VeriGUI:GUI Agent 不该盲目行动,而要先确认动作真的生效
解析 ACL 2026 论文 Don’t Act Blindly:为什么 GUI Agent 容易在失败动作上死循环,以及 VeriGUI 如何用 TVAE、Robust SFT 和 GRPO 建立动作结果验证与自纠错能力。
目录
- 为什么这篇论文值得关注
- GUI Agent 的真实痛点:动作失败后还以为成功了
- VeriGUI 的核心思路:把“验证”放进每一步
- TVAE:Thinking、Verification、Action、Expectation 的闭环
- 训练方法:Robust SFT + GRPO
- 实验结果:不只是更准,而是更会恢复
- 对 macOS 研发效率工具和 GUI 自动化的启发
- 局限性与我的点评
- 总结
1. 为什么这篇论文值得关注
今天选的论文是 ACL 2026 Main Conference 的 Don’t Act Blindly: Robust GUI Automation via Action-Effect Verification and Self-Correction。
- 论文地址:https://arxiv.org/abs/2604.05477
- 作者:Yuzhe Zhang、Xianwei Xue、Xingyong Wu、Mengke Chen、Chen Liu、Xinran He、Run Shao、Feiran Liu、Huanmin Xu、Qiutong Pan、Haiwei Wang
- 机构:Beijing University of Technology、Baidu Inc.
- 核心贡献:提出 VeriGUI,让 GUI agent 在执行下一步前先验证上一步动作是否真的产生了预期效果,并在失败时进行诊断和恢复。
这篇论文有意思的地方在于,它没有继续只卷“点得准不准”“任务完成率高不高”,而是抓住了 GUI agent 在真实环境中非常常见、但 benchmark 里容易被掩盖的问题:agent 执行了一个动作,但界面没有变化,它却继续假设动作成功,最后陷入重复点击、重复输入、重复打开的循环。
如果你做过 mobile agent、web agent、desktop automation,应该会对这个问题很熟悉。一个按钮没点中、页面加载慢、动画还没结束、弹窗挡住目标、坐标偏了一点,agent 就可能在错误状态上继续规划。论文引用的一个统计很直观:在 1,265 次任务执行里,因重复无效动作导致的执行超时,占所有失败的 72.3%。
这说明 GUI agent 的下一阶段能力,不只是“看懂界面”和“生成动作”,还要具备一种更像人类的习惯:做完一步之后,看看世界是不是按预期变化了。
2. GUI Agent 的真实痛点:动作失败后还以为成功了
很多 GUI agent 的默认假设是确定性的:
看到屏幕 -> 规划动作 -> 执行动作 -> 默认动作成功 -> 进入下一步规划在离线数据集里,这个假设看起来还行。因为训练样本通常是一条成功轨迹,上一帧和下一帧之间的变化是干净的,agent 只需要学会从当前 screenshot 和 instruction 预测下一步 action。
但真实环境不是这样:
- 网络延迟会让页面迟迟不跳转;
- 渲染和动画会让目标位置变化;
- 系统弹窗、权限弹窗、登录状态会打断流程;
- click 坐标稍微偏一点,界面可能完全不变;
