GUI-CIDER:GUI Agent 需要的不是更多轨迹,而是可内化的界面世界知识
解析 arXiv 2026 论文 GUI-CIDER:如何用因果内化与密度感知样本重选,在 mid-training 阶段把 GUI 轨迹转化为可迁移的界面世界知识。
目录
- 为什么这篇论文值得关注
- 背景与问题定义:GUI agent 缺的到底是什么
- GUI-CIDER 的核心思路
- 方法设计拆解:从轨迹到知识,再从知识到参数
- 实验结果与结论
- 对 macOS 研发效率工具和 GUI 自动化的启发
- 局限性与我的点评
- 总结
- 参考链接
1. 为什么这篇论文值得关注
今天选的论文是 GUI-CIDER: Mid-training GUI Agents via Causal Internalization and Density-aware Exemplar Reselection。
- 论文地址:https://arxiv.org/abs/2605.28534
- HTML 版本:https://arxiv.org/html/2605.28534v1
- 代码地址:https://github.com/Wuzheng02/GUI-CIDER
- 作者:Zheng Wu、Chengcheng Han、Zhengxi Lu、Tianjie Ju、Yanyu Chen、Qi Gu、Xunliang Cai、Zhuosheng Zhang
- 机构:上海交通大学、美团、浙江大学、香港中文大学
- arXiv:2605.28534v1,2026 年 5 月提交
这篇论文的切入点很有意思:它没有继续单纯堆 SFT 轨迹、RL 奖励或更大的多模态模型,而是提出一个更基础的问题:GUI agent 到底是在“记住操作轨迹”,还是在真正理解图形界面的世界知识?
所谓 GUI 世界知识,指的是 agent 对界面元素、操作效果、状态转移、任务流程的常识性理解。例如:“加号”在待办应用里通常意味着新建任务;点击筛选按钮后,列表内容会按条件变化;输入框聚焦失败时,键盘输入不会改变页面状态。这些知识并不等价于坐标标注,也不是奖励信号能稳定传达的。
论文提出的 GUI-CIDER 把 GUI 轨迹先转写成带有规划和因果解释的文本知识,再通过“密度感知样本重选”过滤冗余样本,最后在 mid-training 阶段让模型把这些知识内化到参数中。它的核心主张可以概括为一句话:GUI agent 的下一阶段瓶颈,可能不是参数规模扩张,而是知识规模与知识质量。
