两个工具:finish 和 give_up。
const resultBundle = args.schema ? createResultTools(args.schema) : undefined;来自 packages/runtime/src/session.ts。
createResultTools() 会把 Valibot schema 转成 JSON Schema,生成 finish 的参数定义;模型只有成功调用 finish 才算完成。如果模型没调用 finish 或 give_up,Flue 会继续发一个 follow-up prompt 要求它二选一。
return {
tools: [finishTool, giveUpTool],
getOutcome: () => outcome,
};来自 packages/runtime/src/result.ts。
这个设计的好处是:结构化结果被纳入 agent 的工具调用循环,而不是寄希望于模型“乖乖输出 JSON”。如果参数校验失败,工具会返回错误,模型还能自我修正。
Task:子 agent 不是函数调用,而是独立 session
Flue 的 session.task() 很值得单独说。它不是简单把 prompt 丢给另一个模型调用,而是创建一个 detached child session。
源码里有几个关键信号:
- 最大 task 深度是 4;
- child task 可以指定
cwd; - child task 会重新发现当前 cwd 下的
AGENTS.md和.agents/skills/; - child task 共享父 session 的 sandbox / filesystem;
- child task 有自己的消息历史,最终只把结果文本返回给父 session。
简化后流程是这样:
child = await this.createTaskSession({ parentSession: this.name, cwd: options?.cwd });
const output = await child.prompt(text, childOptions);来自 packages/runtime/src/session.ts。
这和 Claude Code / Codex 里“让一个子任务去读代码、回来汇报”的体验很像。Flue 把它做成了 runtime 原语,甚至把同一个 task 工具开放给 LLM 在 prompt() / skill() 中自行调用。
构建:Flue 像 Web 框架一样发现和生成入口
Flue 的 CLI 更像 Astro / Next.js 的 build layer,而不是一个薄命令行包装。
它会先决定 source root:项目根目录下如果有 .flue/,就用 .flue/;否则用 src/;再否则用根目录。
for (const sourceDirectory of ['.flue', 'src']) {
const candidate = path.join(root, sourceDirectory);
if (fs.statSync(candidate).isDirectory()) return candidate;
}
return root;来自 packages/cli/src/lib/source-root.ts。
随后 build 会扫描 agents/ 和 workflows/:
const agents = discoverAgents(sourceRoot);
const workflows = discoverWorkflows(sourceRoot);
const appEntry = discoverOptionalEntry(sourceRoot, 'app');来自 packages/cli/src/lib/build.ts。
如果目标是 Node,Flue 会生成一个 server.mjs,里面接入 Hono、ws、内存 session store、run store、dispatch queue,然后启动 HTTP 服务。
如果目标是 Cloudflare,Flue 会生成 Worker + Durable Object 入口:每个 agent / workflow 会对应生成 class,session store 默认落到 Durable Object 的 SQLite storage,workflow run 也有 durable run store。Cloudflare target 还会注册默认的 cloudflare provider,接入 Workers AI binding。
这就是 Flue 自称 runtime-agnostic framework 的依据:业务侧写 agent 和 workflow,框架侧用 target plugin 生成不同部署形态。
Observability:事件是框架的一等公民
Flue 的 session 在执行过程中会持续发事件:operation start/end、turn request、message delta、tool start/call、task start/end、compaction 等。createFlueContext() 里有 per-context subscriber,也会把事件分发给全局 observe()。
dispatchGlobalEvent(decorated, ctx);来自 packages/runtime/src/client.ts。
@flue/opentelemetry 包则把这些事件映射成 span:workflow、operation、task、turn、tool、compaction 都会变成可观测对象。