- 输入框没有聚焦,后续输入动作就会落空。
问题不在于“动作失败”本身。失败不可避免。真正的问题是:失败后,agent 是否知道自己失败了。
论文把这类问题称为一种很典型的 idempotent failure:错误动作没有造成状态变化,屏幕保持不变。对人来说,这个信号很明显:点了按钮但页面没动,就应该怀疑按钮没点中、网络慢、或目标选错了。但很多现有 agent 会继续沿着“我已经成功了”的内在叙事往下走,于是重复同一个动作,或者在错误状态上生成更错的动作。
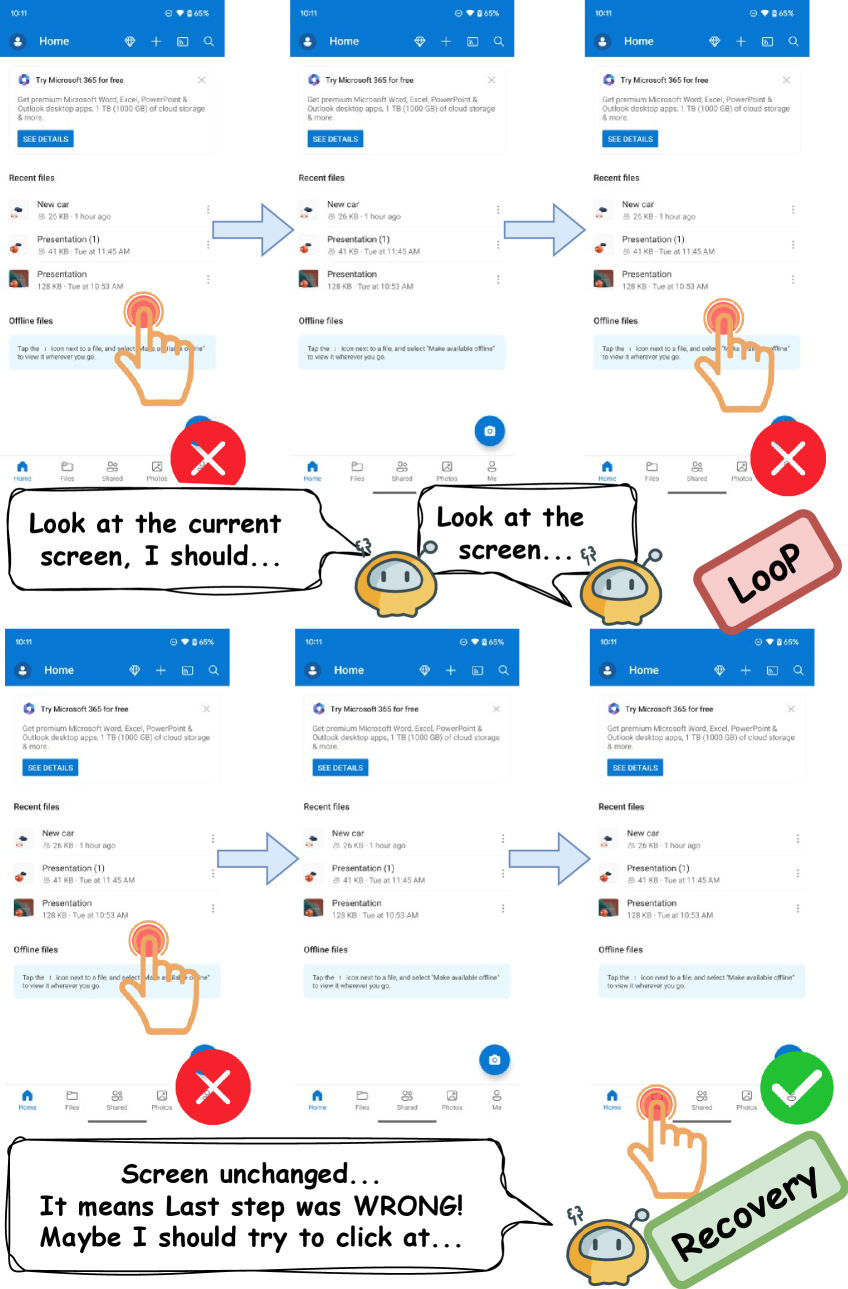
图 1 对比了两种行为模式:上面是“盲目动作”的 agent,失败后会反复尝试同一类无效动作;下面是 VeriGUI,它会把动作的预期效果拿来和当前屏幕对照,从而发现失败并切换到恢复逻辑。
3. VeriGUI 的核心思路:把“验证”放进每一步
VeriGUI 的设计目标可以用一句话概括:
GUI agent 不应该只预测下一步动作,还应该预测这一步动作会带来什么变化,并在下一帧验证这个变化是否真的发生。
这其实是把 GUI automation 从“动作生成问题”改写成了“动作—效果一致性问题”。
传统 agent 更关注:
当前屏幕 + 用户任务 -> 下一步 actionVeriGUI 关注的是:
当前屏幕 + 历史 + 上一步预期效果 -> 上一步是否成功 -> 为什么失败/成功 -> 下一步 action -> 下一步预期效果这带来一个关键变化:agent 内部开始维护一种“可被验证的承诺”。它不能只说“我要点提交按钮”,还要说“点完以后应该进入确认页/按钮高亮/列表刷新/弹窗消失”。下一步观察到新屏幕后,模型要先判断这个承诺是否兑现。
这对产品工程也很重要。因为很多 GUI 自动化系统失败时,日志里只有一串动作:click、type、scroll、click。你很难知道它到底从哪一步开始偏了。VeriGUI 这种显式 expected effect,可以天然变成更好的 trace:每一步都包含“我以为会发生什么”和“实际有没有发生”。
4. TVAE:Thinking、Verification、Action、Expectation 的闭环
论文提出的核心推理框架叫 TVAE:
- Thinking:结构化分析当前状态和历史;
- Verification:判断上一步动作是否成功,输出
SUCCESS或NO_CHANGE; - Action:生成下一步可执行 GUI 动作,例如 click、scroll、input_text;
- Expectation:预测执行这一步后,屏幕应该出现什么变化。
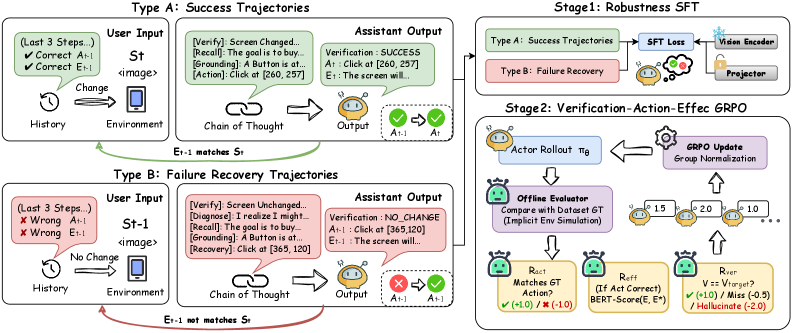
这里最关键的是,TVAE 不是一条单向链路,而是一个跨时间步闭环:
第 t 步生成的 Expectation
↓
第 t+1 步作为 Verification 的判断依据也就是说,Expectation_t 会变成下一步的验证假设。这个设计让 agent 没法轻易“忘掉”自己上一轮的承诺。
论文中还把 Thinking 做了结构化标签,例如:
[Verify]:检查上一步是否达到预期;[Recall]:回忆任务目标和历史步骤;[Grounding]:定位当前要操作的 UI 元素;[Action]:决定动作;- 失败恢复时使用
[Diagnose]和[Recovery]。