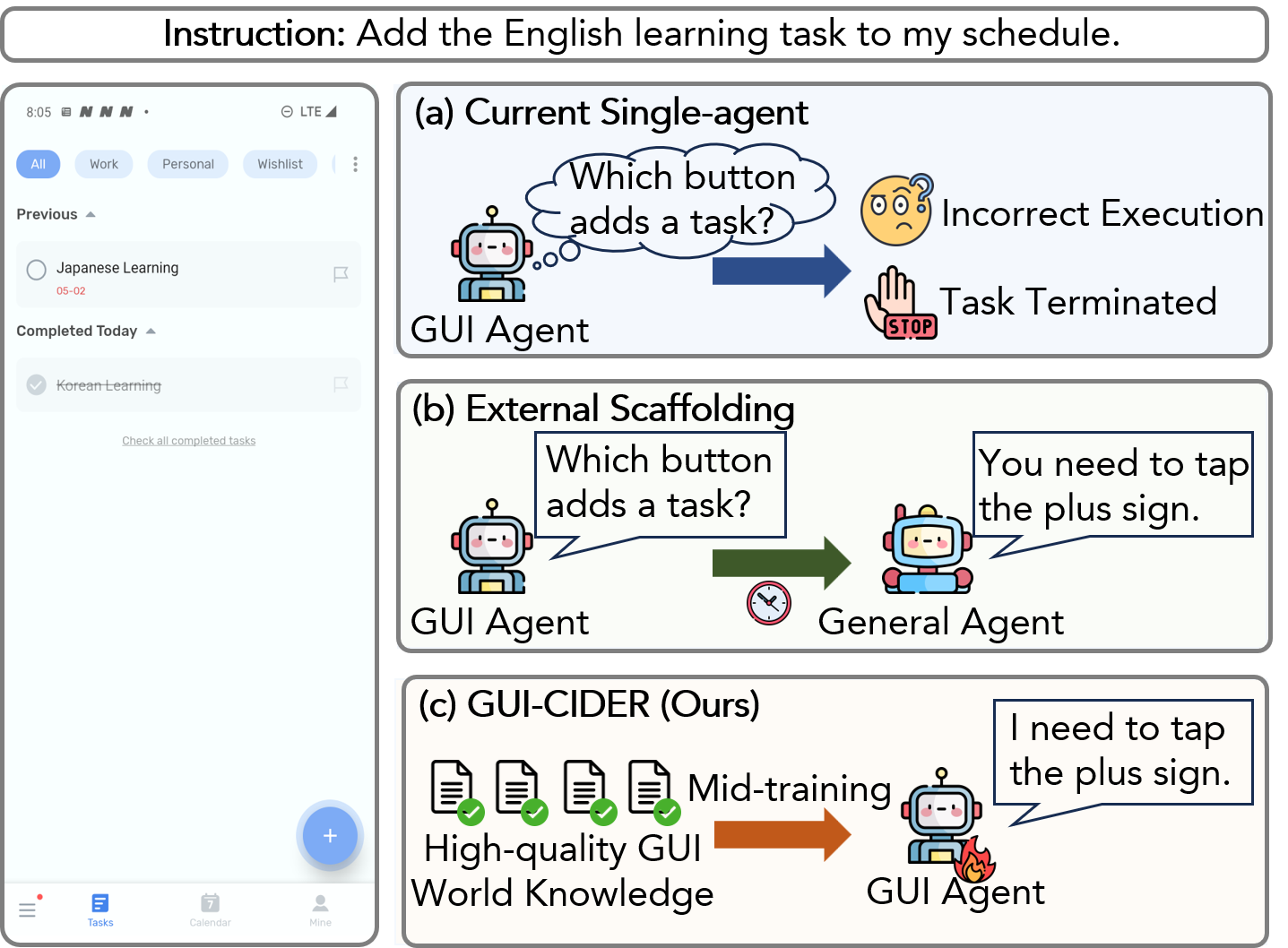
图 1:论文用一个待办应用例子说明:普通单 agent 可能不理解“+”代表添加任务;外部 scaffolding 可以靠通用模型补充低层指令,但代价较高;GUI-CIDER 希望通过 mid-training 让单个模型直接内化这类 GUI 世界知识。
2. 背景与问题定义:GUI agent 缺的到底是什么
过去两年,图形界面智能体的主流路线大致可以分成几类。
第一类是 感知与定位能力:让模型看懂截图,找到按钮、输入框、菜单项,输出点击坐标或元素 ID。ScreenSpot、GUI grounding、UI element detection 等方向主要解决这个问题。
第二类是 动作生成与任务执行能力:给定用户指令和当前界面,模型预测下一步 click、type、scroll、press 等动作。AndroidControl、AITZ、GUI-Odyssey、OSWorld 等基准推动了这一类研究。
第三类是 系统级 agent scaffolding:让一个强通用模型承担 planner、critic、memory、reflection 等角色,或把 GUI 操作与代码执行、浏览器控制、文件系统工具组合起来,提高长程任务成功率。
GUI-CIDER 指出的关键问题是:这些方法很多时候仍然把知识学习留给了后训练阶段。SFT 让模型模仿成功轨迹,RL 让模型围绕奖励优化动作,但它们往往只在标签或奖励中隐式传递知识。模型可能学到了“某个截图下点某个位置”,却未必理解“为什么这个动作会导致下一个界面状态”。
这会导致三个典型问题:
- 轨迹记忆而非机制理解:换一个 App、换一种布局、换一种语言,模型泛化就明显下降。
- 长程规划脆弱:模型知道下一步点哪里,却不清楚任务中间状态和最终目标之间的因果链。
- scaffolding 依赖过重:需要外部 planner、critic、reflection 不断补救,推理成本和系统复杂度随之上升。
论文因此把问题重新定义为:能否把 GUI 轨迹中隐含的界面世界知识显式抽取出来,在 mid-training 阶段注入模型,使其在进入 SFT/RL 之前就具备更好的 GUI 操作常识?