这对 agent 服务很重要。因为 agent 的失败经常不是“模型请求失败”这么简单,而是某个工具调用错了、某个 task 偏了、某次上下文压缩丢了关键信息。没有结构化事件,就很难在生产环境里 debug。
几个容易踩错的理解
第一,Flue 目前仍是 experimental。README 顶部明确写着 APIs may change。拿它做生产服务时,要接受 1.0 前 API 变动的成本。
第二,direct agent 交互不是 workflow run。/runs 和 flue logs 只看 workflow runs;agent session 的直接 prompt 和 dispatch input 属于持续 session,不会自动变成 run 记录。
第三,默认 sandbox 不是宿主机。想让 agent 直接操作 CI runner 或本机仓库,要显式用 local() 或接入外部 sandbox connector。
第四,Flue 不负责给你做聊天 UI。它有 SDK 和 WebSocket,但它的核心是 headless runtime。你可以把它接到自己的 Web App、Slack、GitHub Actions、Cloudflare Worker 或内部系统。
第五,MCP 支持是“远程 MCP 工具适配”。connectMcpServer() 会把远程 MCP server 的 tools 变成 Flue tool definitions,但 README 也说明它不会自动探测 transport,也不会帮你 spawn 本地 stdio MCP server。
我怎么看这个项目
Flue 最有价值的点,不在于它又封了一层模型 API,而在于它把 agent 产品里那些容易被忽略的工程问题前置了:
- agent 如何拥有稳定实例和可继续 session;
- session 历史如何持久化、压缩、删除;
- sandbox 如何既能轻量虚拟化,又能接入真实容器;
- skills 如何按需加载,而不是把所有规则塞进系统 prompt;
- workflow run 和长期 agent session 如何分清;
- 子任务如何有自己的上下文,而不是污染主会话;
- 事件、日志、OpenTelemetry 如何贯穿 agent 执行过程;
- 同一份 agent 源码如何部署到 Node 和 Cloudflare。
这也是为什么我觉得 Flue 更像 “Astro for agents” 的原因。Astro 管的是页面、路由、构建和部署目标;Flue 管的是 agent、session、sandbox、skills、events 和部署目标。
当然,它现在还处在快速变化期,仓库里也能看到很多 1.0 前的边界处理和迁移痕迹。对于想马上做一个稳定商业系统的人,它可能还需要观望;但对于想理解下一代 agent framework 该怎么组织的人,Flue 非常值得读。
源码索引
继续读这个仓库,可以从这些文件开始:
| 关注点 | 文件 |
|---|---|
| 项目术语和约定 | AGENTS.md |
| 公共 API 出口 | packages/runtime/src/index.ts |
| agent/profile 定义 | packages/runtime/src/agent-definition.ts |
ctx.init() 和 harness 初始化 | packages/runtime/src/client.ts |
| Harness 与 session 打开逻辑 | packages/runtime/src/harness.ts |
| Session、prompt、skill、task、shell | packages/runtime/src/session.ts |
| 内置工具和 task 工具 | packages/runtime/src/agent.ts |
| AGENTS.md / skills 发现 | packages/runtime/src/context.ts |
| 结构化结果工具 | packages/runtime/src/result.ts |
| Sandbox 抽象 | packages/runtime/src/sandbox.ts |
| 公共路由 | packages/runtime/src/runtime/flue-app.ts |
| CLI build 入口 | packages/cli/src/lib/build.ts |
| Node target 生成器 | packages/cli/src/lib/build-plugin-node.ts |
| Cloudflare target 生成器 | packages/cli/src/lib/build-plugin-cloudflare.ts |
| SDK client | packages/sdk/src/client.ts |
| OpenTelemetry 适配 | packages/opentelemetry/src/index.ts |
总结
Flue 做的不是“让你更方便地调用某个模型”,而是“让你把 agent 当成应用来写、构建和部署”。
它的中心词是 harness:把模型、工具、文件系统、shell、技能、上下文、session、事件和部署目标胶合在一起。你写很少的 TypeScript,剩下的行为大量来自 Markdown 上下文、skills、sandbox 和 runtime 工具。
如果未来 agent 服务会像 Web 服务一样普遍,那么 Flue 这类框架要解决的问题会越来越核心:入口如何标准化、状态如何持久化、工具如何隔离、失败如何观测、部署如何跨平台。withastro/flue 现在还年轻,但它已经把这些问题摆在了正确的位置上。