这点看起来像 prompt engineering,但它的价值不止是格式化输出。它把 GUI agent 的内部思考拆成了更可监督、更可奖励的模块。后续训练时,模型不仅要学动作,还要学会诚实地判断“我上一步是否真的成功”。
5. 训练方法:Robust SFT + GRPO
VeriGUI 的训练分两阶段。
5.1 Robust SFT:先让模型见过失败
普通 SFT 通常只喂成功轨迹。问题是,如果模型从未见过“动作声称执行了但屏幕没变化”的样本,它自然会学到一个乐观假设:历史里的动作都成功了。
VeriGUI 构造了两类样本:
| 类型 | 含义 | 训练目标 |
|---|---|---|
| Type A | 成功轨迹 | 判断 SUCCESS,继续执行下一步 |
| Type B | 合成失败恢复轨迹 | 屏幕保持不变,但历史声称动作已执行;模型要判断 NO_CHANGE 并给出恢复动作 |
Type B 的构造非常实用:把上一帧屏幕和“已经执行了某个动作”的历史拼在一起,就模拟出一种“动作失败但界面无变化”的场景。模型因此能在 SFT 阶段先学到基本的失败识别格式和恢复范式。
5.2 GRPO:用奖励强化“诚实验证”
SFT 只能让模型模仿失败恢复样本,但还不足以让它真正内化“不要自欺欺人”。第二阶段用 GRPO 做强化微调,奖励函数由三部分组成:
| 奖励 | 关注点 |
|---|---|
| Action Reward | 动作类型和坐标是否接近 ground truth |
| Effect Reward | 预测的 expected effect 是否语义一致 |
| Verification Reward | 对上一步成功/失败的判断是否符合视觉现实 |
其中最有意思的是 Verification Reward 的非对称惩罚:
- 判断正确:
+1.0 - 漏报失败,即 False Negative:
-0.5 - 把失败幻认为成功,即 False Positive:
-2.0
这个设计很工程化。因为在 GUI 自动化里,“不确定/承认失败”通常还可以恢复;但“明明失败了却说成功”,会让后续所有动作建立在错误状态上,错误会不断累积。所以论文用更重的惩罚逼模型对视觉现实保持诚实。
6. 实验结果:不只是更准,而是更会恢复
论文在 AndroidControl-High、AITW-Gen、GUI Odyssey 等离线 benchmark,以及 MiniWoB++、AndroidWorld 等在线环境上做了实验。这里最值得看的不是单步准确率,而是鲁棒性指标。
论文构造了一个 Robustness Benchmark,引入两个指标:
| 指标 | 含义 |
|---|---|
| Loop Rate,LR | 失败后重复无效动作的比例,越低越好 |
| Recovery Success Rate,RSR | 失败后生成正确恢复动作的比例,越高越好 |
关键结果如下:
| 模型 | LR ↓ | RSR ↑ |
|---|---|---|
| Qwen2.5-VL-3B | 30.0 | 35.0 |
| UI-R1-3B | 29.5 | 29.0 |
| UI-TARS-7B | 13.4 | 45.5 |
| UI-S1-7B | 20.5 | 43.6 |
| VeriGUI-3B | 24.3 | 51.1 |
| VeriGUI-7B | 15.6 | 52.5 |