3. GUI-CIDER 的核心思路
GUI-CIDER 的全称是 Causal Internalization and Density-aware Exemplar Reselection。名字看起来复杂,但方法主线很清楚:
- 从原始 GUI 轨迹中合成文本化知识;
- 用因果信息和语义密度筛选高价值样本;
- 用筛选后的语料做 mid-training,让模型通过 next-token prediction 吸收 GUI 世界知识。
这里最重要的是“训练位置”的变化。
传统 GUI agent 训练常见流程是:
通用多模态模型 -> GUI 轨迹 SFT / RL -> GUI agentGUI-CIDER 更像是插入一个知识预热阶段:
通用多模态模型 -> GUI 世界知识 mid-training -> GUI 轨迹 SFT / RL -> GUI agent这和很多领域模型的经验类似:如果你希望模型在某个领域表现稳定,最好先让它读懂这个领域的语言、结构、常识和因果关系,再让它学习具体任务格式。对于 GUI agent 来说,这个“领域语言”就是控件语义、界面状态、动作效果和工作流。
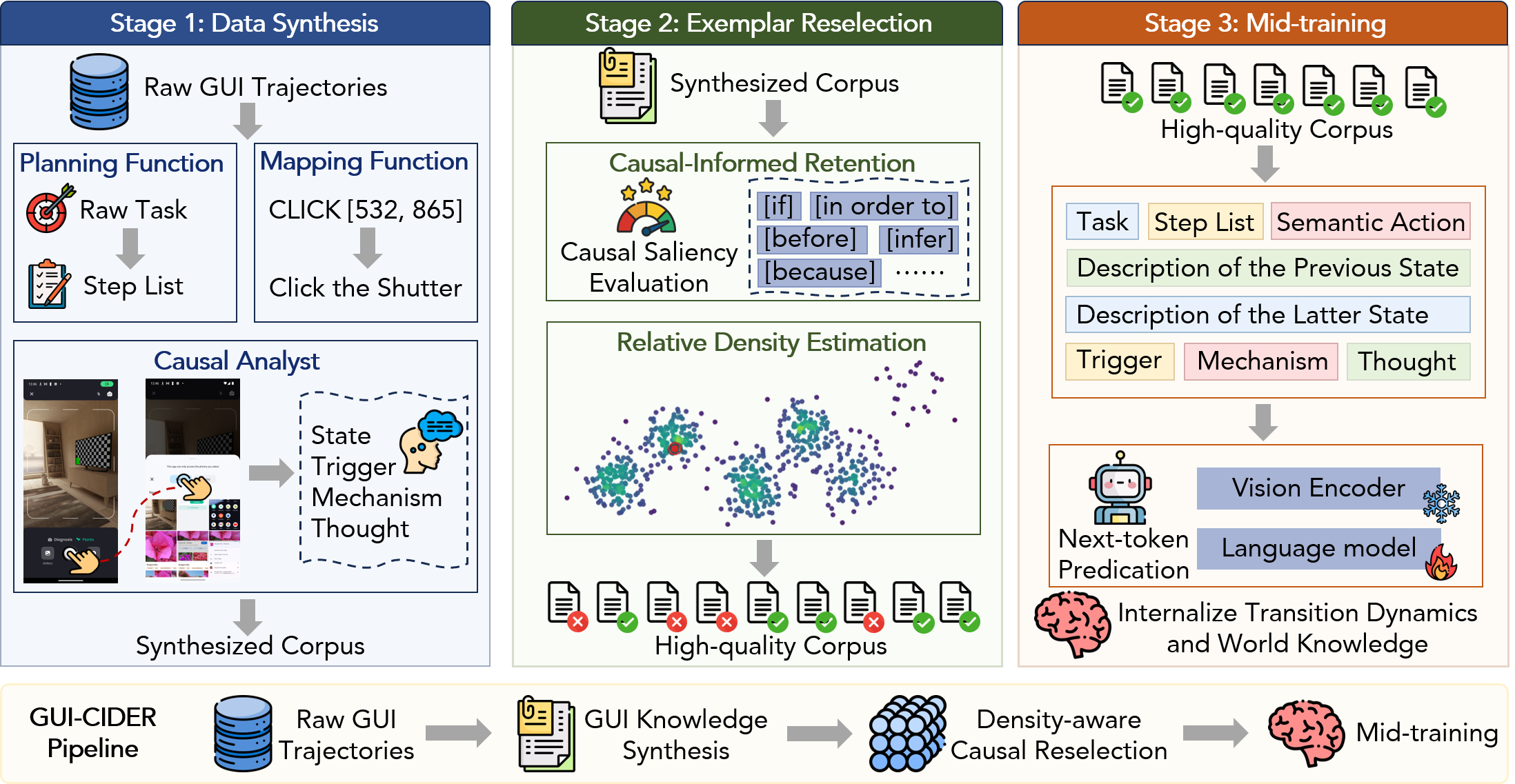
图 2:GUI-CIDER 的三阶段流程。第一阶段把 GUI 轨迹合成为静态规划知识和动态因果知识;第二阶段从合成语料中选择因果结构强、语义冗余低的样本;第三阶段用这些文本知识进行 mid-training。
4. 方法设计拆解:从轨迹到知识,再从知识到参数
4.1 数据合成:把 GUI 轨迹翻译成可学习的知识
GUI-CIDER 从 GUI 轨迹数据出发。每条轨迹包含用户任务 T,以及一串截图和动作:
{(s_i, a_i)}_{i=1}^L它不是直接拿这些截图和动作做行为克隆,而是先合成一个纯文本的知识样本。论文把知识分成两类。
第一类是 静态规划知识。高能力专家模型会把用户任务拆成若干高层子目标:
S = P(T; M_exp) = {g1, g2, ..., gn}这一步解决的是“任务应该怎样被组织”的问题。比如“在购物 App 中找到某商品并加入购物车”不是一个单步动作,而是搜索、筛选、打开详情、检查信息、加入购物车等子目标组成的流程。
第二类是 动态因果知识。它进一步回答:“某个动作为什么会改变界面?改变前后是什么状态?”论文里包括两个环节。
首先是语义行为 grounding:把低层动作和 UI 元数据转成自然语言动作描述:
B(a_t, v_t) -> a_t^nl例如把“click at coordinate (x, y)”转成“点击右上角的添加按钮”。这比坐标更接近人类可理解的操作意图。