最醒目的结论是:VeriGUI-3B 的 RSR 达到 51.1%,超过了多个 7B 级开源模型;VeriGUI-7B 达到 52.5%,是表中最高。
这说明 TVAE 并不只是让输出更啰嗦,而是确实提升了“失败后恢复”的能力。UI-TARS-7B 的 Loop Rate 更低,但 RSR 低于 VeriGUI,说明它可能更少重复原动作,却不一定能给出正确替代动作。VeriGUI 的优势在于:它不只是意识到“不该继续原动作”,还更可能诊断原因并恢复。
论文的消融也很有信息量:
- 标准 SFT 提升了 step accuracy,但不提升验证能力,Loop Rate 甚至略升;
- 加入 Robust SFT 后,RSR 从 29.7% 提升到 45.5%;
- 再加入 GRPO 后,RSR 到 51.1%,ASO 从 2.25 降到 1.25,说明恢复更有效率。

图 3 展示了一个很典型的例子:base model 因坐标偏差打开应用失败,但它没有意识到失败,于是不断重复 open app;Robust SFT 后,模型开始能反思,但还有短循环;GRPO 后,模型能在一次失败后识别坐标问题,并换用更合适的恢复动作。
7. 对 macOS 研发效率工具和 GUI 自动化的启发
如果把这篇论文放到 macOS 研发效率工具、GUI 自动化、computer-use agent 的产品设计里,我觉得有几个直接启发。
7.1 每个动作都应该有 expected effect
很多自动化系统现在只记录动作:
{"action": "click", "target": "Run Button"}但更好的记录应该是:
{
"action": "click",
"target": "Run Button",
"expected_effect": "构建开始,状态栏出现 running/progress 状态"
}这样做之后,自动化不再是盲目的脚本执行,而变成带断言的交互过程。对于 IDE 自动化、CI 面板操作、App Store Connect、Jira/Linear、内部研发平台,这个差别非常大。
7.2 GUI agent 的 trace 应该显示“预期 vs 实际”
如果用户看到 agent 失败,只看到“点击了某按钮”是不够的。真正有用的是:
| 步骤 | 动作 | 预期 | 实际 | 判断 |
|---|---|---|---|---|
| 3 | 点击 Build | 出现构建进度 | 页面无变化 | NO_CHANGE |
| 4 | 重新定位按钮 | 找到右上角真实 Build 按钮 | 成功进入构建 | SUCCESS |
这会显著提升可调试性,也更适合做企业内的自动化审计。
7.3 macOS 场景里,验证信号可以更丰富
论文主要基于视觉 screenshot,但在 macOS 工具里,我们不必只看图。可以融合更多信号:
- Accessibility tree 是否变化;
- AppKit/AX focused element 是否变化;
- 菜单栏、窗口标题、bundle id 是否变化;
- 文件系统、剪贴板、进程状态是否变化;
- 网络请求或本地日志是否出现目标事件。
也就是说,VeriGUI 的思想可以扩展成:每个 GUI 动作都绑定一个多模态 effect verifier。视觉只是其中一种 verifier。
7.4 自动化产品要把“失败恢复”当成一等能力