接着是状态抽象与因果逻辑归纳:根据动作前后的界面描述、任务目标和自然语言动作,生成触发条件、界面机制和推理说明:
R_t = C(T, d_{t-1}, a_t^nl, d_t | M_exp)
= {d_{t-1}, d_t, Trig_t, Mech_t, CoT_t}也就是说,样本不只是“当前屏幕 + 下一步动作”,而是包含:
- 动作前界面是什么;
- 动作后界面发生了什么变化;
- 为什么要执行这个动作;
- 这个控件或页面机制是什么;
- 这一步如何服务于整体任务。
最终每个合成样本可写成:
x = ⟨T, S, a_t^nl, R_t⟩论文附录还给出实现细节:规划函数使用 deepseek-v4-flash,语义映射和因果分析使用 Qwen3-VL-32B-Instruct。这说明 GUI-CIDER 本质上是一种“用强模型把轨迹蒸馏为领域知识,再训练较小 agent 内化知识”的路线。
4.2 样本重选:不是所有合成知识都值得训练
大规模合成数据的常见问题是:多,但不一定好。GUI 轨迹尤其容易产生大量重复样本:打开页面、点击返回、输入文本、确认提交等模式会高度相似。如果不筛选,模型可能被低质量、低信息密度或高度冗余的样本淹没。
GUI-CIDER 的第二阶段是 Density-aware Exemplar Reselection,目标是保留两类样本:
- 因果结构更强,包含更多“为什么”和“如何变化”的样本;
- 语义冗余更低,能覆盖更多界面机制的样本。
论文设计了一个 retention function g(x)。它背后的直觉非常工程化:
- 样本的因果显著性越高,越应该保留;
- 样本所在语义区域越拥挤,越要惩罚冗余;
- 但过滤不能完全破坏原始数据的语义分布;
- 在特别拥挤的区域,因果质量更高的样本应该获得更大的边际优势。
这比简单按长度、困惑度或关键词过滤更适合 GUI 数据。因为 GUI agent 需要的不是“看起来更长的解释”,而是能够连接任务目标、界面元素、动作效果和状态转移的样本。
论文的消融结果也支持这一点:在 GUI-Odyssey 上,去掉 Stage 2 后,Qwen3-VL-4B-Instruct 的 SR 从 43.45 降到 41.06,Qwen3-VL-8B-Instruct 的 SR 从 48.55 降到 42.34。尤其 8B 模型下降更明显,说明更大模型也会被冗余和低质知识干扰。
4.3 Mid-training:把 GUI 世界知识写进模型参数
第三阶段就是用筛选后的文本语料进行标准 next-token prediction。论文强调最终训练样本是文本化的,不需要把原始截图放进最终样本中。这一点很值得注意。
一方面,它降低了数据训练的复杂度:GUI 世界知识可以以文本形式大规模注入模型。另一方面,它也体现了论文的核心假设:很多 GUI 能力缺口不是视觉分辨率不够,而是模型缺少对“界面作为可操作系统”的语言化、因果化理解。
当然,GUI-CIDER 并不是说视觉不重要。相反,它把视觉轨迹中的状态变化提炼为可读知识,再让模型在语言空间里学习这些机制。这样训练出来的 agent 后续仍然可以接收多模态输入,但它对控件、状态和流程的理解会更扎实。
5. 实验结果与结论
论文在两类任务上评估 GUI-CIDER:
- GUI agent 知识评测:MMBench-GUI L1、GUI Knowledge Bench;
- GUI agent 任务完成评测:AITZ、AndroidControl、GUI-Odyssey。
5.1 任务完成:mid-training 可以叠加到 post-training 之前
在 AITZ、AndroidControl、GUI-Odyssey 上,论文报告 action type accuracy、step-wise success rate(SR)和 task success rate(TSR)。结果显示,无论与 zero-shot 还是 post-training 方法相比,加入 GUI-CIDER 的 mid-training 通常都能带来提升。
以 Qwen3-VL-8B-Instruct 为例:
- AITZ:zero-shot SR 为 40.82,GUI-CIDER 后为 42.07;post-training 为 58.16,GUI-CIDER + post-training 为 60.33。
- AndroidControl:zero-shot SR 为 52.49,GUI-CIDER 后为 54.09;post-training 为 65.34,GUI-CIDER + post-training 为 66.82。
- GUI-Odyssey:zero-shot SR 为 44.16,GUI-CIDER 后为 48.55;post-training 为 71.74,GUI-CIDER + post-training 为 73.36。
论文总结称,相比 post-training baseline,GUI-CIDER 在任务成功率上取得了 9.70% 的平均相对提升。这说明 GUI-CIDER 不是替代 SFT/RL,而是更像一个前置知识注入层,可以和后训练组合。