传统 RPA 更像确定性脚本:失败就报错。GUI agent 更像半自主系统:失败后应该能解释、重试、换路径、或请求人类确认。
VeriGUI 说明,一个好的 computer-use agent 不应该只追求单步成功率,还要追求:
- 能否发现动作没有生效;
- 能否避免重复无效动作;
- 能否提出合理恢复策略;
- 能否把恢复过程写进 trace;
- 能否在不确定时停下来询问用户。
这对研发效率工具尤其重要。因为研发流程里的 GUI 操作往往有副作用:提交、发布、审批、合并、删除、上传。盲目继续比失败本身更危险。
8. 局限性与我的点评
这篇论文的方向我很认可,但也有几个需要注意的点。
第一,idempotent failure 是重要但不完整的失败模型。很多真实失败并不是“屏幕无变化”,而是变化到了错误页面、弹出了中间状态、或者局部状态变化但任务没有推进。VeriGUI 在在线 benchmark 上有效,说明它学到了一定通用自检习惯,但未来还需要更细粒度的 effect taxonomy。
第二,TVAE 会增加 token 和时延开销。论文也承认 per-step 成本增加,只是因为恢复减少了总步数,整体 trajectory overhead 可控。对于本地 GUI agent 产品,这意味着需要分层:高风险动作必须 TVAE,全量动作未必都要完整长推理。
第三,expected effect 的质量很关键。如果模型一开始就写了模糊预期,比如“页面会变化”,验证就很难严格。工程落地时,应该把 expected effect 写成可检测断言,例如“窗口标题包含 X”“按钮从 disabled 变为 enabled”“列表新增一行”。
第四,视觉验证不应独占。在 macOS / desktop 场景,Accessibility、进程、文件、日志、网络事件都能成为更稳定的验证信号。相比纯 VLM,系统级 agent 有机会做得更可靠。
我的总体判断是:VeriGUI 代表了 GUI agent 从“动作生成器”走向“闭环执行器”的一个重要趋势。下一阶段的 GUI 自动化不只是更强的 VLM,而是更强的 execution monitor。
9. 总结
这篇论文的核心观点很简单,但很关键:不要盲目行动。
GUI agent 在真实环境中失败并不可怕,可怕的是失败后还继续相信自己成功了。VeriGUI 通过 TVAE 把“动作预期效果”显式写出来,再在下一步验证它是否发生;通过 Robust SFT 让模型见过失败;通过带非对称惩罚的 GRPO 让模型学会诚实面对视觉现实。
对工程落地来说,我最想带走的是三句话:
- 每个 GUI 动作都应该带 expected effect;
- 每个 expected effect 都应该被验证;
- 每次验证失败都应该进入可解释的恢复流程,而不是重复原动作。
这也是 computer-use agent 真正进入研发工作流、桌面自动化和复杂业务系统之前,必须补上的一块能力。
参考链接
- 论文:Don’t Act Blindly: Robust GUI Automation via Action-Effect Verification and Self-Correction
- HTML 版本:https://arxiv.org/html/2604.05477
- 相关背景:UI-TARS、Qwen2.5-VL、AndroidControl-High、MiniWoB++、AndroidWorld