5.2 GUI 知识:8B 模型接近 Claude-Sonnet-4.5
在 GUI Knowledge Bench 上,GUI-CIDER-8B 的 overall 为 66.51,接近 Claude-Sonnet-4.5 的 66.53。这个结果很有冲击力:不是因为 8B 小模型全面超过了最强闭源模型,而是说明在特定 GUI 世界知识维度上,领域化 mid-training 可以显著缩小模型规模差距。
论文还指出,GUI-CIDER-8B 在 objective 子集上超过了若干更大模型。objective 子集关注“任务是否真的完成”这一类判断,这对 GUI agent 很关键,因为真实自动化不是输出看似合理的动作,而是最终状态要满足用户目标。
5.3 知识扩展顺序:先 mid-training,再 post-training
论文的一个重要分析来自 Figure 3:当使用通用模型 Qwen3-VL-8B-Instruct 作为底座时,随着 GUI-CIDER 合成数据增多,SR 持续提升;但当使用已经经过大量 GUI 领域 post-training 的 OS-Atlas-pro-7B 作为底座时,继续做 GUI-CIDER mid-training 反而性能下降。
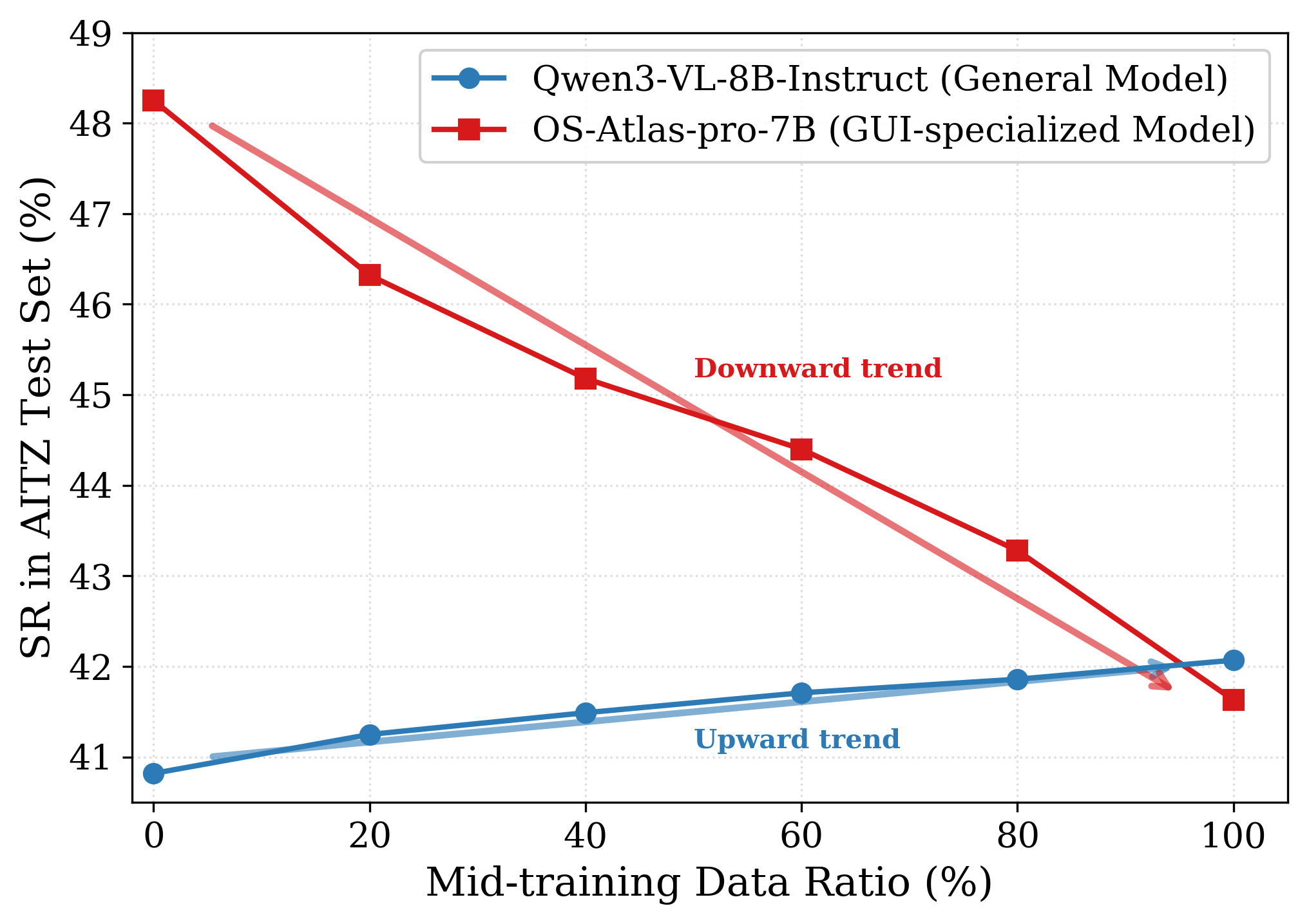
图 3:论文比较了通用模型和已经 GUI 后训练过的模型作为 GUI-CIDER 底座的表现。结论是:mid-training 更适合作为 post-training 之前的知识内化阶段,而不是对已经高度专用化的模型再补课。
这对工程实践很重要。它提醒我们:训练顺序不是随便排列的。如果模型已经被强行为克隆推向某个动作分布,它的语言表示和泛化空间可能被压缩,再去学习世界知识就更困难。更合理的流程是:
通用能力 -> 领域世界知识 -> 任务格式与动作策略 -> 在线反馈与修正6. 对 macOS 研发效率工具和 GUI 自动化的启发
这篇论文对 macOS 研发效率工具很有参考价值。很多桌面 agent 项目一开始会关注“能不能点到按钮”“能不能调用 Accessibility API”“能不能用 AppleScript 或快捷键完成操作”。这些当然重要,但 GUI-CIDER 提醒我们:产品级 computer-use agent 的护城河,很可能来自可积累、可筛选、可内化的操作知识库。
6.1 把自动化轨迹变成知识资产
如果我们在 macOS 上做研发效率 agent,例如自动配置 Xcode、整理日志、跑测试、分析 Crash、操作浏览器后台、管理 Git 客户端,系统每天都会产生大量操作轨迹。直接把这些轨迹存成 replay 脚本价值有限,因为 UI 会变、路径会变、项目结构会变。
更好的做法是把轨迹转成类似 GUI-CIDER 的知识单元:
- 当前任务目标是什么;
- 当前 App 和窗口状态是什么;
- 为什么选择这个菜单、按钮或快捷键;
- 操作后状态应该怎样变化;
- 如果状态没有变化,可能原因是什么;
- 这一步在整体研发流程中对应哪个子目标。
这样,自动化系统积累的不是脆弱脚本,而是可迁移的“研发工作流世界知识”。
6.2 让 agent 学会界面机制,而不是背坐标
macOS 上很多 GUI 自动化失败不是因为模型看不见,而是因为它不理解系统机制。例如:
- 权限弹窗需要切换到 System Settings 才能授权;
- Finder 中拖拽、复制路径、Reveal in Finder 是不同意图;
- Xcode 的 build、test、archive 对应不同状态机;
- 浏览器下载、钥匙串弹窗、系统通知会打断主流程;
- 菜单栏、Dock、Spotlight、快捷键、右键菜单是多种等价入口。
这些都属于 GUI 世界知识。GUI-CIDER 的思路可以转化成产品设计原则:不要只记录“用户点了哪里”,而要记录“为什么这个入口能完成这个子目标”。
6.3 数据筛选比数据堆叠更重要
桌面自动化日志很容易爆炸式增长。如果所有轨迹都进入训练或检索系统,agent 会被大量重复操作污染。GUI-CIDER 的密度感知重选提供了一个很好的方向:
- 对高频、低变化操作降低权重;
- 对包含异常恢复、跨 App 状态变化、权限处理、长程任务分解的样本提高权重;
- 对相似任务保留最有因果解释的一条,而不是全部保留;
- 对失败轨迹保留“失败原因—恢复策略”而不是保留无效重复动作。
这对构建 macOS agent memory 或企业内部自动化知识库非常关键。
6.4 训练顺序也能指导系统迭代
即使不训练模型,GUI-CIDER 的“先世界知识、后任务策略”也可以指导 agent 系统迭代:
- 先建立 App、控件、状态、动作效果的知识层;
- 再建立可复用的 workflow 模板;
- 最后针对具体任务做策略优化和个性化偏好学习。
如果一开始就让 agent 模仿大量具体操作,它可能很快在 demo 中表现不错,但遇到版本变化、语言变化、权限变化时会崩。先构建知识层,系统才更容易解释、调试和迁移。
7. 局限性与我的点评
GUI-CIDER 的方向很有价值,但也有几个需要谨慎看待的地方。
第一,合成知识的质量依赖专家模型。论文使用强模型生成规划、语义映射和因果解释。这会带来成本,也会带来幻觉风险。如果专家模型误解了界面机制,错误知识可能被写进学生模型。实际落地时需要配合可验证信号,比如 DOM/Accessibility Tree、操作前后截图差异、系统事件日志等。
第二,文本化知识不等于完整 GUI 状态。GUI 交互有很多视觉细节,例如布局距离、遮挡、动效、焦点状态、颜色提示。把它们压缩成文本有利于知识学习,但也可能损失细粒度感知信息。因此 GUI-CIDER 更适合作为世界知识注入,而不是替代多模态 grounding。
第三,benchmark 提升不能直接等同真实桌面成功率。AITZ、AndroidControl、GUI-Odyssey 等基准有助于评估动作预测和任务完成,但真实 macOS 任务涉及更多系统权限、后台进程、文件状态、网络状态和用户偏好。产品落地还需要在线验证、沙箱、安全边界和可回滚机制。
第四,mid-training 的工程门槛不低。对大多数团队来说,构建 100M token 级别 GUI 知识语料并训练多模态底座并不轻量。短期内更可行的路线,可能是把 GUI-CIDER 的知识合成和样本筛选思想用于 RAG、memory、workflow library 或 evaluator,而不是立即训练底座模型。
我的总体判断是:GUI-CIDER 的价值不只是提出一个训练 recipe,而是把 GUI agent 的研究焦点从“动作模仿”推进到“界面世界模型”。这对长期构建可靠 computer-use agent 非常关键。
8. 总结
GUI-CIDER 这篇论文给 GUI agent 领域提供了一个清晰信号:如果我们希望 agent 在真实软件环境中稳定工作,就不能只让它记住更多操作轨迹,而要让它理解界面元素、动作效果和任务流程之间的因果关系。
它的三阶段方法——数据合成、样本重选、mid-training——把 GUI 轨迹转化为可内化的世界知识,并在多个知识和任务完成基准上取得提升。尤其是 8B 模型在 GUI Knowledge Bench 上接近 Claude-Sonnet-4.5 的结果,说明领域知识质量有时比参数规模更能决定 GUI agent 的表现。
对 macOS 研发效率工具和桌面自动化产品来说,最值得借鉴的是:把日常操作轨迹沉淀成结构化、因果化、可筛选的知识资产。未来真正好用的 computer-use agent,可能不是那个“点得最快”的 agent,而是那个最懂软件世界如何运转、知道每一步为什么有效、也能在界面变化时迁移经验的 agent。